每天几分钟跟小猫学前端之node系列:用node实现最简单的爬虫
先来段求分小视频:
https://www.iesdouyin.com/share/video/6550631947750608142/?region=CN&mid=6550632036246555405&titleType=title×tamp=1525407578&utm_campaign=client_share&app=aweme&utm_medium=ios&iid=30176260384&utm_source=qq&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=aweme_ios&utm_campaign=client_share&uid=92735989673&did=30176260384
本文的教学视频地址:
https://v.qq.com/x/page/b0643tut4ze.html


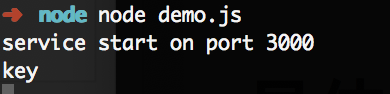
const request = require('request');
const app = express();
app.get('/:key',function(req,res){
console.log(req.params.key)
})
app.listen(3000,()=>{
console.log("service start on port 3000");
})
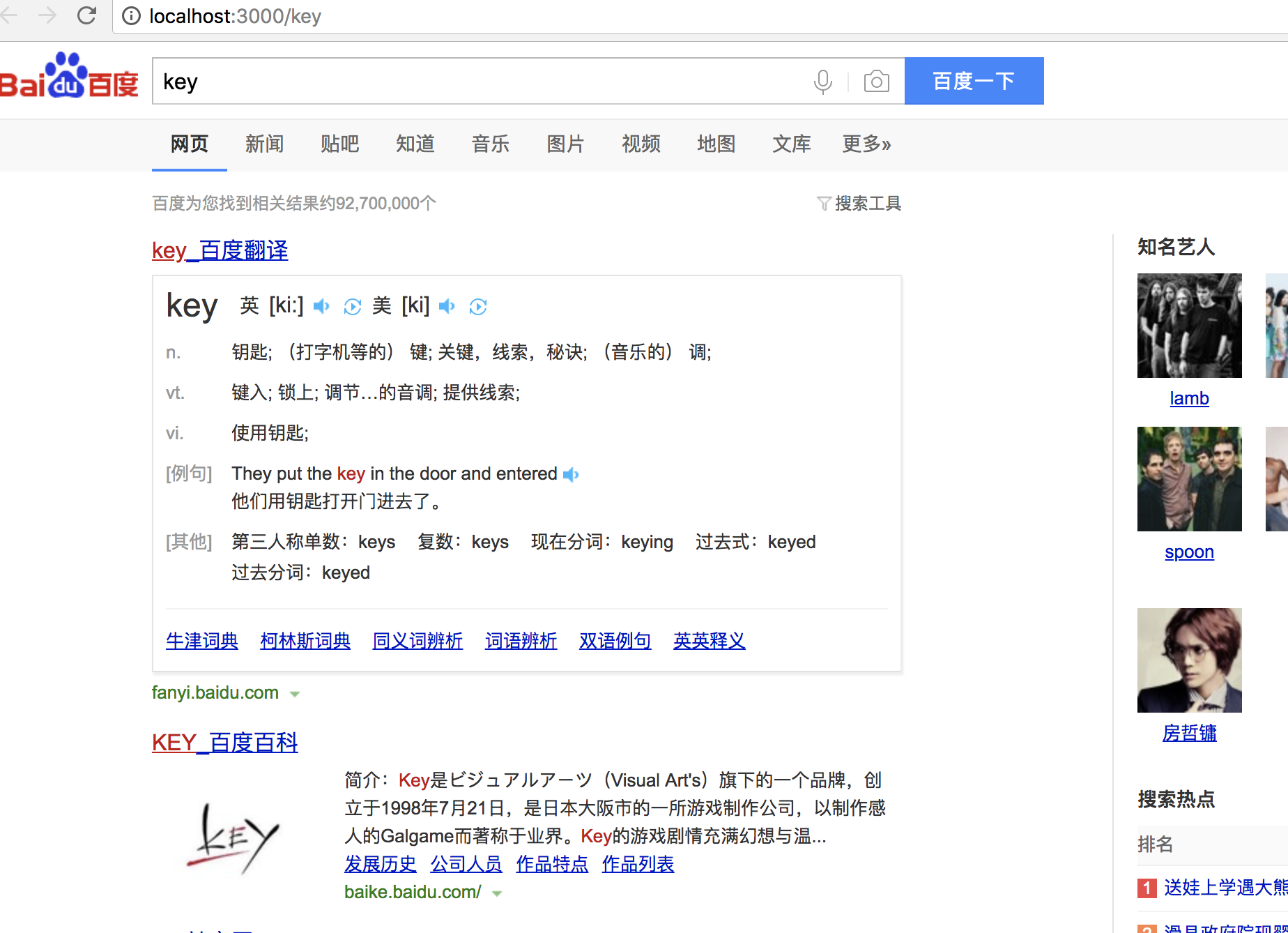
const express = require('express');
const request = require('request');
const app = express();
app.get('/:key',function(req,res){
console.log(req.params.key)
let spider = new Spider();
spider.fetch("http://www.baidu.com/s?wd="+req.params.key,(err,body)=>{
if(!err){
res.send(body.toString());
}
})
})
app.listen(3000,()=>{
console.log("service start on port 3000");
})
class Spider{
fetch(url,callback){
request({url: url, encoding : null}, (error, response, body)=>{
if (!error && response.statusCode === 200){
callback(null ,body);
}else{
callback(error ,'<body></body>');
}
});
}
}
const express = require('express');
const request = require('request');
const app = express();
const cheerio = require('cheerio');
app.get('/:key',function(req,res){
let spider = new Spider();
