pandas.DataFrame的pivot()和unstack()实现行转列
代码如下:
# -*- coding:utf-8 -*-
import pandas as pd
import MySQLdb
from warnings import filterwarnings
# 由于create table if not exists总会抛出warning,因此使用filterwarnings消除
filterwarnings('ignore', category = MySQLdb.Warning)
from sqlalchemy import create_engine
import sys
if sys.version_info.major<3:
reload(sys)
sys.setdefaultencoding("utf-8")
# 此脚本适用于python2和python3
host,port,user,passwd,db,charset="192.168.1.193",3306,"leo","mysql","test","utf8" def get_df():
global host,port,user,passwd,db,charset
conn_config={"host":host, "port":port, "user":user, "passwd":passwd, "db":db,"charset":charset}
conn = MySQLdb.connect(**conn_config)
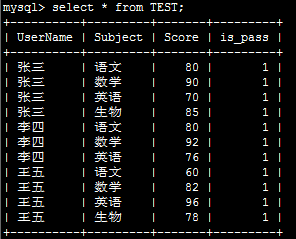
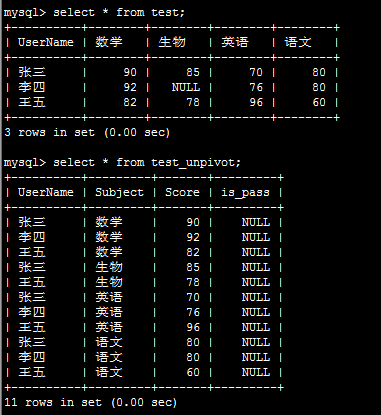
result_df=pd.read_sql('select UserName,Subject,Score from TEST',conn)
return result_df def pivot(result_df):
df_pivoted_init=result_df.pivot('UserName','Subject','Score')
df_pivoted = df_pivoted_init.reset_index() # 将行索引也作为DataFrame值的一部分,以方便存储数据库
return df_pivoted_init,df_pivoted
# 返回的两个DataFrame,一个是以姓名作index的,一个是以数字序列作index,前者用于unpivot,后者用于save_to_mysql def unpivot(df_pivoted_init):
# unpivot需要进行df_pivoted_init二维表格的行、列索引遍历,需要拼SQL因此不能使用save_to_mysql存数据,这里使用SQL和MySQLdb接口存
insert_sql="insert into test_unpivot(UserName,Subject,Score) values "
# 处理值为NaN的情况
df_pivoted_init=df_pivoted_init.fillna(0)
for col in df_pivoted_init.columns:
for index in df_pivoted_init.index:
value=df_pivoted_init.at[index,col]
if value!=0:
insert_sql=insert_sql+"('%s','%s',%s)" %(index,col,value)+','
insert_sql = insert_sql.strip(',')
global host, port, user, passwd, db, charset
conn_config = {"host": host, "port": port, "user": user, "passwd": passwd, "db": db, "charset": charset}
conn = MySQLdb.connect(**conn_config)
cur=conn.cursor()
cur.execute("create table if not exists test_unpivot like TEST")
cur.execute(insert_sql)
conn.commit()
conn.close() def save_to_mysql(df_pivoted,tablename):
global host, port, user, passwd, db, charset
"""
只有使用sqllite时才能指定con=connection实例,其他数据库需要使用sqlalchemy生成engine,engine的定义可以添加?来设置字符集和其他属性
"""
conn="mysql://%s:%s@%s:%d/%s?charset=%s" %(user,passwd,host,port,db,charset)
mysql_engine = create_engine(conn)
