Hadoop生态圈-Kafka的旧API实现生产者-消费者
Hadoop生态圈-Kafka的旧API实现生产者-消费者
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.旧API实现生产者-消费者
1>.开启kafka集群
[yinzhengjie@s101 ~]$ more `which xkafka.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -ne ];then
echo "无效参数,用法为: $0 {start|stop}"
exit
fi #获取用户输入的命令
cmd=$ for (( i= ; i<= ; i++ )) ; do
tput setaf
echo ========== s$i $cmd ================
tput setaf
case $cmd in
start)
ssh s$i "source /etc/profile ; kafka-server-start.sh -daemon /soft/kafka/config/server.properties"
echo s$i "服务已启动"
;;
stop)
ssh s$i "source /etc/profile ; kafka-server-stop.sh"
echo s$i "服务已停止"
;;
*)
echo "无效参数,用法为: $0 {start|stop}"
exit
;;
esac
done [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more `which xkafka.sh`
[yinzhengjie@s101 ~]$ xkafka.sh start
========== s102 start ================
s102 服务已启动
========== s103 start ================
s103 服务已启动
========== s104 start ================
s104 服务已启动
[yinzhengjie@s101 ~]$
开启kafka集群([yinzhengjie@s101 ~]$ xkafka.sh start)
[yinzhengjie@s101 ~]$ xcall.sh jps
============= s101 jps ============
Jps
命令执行成功
============= s102 jps ============
QuorumPeerMain
Kafka
Jps
命令执行成功
============= s103 jps ============
Jps
QuorumPeerMain
Kafka
命令执行成功
============= s104 jps ============
Jps
QuorumPeerMain
Kafka
命令执行成功
============= s105 jps ============
Jps
命令执行成功
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more `which xcall.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt ];then
echo "请输入参数"
exit
fi #获取用户输入的命令
cmd=$@ for (( i=;i<=;i++ ))
do
#使终端变绿色
tput setaf
echo ============= s$i $cmd ============
#使终端变回原来的颜色,即白灰色
