深度拾遗(01) - 梯度爆炸/梯度消失/Batch Normal
什么是梯度爆炸/梯度消失?
深度神经网络训练的时候,采用的是反向传播方式,该方式使用链式求导,计算每层梯度的时候会涉及一些连乘操作,因此如果网络过深。
那么如果连乘的因子大部分小于1,最后乘积的结果可能趋于0,也就是梯度消失,后面的网络层的参数不发生变化.
那么如果连乘的因子大部分大于1,最后乘积可能趋于无穷,这就是梯度爆炸

如何防止梯度消失?
sigmoid容易发生,更换激活函数为 ReLU即可。
权重初始化用高斯初始化
如何防止梯度爆炸?
1 设置梯度剪切阈值,如果超过了该阈值,直接将梯度置为该值。
2 使用ReLU,maxout等替代sigmoid
区别:
- sigmoid函数值在[0,1],ReLU函数值在[0,+无穷],所以sigmoid函数可以描述概率,ReLU适合用来描述实数;
- sigmoid函数的梯度随着x的增大或减小和消失,而ReLU不会。
- Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
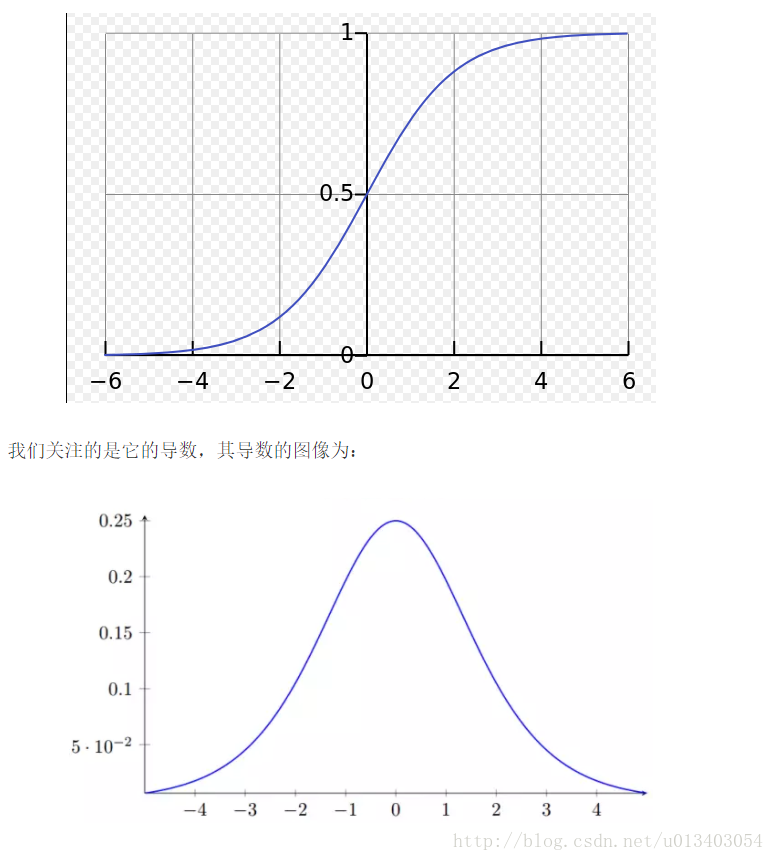
sigmoid导数最大为1/4
a的数值变化范围很小,若x数值仅在[-4,4]窄范围内会出现梯度消失,若大于4则梯度爆炸。
对于sigmoid更容易出现梯度消失。
Battch Normal
ref
解决了梯度消失与加速收敛(数据本身在0均值处)和internal covariate shift(内部神经元分布的改变) 数据分布不一致问题。
传统的深度神经网络在训练是,每一层的输入的分布都在改变,因此训练困难,只能选择用一个很小的学习速率,但是每一层用了BN后,可以有效的解决这个问题,学习速率可以增大很多倍.
 通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。
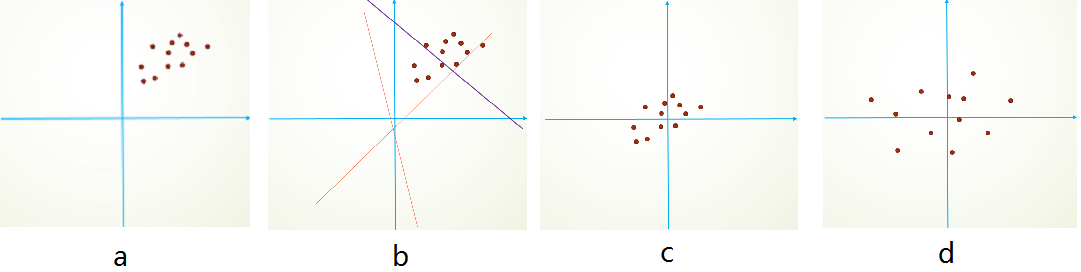
通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。初始化的时候,我们的参数一般都是0均值的,因此开始的拟合y=Wx+b,基本过原点附近,如图b红色虚线。因此,网络需要经过多次学习才能逐步达到如紫色实线的拟合,即收敛的比较慢。如果我们对输入数据先作减均值操作,如图c,显然可以加快学习。更进一步的,我们对数据再进行去相关操作,使得数据更加容易区分,这样又会加快训练,如图d。 通过把梯度映射到一个值大但次优的变化位置来阻止梯度过小变化。
- 统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。
covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有\(x\in \mathcal{X},P_s(Y|X=x)=P_t(Y|X=x)\),但是\(P_s(X)\ne P_t(X)\).