df_pivoted.to_sql(name=tablename, con=mysql_engine, if_exists='replace', index=False) # 从TEST表读取源数据至DataFrame结构
result_df=get_df()
# 将源数据行转列为二维表格形式
df_pivoted_init,df_pivoted=pivot(result_df)
# 将二维表格形式的数据存到新表test中
save_to_mysql(df_pivoted,'test')
# 将被行转列的数据unpivot,存入test_unpivot表中
unpivot(df_pivoted_init)
结果如下:
df=pd.DataFrame(np.random.randn(20).reshape(4,5),index=[['a','a','b','b'],[1,2,3,4]],columns=[10,20,30,40,50])
In [96]: df
Out[96]:
10 20 30 40 50
a 1 0.945775 0.768337 0.851630 -1.050475 -1.102554
2 -0.366129 0.353388 -0.722637 -0.056877 1.178270
b 3 0.885536 0.210911 2.067309 1.283721 -0.432906
4 0.173504 1.263630 1.264698 0.913879 1.156815
In [98]: df.stack()
Out[98]:
a 1 10 0.945775
20 0.768337
30 0.851630
40 -1.050475
50 -1.102554
2 10 -0.366129
20 0.353388
30 -0.722637
40 -0.056877
50 1.178270
b 3 10 0.885536
20 0.210911
30 2.067309
40 1.283721
50 -0.432906
4 10 0.173504
20 1.263630
30 1.264698
40 0.913879
50 1.156815
In [99]: df.stack().unstack()
Out[99]:
10 20 30 40 50
a 1 0.945775 0.768337 0.851630 -1.050475 -1.102554
2 -0.366129 0.353388 -0.722637 -0.056877 1.178270
b 3 0.885536 0.210911 2.067309 1.283721 -0.432906
4 0.173504 1.263630 1.264698 0.913879 1.156815
以上利用了Pandas的层次化索引,实际上这也是层次化索引一个主要的用途,结合本例我们可以把代码改成如下:
result_df=pd.read_sql('select UserName,Subject,Score from TEST',conn)
# 在从数据库中获取的数据格式是这样的:
UserName Subject Score
0 张三 语文 80.0
1 张三 数学 90.0
2 张三 英语 70.0
3 张三 生物 85.0
4 李四 语文 80.0
5 李四 数学 92.0
6 李四 英语 76.0
7 王五 语文 60.0
8 王五 数学 82.0
9 王五 英语 96.0
10 王五 生物 78.0
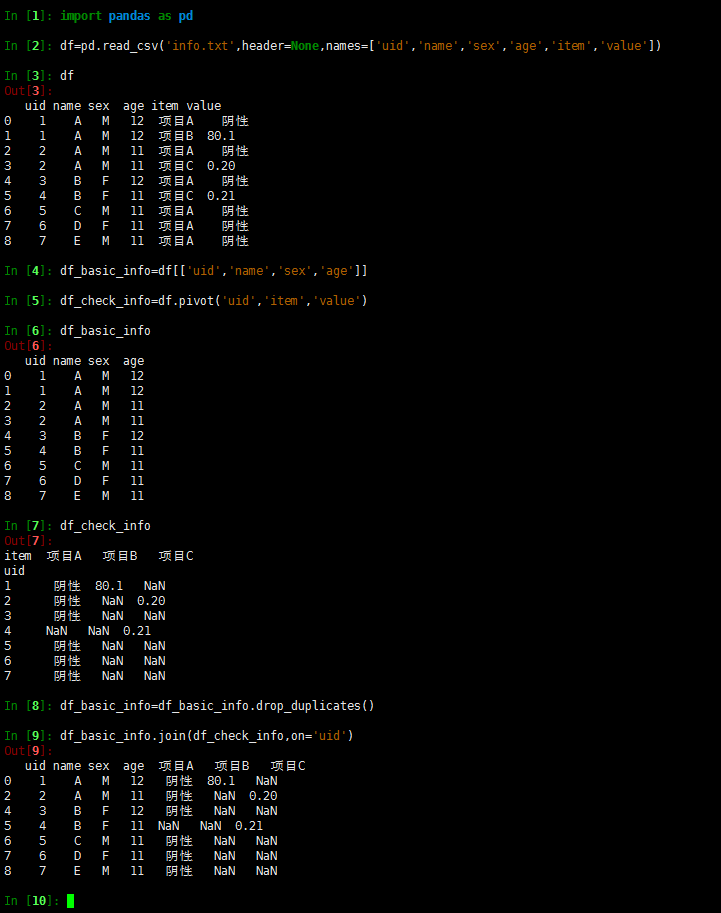
# 如果要使用层次化索引,那么我们只需要把UserName和Subject列设置为层次化索引,Score为其对应的值即可,我们借用set_index()函数:
df=result_df.set_index(['UserName','Subject'])
In [112]: df.unstack()
Out[112]:
Score
Subject 数学 生物 英语 语文
UserName
张三 90.0 85.0 70.0 80.0
李四 92.0 NaN 76.0 80.0
王五 82.0 78.0 96.0 60.0
# 使用stack可以将unstack的结果转回来,这样就也在形式上实现了行列互转,之后的操作基本一致了。
pandas.DataFrame的pivot()和unstack()实现行转列的更多相关文章
- [译]如何根据条件从pandas DataFrame中删除不需要的行?
问题来源:https://stackoverflow.com/questions/13851535/how-to-delete-rows-from-a-pandas-dataframe-based-o ...
- SqlServer 行转列,列转行 以及PIVOT函数快速实现行转列,UNPIVOT实现列转行
一 .列转行 创建所需的数据 CREATE TABLE [StudentScores]( [UserName] NVARCHAR(20), --学生姓名 [Subject] NVARCHAR(3 ...
