python3入门教程
|
python : 3.5 jdk : 1.7 eclipse : 4.5.2(有点低了,需要对应Neon 4.6,不然总是会弹出提示框) |
应该学习最新版本的 Python 3 还是旧版本的 Python 2.7?
MySqlDB官网只支持Python3.4,这里Python3.5使用第三方库PyMysql连接Mysql数据库。
http://dev.mysql.com/downloads/connector/python/2.0.html

PyMysql下载地址:
https://pypi.python.org/pypi/PyMySQL#downloads
Windows下安装方法:
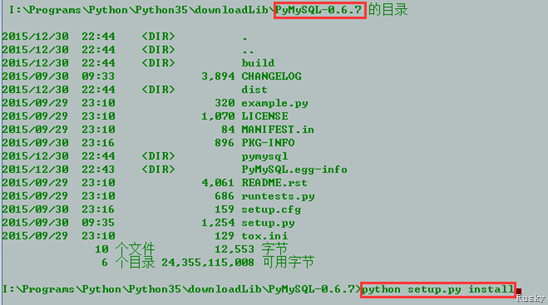
下载解压后,进入PyMySql-0.6.7目录,执行python setup.py install安装
test1.py
import urllib.request as request
def baidu_tieba(url, begin_page, end_page):
for i in range(begin_page, end_page + 1):
sName = 'D:/360Downloads/test/'+str(i).zfill(5)+'.html'
print('正在下载第'+str(i)+'个页面, 并保存为'+sName)
m = request.urlopen(url+str(i)).read()
with open(sName,'wb') as file:
file.write(m)
file.close()
if __name__ == "__main__":
url = "http://tieba.baidu.com/p/"
begin_page = 1
end_page = 3
baidu_tieba(url, begin_page, end_page)
test2.py
import urllib.request as request
import re
import os
import urllib.error as error
def baidu_tieba(url, begin_page, end_page):
count = 1
for i in range(begin_page, end_page + 1):
sName = 'D:/360Downloads/test/' + str(i).zfill(5) + '.html'
print('正在下载第' + str(i) + '个页面, 并保存为' + sName)
m = request.urlopen(url + str(i)).read()
# 创建目录保存每个网页上的图片
dirpath = 'D:/360Downloads/test/'
dirname = str(i)
new_path = os.path.join(dirpath, dirname)
if not os.path.isdir(new_path):
os.makedirs(new_path)
page_data = m.decode('gbk', 'ignore')
page_image = re.compile('<img src=\"(.+?)\"')
for image in page_image.findall(page_data):
pattern = re.compile(r'^http://.*.png$')
if pattern.match(image):
try:
image_data = request.urlopen(image).read()
image_path = dirpath + dirname + '/' + str(count) + '.png'
count += 1
print(image_path)
with open(image_path, 'wb') as image_file:
image_file.write(image_data)
image_file.close()
except error.URLError as e:
print('Download failed')
with open(sName, 'wb') as file:
file.write(m)
file.close()
if __name__ == "__main__":
url = "http://tieba.baidu.com/p/"
begin_page = 1
end_page = 3
baidu_tieba(url, begin_page, end_page)
test3.py
#python3.4 爬虫教程
#爬取网站上的图片
#林炳文Evankaka(博客:http://blog.csdn.net/evankaka/)
import urllib.request
import socket
import re
import sys
import os
targetDir = r"D:\PythonWorkPlace\load" #文件保存路径
def destFile(path):
if not os.path.isdir(targetDir):
os.makedirs(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:])
print(t)
return t
if __name__ == "__main__": #程序运行入口
weburl = "http://www.douban.com/"
webheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req = urllib.request.Request(url=weburl, headers=webheaders) #构造请求报头
webpage = urllib.request.urlopen(req) #发送请求报头
contentBytes = webpage.read()
for link, t in set(re.findall(r'(https:[^\s]*?(jpg|png|gif))', str(contentBytes))): #正则表达式查找所有的图片
print(link)
try:
urllib.request.urlretrieve(link, destFile(link)) #下载图片
except:
print('失败') #异常抛出
test4.py
'''
第一个示例:简单的网页爬虫 爬取豆瓣首页
''' import urllib.request #网址
url = "http://bj.58.com/caishui/28707491160259x.shtml?adtype=1&entinfo=28707491160259_0&adact=3&psid=156713756196890928513274724" #请求
request = urllib.request.Request(url) #爬取结果
response = urllib.request.urlopen(request) data = response.read() #设置解码方式
data = data.decode('utf-8') #打印结果
print(data) #打印爬取网页的各类信息 # print(type(response))
# print(response.geturl())
# print(response.info())
# print(response.getcode())
test5.py
#!/usr/bin/env python
#-*-coding: utf-8 -*-
import re
import urllib.request as request
from bs4 import BeautifulSoup as bs
import csv
import os
import sys
from imp import reload
reload(sys) def GetAllLink():
num = int(input("爬取多少页:>"))
if not os.path.exists('./data/'):
os.mkdir('./data/') for i in range(num):
if i+1 == 1:
url = 'http://nj.58.com/piao/'
GetPage(url, i)
else:
url = 'http://nj.58.com/piao/pn%s/' %(i+1)
GetPage(url, i) def GetPage(url, num):
Url = url
user_agent = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:32.0) Gecko/20100101 Firefox/32.0'
headers = { 'User-Agent' : user_agent }
req = request.Request(Url, headers = headers)
page = request.urlopen(req).read().decode('utf-8')
soup = bs(page, "html.parser")
table = soup.table