spider.fetch("http://www.baidu.com/s?wd="+req.params.key,(err,$)=>{
spider.fetchCallback(err,$,res)
})
console.log("http://www.baidu.com/s?wd="+req.params.key)
})
app.listen(3000,()=>{
console.log("service start on port 3000");
})
class Spider{
fetch(url,callback){
request({url: url, encoding : null}, (error, response, body)=>{
if (!error && response.statusCode === 200){
callback(null ,cheerio.load('<body>'+body+'</body>'));
}else{
callback(error ,cheerio.load('<body></body>'));
}
});
}
fetchCallback(err,$,res){
if(!err){
let keyList = [];
let table = $('body').find("#rs table").html();
res.send(table);
}
}
}
每天几分钟跟小猫学前端之node系列:用node实现最简单的爬虫的更多相关文章
- 只需几分钟跟小猫学前端(内含视频教程):nodejs基础之用express、ejs、mongdb建设简单的网站
开门见山视频教程 https://v.qq.com/x/page/d0645s79xrq.html 前 言: 这是小猫的第二篇node教程,第一篇教程是一个简单的试水,小猫的node教程面向对象为没有 ...
- 原生JS实现轮播+学前端的感受(防止走火入魔)
插件!插件!天天听到有人求这个插件,那个插件的,当然,用第三方插件可以大幅提高开发效率,但作为新手,我还是喜欢自己来实现,主要是我有时间! 今天我来给大家分享下用原生JS实现图片轮播的写法 前辈们可以 ...
- 重学前端 --- Promise里的代码为什么比setTimeout先执行?
首先通过一段代码进入讨论的主题 var r = new Promise(function(resolve, reject){ console.log("a"); resolve() ...
- ife 零基础学院 day 1 - 我为什么想学前端
与前端结缘 我是后端研发,毕业四年,用了四年C#,一开始写ASP.NET,有时会在asp页面写简单的js和html,做点css样式调整.当时的感触是前端调试太费劲了,因为没有js.html.css ...
- 结合jquery的前后端加密解密 适用于WebApi的SQL注入过滤器 Web.config中customErrors异常信息配置 ife2018 零基础学院 day 4 ife2018 零基础学院 day 3 ife 零基础学院 day 2 ife 零基础学院 day 1 - 我为什么想学前端
在一个正常的项目中,登录注册的密码是密文传输到后台服务端的,也就是说,首先前端js对密码做处理,随后再传递到服务端,服务端解密再加密传出到数据库里面.Dotnet已经提供了RSA算法的加解密类库,我们 ...