对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
因此至少0均值1方差的数据集可以减少样本分布的变化问题 使用BN训练时,一个样本只与minibatch中其他样本有相互关系;对于同一个训练样本,网络的输出会发生变化。这些效果有助于提升网络泛化能力,像dropout一样防止网络过拟合,同时BN的使用,可以减少或者去掉dropout类似的策略。
BN(Batch Normalization)层的作用
- 加速收敛
- 控制过拟合,可以少用或不用Dropout和正则
- 降低网络对初始化权重敏感
- 允许使用较大的学习率
在每一层输入的时候,加个BN预处理操作。BN应作用在非线性映射前,即对x=Wu+b做规范化。在BN中,是通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。可以说是一种更有效的local response normalization方法
PS:
Batch Norm会忽略图像像素(或者特征)之间的绝对差异(因为均值归零,方差归一),而只考虑相对差异,所以在不需要绝对差异的任务中(比如分类),有锦上添花的效果。而对于图像超分辨率这种需要利用绝对差异的任务,Batch Norm只会添乱。
深度拾遗(01) - 梯度爆炸/梯度消失/Batch Normal的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.10_1.12/梯度消失/梯度爆炸/权重初始化
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.10 梯度消失和梯度爆炸 当训练神经网络,尤其是深度神经网络时,经常会出现的问题是梯度消失或者梯度爆炸,也就是说当你训练深度网络时,导数或坡 ...
- 梯度消失&&梯度爆炸
转载自: https://blog.csdn.net/qq_25737169/article/details/78847691 前言 本文主要深入介绍深度学习中的梯度消失和梯度爆炸的问题以及解决方案. ...
- 梯度消失、梯度爆炸以及Kaggle房价预测
梯度消失.梯度爆炸以及Kaggle房价预测 梯度消失和梯度爆炸 考虑到环境因素的其他问题 Kaggle房价预测 梯度消失和梯度爆炸 深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸( ...
- L14梯度消失、梯度爆炸
梯度消失.梯度爆炸以及Kaggle房价预测 梯度消失和梯度爆炸 考虑到环境因素的其他问题 Kaggle房价预测 梯度消失和梯度爆炸 深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸( ...
- L8梯度消失、梯度爆炸
houseprices数据下载: 链接:https://pan.baidu.com/s/1-szkkAALzzJJmCLlJ1aXGQ 提取码:9n9k 梯度消失.梯度爆炸以及Kaggle房价预测 代 ...
- 机器学习 —— 基础整理(八)循环神经网络的BPTT算法步骤整理;梯度消失与梯度爆炸
网上有很多Simple RNN的BPTT(Backpropagation through time,随时间反向传播)算法推导.下面用自己的记号整理一下. 我之前有个习惯是用下标表示样本序号,这里不能再 ...
- 梯度消失(vanishing gradient)与梯度爆炸(exploding gradient)问题
(1)梯度不稳定问题: 什么是梯度不稳定问题:深度神经网络中的梯度不稳定性,前面层中的梯度或会消失,或会爆炸. 原因:前面层上的梯度是来自于后面层上梯度的乘乘积.当存在过多的层次时,就出现了内在本质上 ...
- DL基础补全计划(五)---数值稳定性及参数初始化(梯度消失、梯度爆炸)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 梯度消失(vanishing gradient)和梯度爆炸(exploding gradient)
转自https://blog.csdn.net/guoyunfei20/article/details/78283043 神经网络中梯度不稳定的根本原因:在于前层上的梯度的计算来自于后层上梯度的乘积( ...
随机推荐
- nagios的安装
Nagios通常由一个主程序(Nagios).一个插件程序(Nagios-plugins)和四个可选的ADDON(NRPE.NSCA. NSClient++和NDOUtils)组成.Nagios的监控 ...
- awk脚本使用的几种方法
1. awk名包含在文件内 [root@nhserver1 08]# cat sample.txtaaabbbccc [root@nhserver1 08]# cat readsample.awkaw ...
- 解读TCP 四种定时器
TCP 是提供可靠的传输层,它使用的方法之一就是确认从另一端收到的数据.但是数据和确认都可能会丢失.TCP 通过在发送时设置一个定时器来解决这个问题.如果当定时器溢出时还没收到确认,它就会重传该数据. ...
- 谈一谈jQuery核心架构设计(转)
jQuery对于大家而言并不陌生,因此关于它是什么以及它的作用,在这里我就不多言了,而本篇文章的目的是想通过对源码简单的分析来讨论 jQuery 的核心架构设计,以及jQuery 是如何利用javas ...
- 利用rsync+inotify实现数据实时同步脚本文件
将代码放在Server端,实现其它web服务器同步.首先创建rsync.shell,rsync.shell代码如下: #!/bin/bash host1=133.96.7.100 host2=133. ...
- Halcon一日一练:图像、变量实时更新
某些场合,我们需要刷新图像来识别图像处理过程的差异性,便于调试判断问题和预测.Halcon提供了图像刷新操作,这些操作不会改变程序的最终处理结果. 例程: **实时刷新图像 dev_update_wi ...
- Swing小技巧总结
1. 使JDialog位于屏幕的中央 public void setToScreenCenter(JDialog jd) { Dimension screenSize = Tool ...
- 洛谷 [P2483] [模板] k短路
人生中的第一道黑题... 其实就是k短路模板 #include <iostream> #include <cstdio> #include <cstring> #i ...
- vuex是什么东西?
vuex是什么鬼? 文档上面对vuex的解释是 "一个专为 Vue.js 应用程序开发的状态管理模式",恩,看完这句是否对vuex有了一个大概的认识? 答案是:"认识你个 ...
- [Swift]UIKit学习之警告框:UIAlertController和UIAlertView
Important: UIAlertView is deprecated in iOS 8. (Note that UIAlertViewDelegate is also deprecated.) T ...