tput setaf
#远程执行命令
ssh s$i $cmd
#判断命令是否执行成功
if [ $? == ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 ~]$
检查kafka是否正常启动([yinzhengjie@s101 ~]$ xcall.sh jps)
2>.编写生产者端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.kafka; import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties; public class TestProducer { public static void main(String[] args) throws Exception {
//初始化Java的Properties属性
Properties props = new Properties();
//通过metadata.broker.list参数设置代理,其value对应的kafka服务器地址,如果有多个就用逗号(",")分隔。
props.put("metadata.broker.list", "s102:9092, s103:9092, s104:9092");
//指定message的数据类型,将传输的数据都序列化成字符串(String),当然还有很多序列化方式(LongEncoder,NullEncoder,DefalutEmcoder,IntegerEncoder),比如默认为字节类型等等。
props.put("serializer.class", "kafka.serializer.StringEncoder");
//包装java的prop,包装成ProducerConfig
ProducerConfig config = new ProducerConfig(props);
//使用producerConfig初始化producer
//<String, String> 中第一个为key类型(未接触到),第二个是value类型,真实数据
Producer<String, String> producer = new Producer<String, String>(config);
//定义kafka的主题
String topic = "yinzhengjie";
for (int i = 1000; i < 2000; i++) {
KeyedMessage<String, String> data = new KeyedMessage<String, String>(topic, "BigData" + i);
producer.send(data);
Thread.sleep(500);
}
producer.close();
}
}
运行以上代码,并在Linux中断启用KafKa的消费者,截图如下:
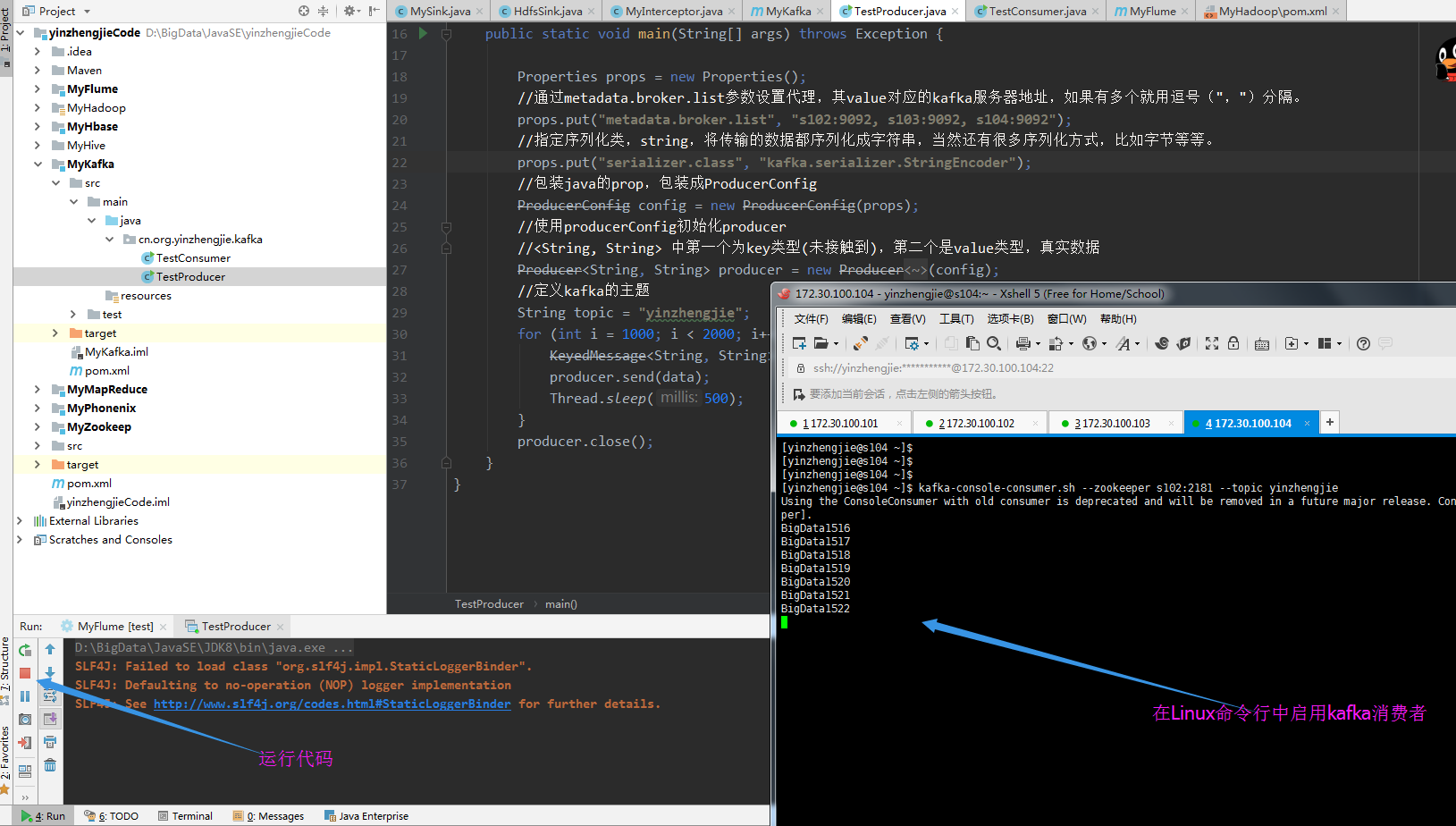
3>.编写消费者端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.kafka; import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector; public class TestConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("zookeeper.connect", "s102:2181,s103:2181,s104:2181");
//设置组id名称
props.put("group.id", "yzj");
//ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大
props.put("zookeeper.session.timeout.ms", "500");
//定义ZooKeeper集群中leader和follower之间的同步时间
props.put("zookeeper.sync.time.ms", "250");
//consumer向zookeeper提交offset的频率,单位是毫秒
props.put("auto.commit.interval.ms", "1000");
//把props封装成一个ConsumerConfig对象
ConsumerConfig conf = new ConsumerConfig(props);
//创建出一个ConsumerConnector实例
ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(conf);
//定义一个集合,这个集合最终被被传入到consumer.createMessageStreams()方法中。
Map<String, Integer> topicMap = new HashMap<String, Integer>();
//topicMap中指定第一个参数是主题,第二个参数是指定线程个数。
topicMap.put("yinzhengjie", new Integer(1));
//通过consumer和topic获取到数据流,在Map中的第一个参数是:topic,第二个参数是:消息列表
Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreamsMap = consumer.createMessageStreams(topicMap);
//通过topic返回所有消息列表
List<KafkaStream<byte[], byte[]>> streamList = consumerStreamsMap.get("yinzhengjie");
//迭代所有list,通过迭代器获取消息流中的k-v
for (final KafkaStream<byte[], byte[]> stream : streamList) {
ConsumerIterator<byte[], byte[]> consumerIte = stream.iterator();
while (consumerIte.hasNext())
System.out.println("Message from Single Topic :: "+ new String(consumerIte.next().message()));
}
}
}
在Linux端启动生产者并运行以上代码,输出结果如下:
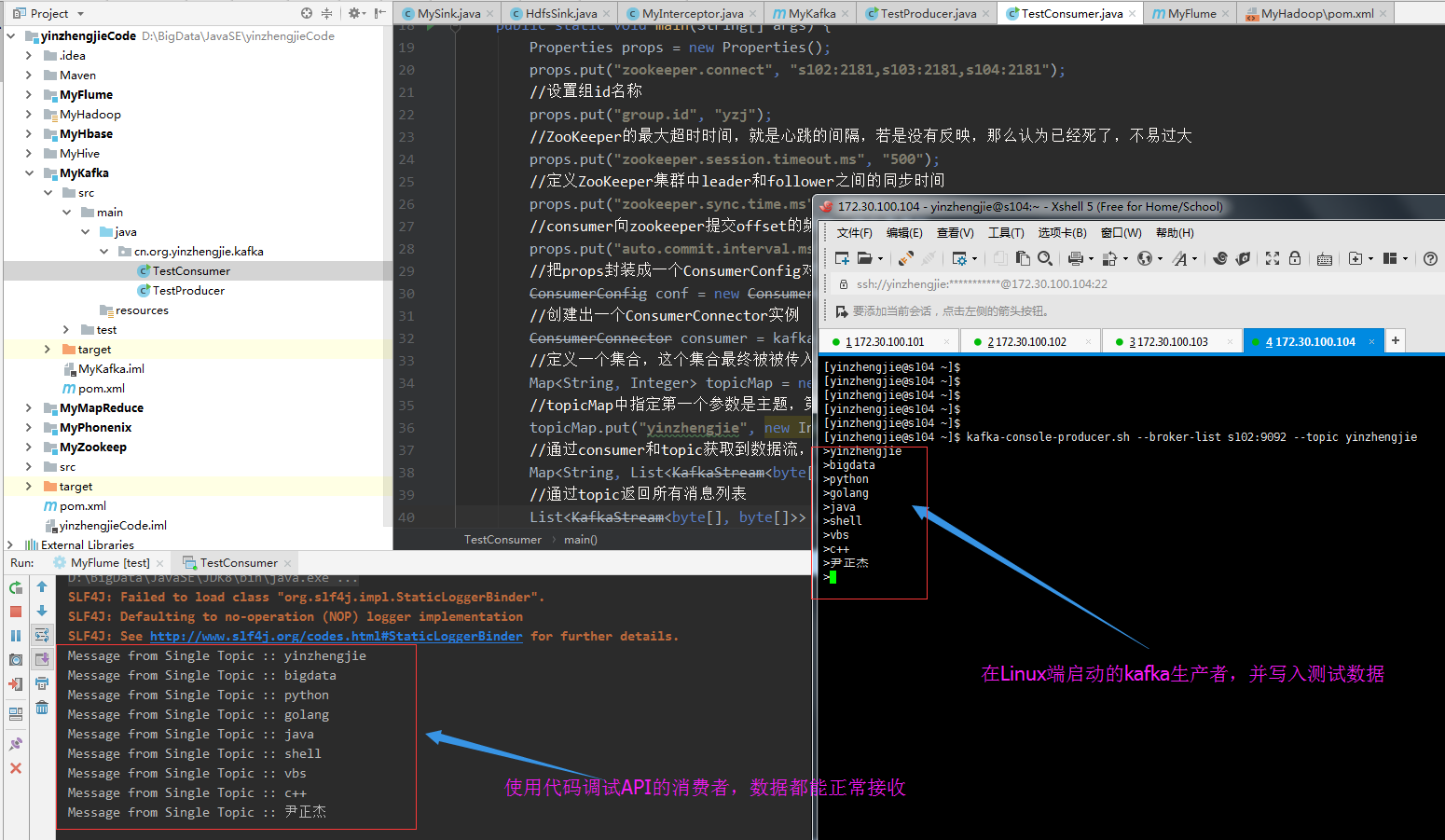
二.kafka的producer和Consumer配置(实战重点,调优手段)
1>.kafka的producer配置
>.metadata.broker.list
答:kafka服务器地址,如果有多个就用逗号(",")分隔。
>.serializer.class
答:指定message的数据类型。
>.key.serializer.class
答:指定key的数据类型,key的作用,用作选择分区。默认kafka.serializer.DefaultEncoder(byte[]),常用的还有
"kafka.serializer.NullEncoder","kafka.serializer.NullEncoder","kafka.serializer.StringEncoder","kafka.serializer.IntegerEncoder"