tag = table.find_all('tr')
# 提取出所需的那段
soup2 = bs(str(tag), "html.parser")
title = soup2.find_all('a','t') #标题与url
price = soup2.find_all('b', 'pri') #价格
fixedprice = soup2.find_all('del') #原价
date = soup2.find_all('span','pr25') #时间 atitle = []
ahref = []
aprice = []
afixedprice = []
adate = [] for i in title:
#print i.get_text(), i.get('href')
atitle.append(i.get_text())
ahref.append(i.get('href'))
for i in price:
#print i.get_text()
aprice.append(i.get_text())
for i in fixedprice:
#print j.get_text()
afixedprice.append(i.get_text())
for i in date:
#print i.get_text()
adate.append(i.get_text()) csvfile = open('./data/ticket_%s.csv'%num, 'w')
writer = csv.writer(csvfile)
writer.writerow(['标题','url','售价','原价','演出时间'])
'''
每个字段必有title,但是不一定有时间date
如果没有date日期,我们就设为'---'
'''
if len(atitle) > len(adate):
for i in range(len(atitle) - len(adate)):
adate.append('---')
for i in range(len(atitle) - len(afixedprice)):
afixedprice.append('---')
for i in range(len(atitle) - len(aprice)):
aprice.append('---') for i in range(len(atitle)):
message = atitle[i]+'|'+ahref[i]+'|'+aprice[i]+ '|'+afixedprice[i]+'|'+ adate[i]
writer.writerow([i for i in str(message).split('|')])
print ("[Result]:> 页面 %s 信息保存完毕!"%(num+1))
csvfile.close() if __name__ == '__main__':
GetAllLink()
test6.py
#!/usr/bin/env python
#-*-coding: utf-8 -*-
import urllib.request as request
from bs4 import BeautifulSoup as bs
import sys
from imp import reload
reload(sys) def GetAllLink():
num = int(input("爬取多少页:>")) for i in range(num):
if i+1 == 1:
url = 'http://bj.58.com/caishui/?key=%E4%BB%A3%E7%90%86%E8%AE%B0%E8%B4%A6%E5%85%AC%E5%8F%B8&cmcskey=%E4%BB%A3%E7%90%86%E8%AE%B0%E8%B4%A6%E5%85%AC%E5%8F%B8&final=1&jump=1&specialtype=gls'
GetPage(url, i)
else:
url = 'http://bj.58.com/caishui/pn%s/'%(i+1)+'?key=%E4%BB%A3%E7%90%86%E8%AE%B0%E8%B4%A6%E5%85%AC%E5%8F%B8&cmcskey=%E4%BB%A3%E7%90%86%E8%AE%B0%E8%B4%A6%E5%85%AC%E5%8F%B8&final=1&specialtype=gls&PGTID=0d30215f-0000-1941-5161-367b7a641048&ClickID=4'
GetPage(url, i) def GetPage(url, num):
Url = url
user_agent = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:32.0) Gecko/20100101 Firefox/32.0'
headers = { 'User-Agent' : user_agent }
req = request.Request(Url, headers = headers)
page = request.urlopen(req).read().decode('utf-8')
soup = bs(page, "html.parser")
table = soup.table
tag = table.find_all('tr') # 提取出所需的那段
soup2 = bs(str(tag), "html.parser") title = soup2.find_all('a','t') #标题与url
companyName = soup2.find_all('a','sellername') #公司名称 atitle = []
ahref = []
acompanyName = [] for i in title:
atitle.append(i.get_text())
ahref.append(i.get('href'))
for i in companyName:
acompanyName.append(i.get_text())
for i in range(len(ahref)):
getSonPage(str(ahref[i])) def getSonPage(url):
Url = url
user_agent = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:32.0) Gecko/20100101 Firefox/32.0'
headers = { 'User-Agent' : user_agent }
req = request.Request(Url, headers = headers)
page = request.urlopen(req).read().decode('utf-8')
soup = bs(page, "html.parser")
print("=========================")
#类别
print(soup.find('div','su_con').get_text())
#服务区域
print(soup.find('div','su_con quyuline').get_text())
#联 系 人
print(soup.find_all('ul','suUl')[0].find_all('li')[2].find_all('a')[0].get_text())
#商家地址
print(soup.find_all('ul','suUl')[0].find_all('li')[3].find('div','su_con').get_text().replace("\n",'').replace("\r",'').replace('\t','').replace(' ',''))
#服务项目
print(soup.find('article','description_con').get_text().replace("_____________________________________","\n\r").replace("___________________________________","\n\r").replace("(以下为公司北京区域分布图)",""))
print("=========================") if __name__ == '__main__':
GetAllLink()
test7.py
import pymysql
conn = pymysql.connect(host='192.168.1.102', port=3306,user='root',passwd='',db='test',charset='UTF8')
cur = conn.cursor()
cur.execute("select version()")
for i in cur:
print(i)
cur.close()
conn.close()
python3入门教程的更多相关文章
- python3入门教程(一)之 hello world
概述 python 这门语言这几年非常的火,很多技术都用的到,像爬虫,大数据,人工智能等,包括很多的小孩都首选python作为入门学习语言,那python 究竟是怎样一门语言呢? Python 是一个 ...