- 重学前端--js是面向对象还是基于对象?
重学前端-面向对象 跟着winter老师一起,重新认识前端的知识框架 js面向对象或基于对象编程 以前感觉这两个在本质上没有什么区别,面向对象和基于对象都是对一个抽象的对象拥有一系列的行为和状态,本质 ...
- 15分钟带你了解前端工程师必知的javascript设计模式(附详细思维导图和源码)
15分钟带你了解前端工程师必知的javascript设计模式(附详细思维导图和源码) 前言 设计模式是一个程序员进阶高级的必备技巧,也是评判一个工程师工作经验和能力的试金石.设计模式是程序员多年工作经 ...
- css与javascript重难点,学前端,基础不好一切白费!
JavaScript是一种属于网络的脚本语言,已经被广泛用于Web应用开发,常用来为网页添加各式各样的动态功能,为用户提供更流畅美观的浏览效果.通常JavaScript脚本是通过嵌入在HTML中来实现 ...
- 学前端的第一门语言HTML
学前端最终要做的就是制作各种各样的网页,html就相当于网页的骨架,所以我们学习前端的第一步就是先学html,接下来学习什么是html. 什么是HTML? HTML指的是超文本标记语言(Hyper T ...
随机推荐
- 使用Spring+Junit4.4进行测试
http://nottiansyf.iteye.com/blog/345819 使用Junit4.4测试 在类上的配置Annotation @RunWith(SpringJUnit4ClassRunn ...
- 3.QT中的debug相关的函数,以及文件锁的使用
1 新建项目T33Debug main.cpp #include <QDebug> #include <QFile> #include <QMutex> ...
- Dalvik虚拟机
Dalvik虚拟机是google专门为android平台开发的一个java虚拟机,但它并没有使用JVM规范.Dalvik虚拟机主要完成对象生命周期的管理.线程管理.安全和异常管理以及垃圾回收等重要功能 ...
- (一〇八)iPad开发之横竖屏适配
在iPad开发中,横竖屏的视图常常是不同的,例如侧边栏Dock,在横屏时用于屏幕较宽,可以展示足够多的内容,每个按钮都可以展示出标题:而竖屏时Dock应该比较窄,只显示图标不现实按钮标题. iPad比 ...
- Python 编程常见问题
Python 编程常见问题 经常使用Python编程,把经常遇到问题在这里记录一下,省得到网上查找,因此这篇文章会持续更新,需要的可以Mark一下.进入正题: 1.Python常用的文件头声明 #!/ ...
- pig读取部分列 (全部列中的少部分列)
pig流式数据,load数据时,不能读入任意列. 但是,可以从头读,只能连续几列.就是前几列.比如10列数据,可以只读前3列.但不能读第3列: 如:数据testdata [wizad@sr104 lm ...
- jdbc连接mysql加载驱动程序com.mysql.jdbc.Driver
在开发环境如eclipse,中加载指定数据库的驱动程序.需要下载MySQL支持JDBC的驱动程序mysql-connector-java-5.1.25-bin.jar. 而具体在Java程序中加载驱动 ...
- Gradle 1.12翻译——第二十章. 构建环境
有关其他已翻译的章节请关注Github上的项目:https://github.com/msdx/gradledoc/tree/1.12,或访问:http://gradledoc.qiniudn.com ...
- listview的工作原理
/** * Unsorted views that can be used by the adapter as a convert view. */ private ArrayList<View ...
- XBMC源代码分析 3:核心部分(core)-综述
前文分析了XBMC的整体结构以及皮肤部分: XBMC源代码分析 1:整体结构以及编译方法 XBMC源代码分析 2:Addons(皮肤Skin) 本文以及以后的文章主要分析XBMC的VC工程中的源代码. ...