"kafka.serializer.LongEncoder"。 >.producer.type
答:指定消息应该如何发送。比如async和sync。
//async 异步,将数据发在缓冲区,一并发送给broker,无序 100000条数据:3792
//sync 同步,正常发送,有序 100000条数据:31939ms >.batch.num.messages
答:指定异步发送中一个批次含有多少条数据,默认200,超过此值就会发送。
>.queue.buffer.max.ms
答:队列的毫秒数,到达此值数据也会发送。 >.request.required.acks
答:获取回值,有三种回值方式(并对着三种方式处理100000条数据的所用时间):
//0意味着 producer不等待broker的回执,适用于最低延迟,不保证数据的完整性(3559)
//1意味着 只接收分区中的leader回执(4421)
//-1意味着 接收所有in-sync状态下的节点回执(6792) >.partitioner.class
答:指定分区函数类。 >.compression.codec
答:指定压缩编解码器none, gzip, and snappy.
2>.kafka的Consumer配置
重复消费的手段:
设置从头消费 //--from-beginning
//auto.offset.reset = smallest
手动控制消费偏移量 //通过修改zk数据 consumer/groupid/offsets/topic/partition >.group.id
答:指定消费者组id,没有指定会自动创建。 >.consumer.id
答:指定消费者的id,没有指定会自动创建。 >.zookeeper.connect
答:指定zookeeper客户端地址。 >.client.id
答:指定自己的客户端id,没有指定会和group.id一样。 >.zookeeper.session.timeout.ms
答:zk会话超时则抛异常。 >.zookeeper.connection.timeout.ms
答:zk连接超时则抛异常。 >.zookeeper.sync.time.ms
答:控制zk同步数据的时间。 >.auto.commit.enable
答:自动提交消息的偏移量到zk。
>.auto.commit.interval.ms
答:自动提交偏移量的间隔。 >.auto.offset.reset
答:设置从哪里读取数据
//largest 读取最新数据
//smallest 读取zk中偏移量的数据 >.consumer.timeout.ms
答:consumer超时抛异常,并关闭连接
3>.以上部分参数测试代码如下
三.
Hadoop生态圈-Kafka的旧API实现生产者-消费者的更多相关文章
- Hadoop生态圈-Kafka的新API实现生产者-消费者
Hadoop生态圈-Kafka的新API实现生产者-消费者 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Kafka的完全分布式部署
Hadoop生态圈-Kafka的完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要内容就是搭建Kafka完全分布式,它是在kafka本地模式(https:/ ...
- Hadoop生态圈-Kafka的本地模式部署
Hadoop生态圈-Kafka的本地模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Kafka简介 1>.什么是JMS 答:在Java中有一个角消息系统的东西,我 ...