- python3入门教程(二)操作数据库(一)
概述 最近在准备写一个爬虫的练手项目,基本想法是把某新闻网站的内容分类爬取下来,保存至数据库,再通过接口对外输出(提供后台查询接口).那么问题就来了,python到底是怎么去操作数据库的呢?我们今天就 ...
- 【django入门教程】Django的安装和入门
很多初学django的朋友,都不知道如何安装django开发以及django的入门,今天小编就给大家讲讲django入门教程. 注明:python版本为3.3.1.Django版本为1.5.1,操作系 ...
- Python入门教程(1)
人生苦短,我用Python! Python(英语发音:/ˈpaɪθən/), 是一种面向对象.解释型计算机程序设计语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于19 ...
- Python 3.6.3 官网 下载 安装 测试 入门教程 (windows)
1. 官网下载 Python 3.6.3 访问 Python 官网 https://www.python.org/ 点击 Downloads => Python 3.6.3 下载 Python ...
- Python爬虫入门教程 37-100 云沃客项目外包网数据爬虫 scrapy
爬前叨叨 2019年开始了,今年计划写一整年的博客呢~,第一篇博客写一下 一个外包网站的爬虫,万一你从这个外包网站弄点外快呢,呵呵哒 数据分析 官方网址为 https://www.clouderwor ...
- Python爬虫入门教程 36-100 酷安网全站应用爬虫 scrapy
爬前叨叨 2018年就要结束了,还有4天,就要开始写2019年的教程了,没啥感动的,一年就这么过去了,今天要爬取一个网站叫做酷安,是一个应用商店,大家可以尝试从手机APP爬取,不过爬取APP的博客,我 ...
- 2018-06-20 中文代码示例视频演示Python入门教程第三章 简介Python
知乎原链 Python 3.6.5官方入门教程中示例代码汉化后演示 对应在线文档: 3. An Informal Introduction to Python 不知如何合集, 请指教. 中文代码示例P ...
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
随机推荐
- ThinkPHP5分页样式设置
手册上讲分页类的使用时对样式讲的不够详细,这里我结合个人的摸索给大家一些参考意见. config里的分页配置我使用的是系统默认的bootstrap,查看thinkphp\library\think\p ...
- Linux:回收循环创建的多个线程
上午我说了循环创建多个线程,由于进程与线程是如此的相似,进程我们知道要回收,那么线程也自然要回收啦.我们接着看控制原语: 线程与共享 线程间共享全局变量! [牢记]:线程默认共享数据段.代码段等地址空 ...
- B树、B-树、B+树、B*树的定义和区分
MySQL是基于B+树聚集索引组织表 B树 即二叉搜索树: 1.所有非叶子结点至多拥有两个儿子(Left和Right): 2.所有结点存储一个关键字: 3.非叶子结点的左指针指向小于其关键字的子树,右 ...
- git reset 版本回退
git log 查看所有提交信息. commit 67692318180bed6b2a17db0708cfbe0231e33db3 (HEAD -> master) Author: kingBo ...
- LeetCode OJ 60. Permutation Sequence
题目 The set [1,2,3,-,n] contains a total of n! unique permutations. By listing and labeling all of th ...
- FBackup:个人用途与商业用途都是免费的
當自己在備份電腦資料時,若沒有使用備份及還原軟體時,我想很多人的作法就是「想到應該要備份了,然後進行備份檔案的壓縮.壓縮好之後複製到不同的磁碟機或燒錄光碟」,等要用的時候,再拿出來還原.若是這樣,其實 ...
- 第五次Scrum冲刺
第五次Scrum冲刺 1.成员今日完成情况 队员 今日完成任务 刘佳 前端初步构建 李佳 后端设计初级阶段 周世元 数据设计 杨小妮 博客编写 许燕婷 管理团队当日及次日任务 陈水莲 测试矩阵用例设计 ...
- Html - Table 表头固定和 tbody 设置 height 在IE不起作用的解决
原文地址,转载请注明出处:http://www.cnblogs.com/jying/p/6294063.html 做项目的时候发现给 tbody设置 height 和 overflow-y 在IE下不 ...
- 用JS和JQ来获取子节点!
用JS和JQ来获取子节点! 在JS中,如果通过document.getElementsByTagName来获取子元素有个弊端:它不单会获取符合要求的子元素,就连同孙元素也会获取.如果有特殊要求,那 ...
- 如何解决Android Studio解决DDMS真机/模拟器无法查看data目录问题
android app开发中,文件.SharedPreference或数据库默认保存在/data文件夹下,有时需要查看该文件夹下数据文件是否创建成功时,发现竟然打不开data目录: 具体解决方式如下: ...