- SqlServer PIVOT函数快速实现行转列,UNPIVOT实现列转行
我们在写Sql语句的时候没经常会遇到将查询结果行转列,列转行的需求,拼接sql字符串,然后使用sp_executesql执行sql字符串是比较常规的一种做法.但是这样做实现起来非常复杂,而在SqlSe ...
- SqlServer PIVOT函数快速实现行转列,UNPIVOT实现列转行(转)
我们在写Sql语句的时候没经常会遇到将查询结果行转列,列转行的需求,拼接sql字符串,然后使用sp_executesql执行sql字符串是比较常规的一种做法.但是这样做实现起来非常复杂,而在SqlSe ...
- [MSSQL]採用pivot函数实现动态行转列
环境要求:2005+ 在日常需求中常常会有行转列的事情需求处理.假设不是动态的行,那么我们能够採取case when 罗列处理. 在sql 2005曾经处理动态行或列的时候,通常採用拼接字符串的方法处 ...
- pandas DataFrame(4)-向量化运算
pandas DataFrame进行向量化运算时,是根据行和列的索引值进行计算的,而不是行和列的位置: 1. 行和列索引一致: import pandas as pd df1 = pd.DataFra ...
- SQL Server 2008 R2——PIVOT 行转列 以及聚合函数的选择
==================================声明================================== 本文原创,转载在正文中显要的注明作者和出处,并保证文章的完 ...
- Oracle 行转列pivot 、列转行unpivot 的Sql语句总结
这个比较简单,用||或concat函数可以实现 select concat(id,username) str from app_user select id||username str from ap ...
- sqlserver 行转列、字符串行转列、自动生产行转列脚本
行转列,老生常谈的问题.这里总结一下网上的方法. 1.生成测试数据: CREATE TABLE human( name ), --姓名 norm ), --指标 score INT , --分数 gr ...
随机推荐
- Fundebug微信小程序错误监控插件更新至1.1.0,新增test()与notifyHttpError()方法
摘要: 1.1.0新增fundebug.test()和fundebug.notifyHttpError()方法,同时大小压缩至15K. Fundebug是专业的小程序BUG监控服务,可以第一时间为您捕 ...
- Redis的知识点总结~Linux系统操作~
Redis_启动后杂项基础 Redis一共16个数据库 SELECT[0~15] 来切换数据库 命令起效返回1 不起效返回0 或者nil 或者error 异常... DBSIZE 查询数据的数 KEY ...
- bug生命周期&bug跟踪处理
一.BUG BUG:软件的缺陷 1.BUG的定义:----与软件测试的目的对应 软件的BUG,狭义概念是指软件程序的漏洞或缺陷,广义概念除此之外还包括测试工程师或用户所发现和提出的软件可改进的细节.或 ...
- 不可思议的纯 CSS 滚动进度条效果
结论先行,如何使用 CSS 实现下述滚动条效果? 就是顶部黄色的滚动进度条,随着页面的滚动进度而变化长短. 在继续阅读下文之前,你可以先缓一缓.尝试思考一下上面的效果或者动手尝试一下,不借助 JS , ...
- 百度APP移动端网络深度优化实践分享(二):网络连接优化篇
本文由百度技术团队“蔡锐”原创发表于“百度App技术”公众号,原题为<百度App网络深度优化系列<二>连接优化>,感谢原作者的无私分享. 一.前言 在<百度APP移动端网 ...
- Tampermonkey还你一个干净整洁的上网体验
作为一个前端开发,平时难免要经常浏览一些博客.技术网站,学习新的技术或者寻找解决方案,可能更多是ctrl+c和ctrl+v(^_^|||),但是目前很多网站的布局以及广告对于我们阅读文章造成了很多的障 ...
- MappedByteBuffer
计算机内存管理 原文链接 https://www.cnblogs.com/guozp/p/10470431.html MMC:CPU的内存管理单元. 物理内存:即内存条的内存空间. 虚拟内存:计算机系 ...
- [intellij IDEA]导入eclipse项目
1.因为最近eclipse在更新代码时经常卡死,就想将eclipse的项目迁移到idea.特意写下自己的经验,给迁移时遇到困难的朋友一些帮助 File -> new ->project f ...
- python接口自动化(十一)--发送post【data】(详解)
简介 前面登录博客园的是传 json 参数,由于其登录机制的改变没办法演示,然而在工作中有些登录不是传 json 的,如 jenkins 的登录,这里小编就以jenkins 登录为案例,传 data ...
- Spring之旅第一篇-初识Spring
一.概述 只要用框架开发java,一定躲不过spring,Spring是一个轻量级的Java开源框架,存在的目的是用于构建轻量级的J2EE应用.Spring的核心是控制反转(IOC)和面向切面编程(A ...