- Hadoop生态圈-kafka事务控制以及性能测试
Hadoop生态圈-kafka事务控制以及性能测试 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Kafka配置文件详解
Hadoop生态圈-Kafka配置文件详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.默认kafka配置文件内容([yinzhengjie@s101 ~]$ more /s ...
- Hadoop生态圈-使用phoenix的API进行JDBC编程
Hadoop生态圈-使用phoenix的API进行JDBC编程 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop日记Day15---MapReduce新旧api的比较
我使用hadoop的是hadoop1.1.2,而很多公司也在使用hadoop0.2x版本,因此市面上的hadoop资料版本不一,为了扩充自己的知识面,MapReduce的新旧api进行了比较研究. h ...
- 使用Win32 API实现生产者消费者线程同步
使用win32 API创建线程,创建信号量用于线程的同步 创建信号量 语法例如以下 HANDLE semophore; semophore = CreateSemaphore(lpSemaphoreA ...
- Hadoop生态圈-Kafka常用命令总结
Hadoop生态圈-Kafka常用命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.管理Kafka服务的命令 1>.开启kafka服务 [yinzhengjie@s ...
随机推荐
- 蓝牙inquiry流程之HCI_Inquiry_Result_With_RSSI和HCI Extended Inquiry Result处理
首先介绍一下和inquiry的相关的流程. inquiry是从协议栈下发的一个HCI命令.其格式如下: 这里简单介绍下第二个参数,是inquiry的持续时间, 从上图看出 inquiry持续的时间是 ...
- [CF1060E]Sergey and Subway[树dp]
题意 给出 \(n\) 个点的树,求 \(\sum_{i=1}^n{\sum_{j=i}^n{\lceil \frac{dis(i,j)}{2} \rceil}}\) . \(n\leq 2 \tim ...
- Yeoman的好基友:Grunt
grunt介绍 前端不能承受之痛 1.这是我们的生活 文件压缩:YUI Compressor.Google Closure 文件合并:fiddler + qzmin 文件校验:jshint 雪碧图:c ...
- Jenkins报表 代码 指标分析
Jenkins报表 这表现在前面的章节中,也有可用最简单的一种是适用于 JUnit 测试报告的许多报表插件. 在生成后动作进行任何工作,你可以定义要创建的报告. 该构建已经完成,测试结果选项将可进一步 ...
- 华为笔试——C++字符串四则运算的实现
题目:字符串四则运算的实现 有字符串表示的一个四则运算表达式,要求计算出该表达式的正确数值.四则运算即:加减乘除"+-*/",另外该表达式中的数字只能是1位(数值范围0~9),运算 ...
- webug4.0安装
官网:https://www.webug.org/ 官方版本里安装视频教程 4.26 官网打不开,分享当初存在网盘的 链接:https://pan.baidu.com/s/13rG0TLwuA3Ro0 ...
- 通过拓展Function.prototype实现一个AOP
AOP(面向切面的编程)主要是将一些与核心业务逻辑模块无关的功能抽离出来,这些功能通常包括日志统计,安全控制,或者是异常处理等等. 我们要做的就是拓展Function.prototype来“动态植入” ...
- Visual Studio的安装应用及单元测试
新建项目—Visual C#—类库 一.Visual Studio的安装 这可能是自己安装软件用的的最长时间的一次 ..刚下载完安装的时候灰常的尴尬,因为2013版本和2015的版本都是不支持在win ...
- 软件工程作业 - Week 1
构建之法读后疑问: 初步的完成构建程序设计思路之后实现过程中发现了问题或者可以优化的地方是立马就改进还是完成之后按照步骤统一进行优化. 覆盖性测试,针对一些永远用不到只是用来预防极为极端的情况下,例如 ...
- java词频统计——web版支持
需求概要: 1.把程序迁移到web平台,通过用户上传TXT的方式接收文件. 2.用户直接输入要统计的文本,服务器返回结果 3.在页面上给出链接 (如果有封皮.作者.字数.页数等信息更佳)或表格,展示经 ...