Elasticsearch介绍及安装部署
本节内容:
- Elasticsearch介绍
- Elasticsearch集群安装部署
- Elasticsearch优化
- 安装插件:中文分词器ik
一、Elasticsearch介绍
Elasticsearch是一个分布式搜索服务,提供Restful API,底层基于Lucene,采用多shard的方式保证数据安全,并且提供自动resharding的功能,加之github等大型的站点也采用 Elasticsearch作为其搜索服务。
二、Elasticsearch集群安装部署
1. 环境信息
| 主机名 | 操作系统版本 | IP地址 | 安装软件 |
| log1 | CentOS 7.0 | 114.55.29.86 | JDK1.7、elasticsearch-2.2.3 |
| log2 | CentOS 7.0 | 114.55.29.241 | JDK1.7、elasticsearch-2.2.3 |
| log3 | CentOS 7.0 | 114.55.253.15 | JDK1.7、elasticsearch-2.2.3 |
2. 安装JDK1.8
版本是Elasticsearch 2.2.3,官方建议jdk是1.8。3台机器都需要安装jdk1.8,添加新用户es。
[root@log1 local]# mkdir /usr/java
[root@log1 local]# tar zxf jdk-8u73-linux-x64.gz -C /usr/java/
安装JDK8
3. 添加用户
Elasticsearch不能使用root用户去启动。
[root@log1 local]# groupadd -g es
[root@log1 local]# useradd -g -u es
[root@log1 local]# echo "wisedu123" | passwd --stdin es &> /dev/null
添加Elasticsearch运行用户
用新创建的用户登录shell,配置PATH环境变量。
[es@log1 ~]$ vim ~/.bashrc
export JAVA_HOME=/usr/java/jdk1..0_73
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
[es@log1 ~]$ source ~/.bashrc
配置环境变量
# mkdir /usr/local/elasticsearch
# chown -R es.es elasticsearch
创建安装elasticsearch的目录
4. 下载安装elasticsearch
es用户登录shell,下载安装elasticsearch。
[es@log1 ~]$ cd /usr/local/elasticsearch/
[es@log1 elasticsearch]$ wget https://download.elasticsearch.org/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.2.3/elasticsearch-2.2.3.tar.gz
[es@log1 elasticsearch]$ tar zxf elasticsearch-2.2..tar.gz
[es@log1 elasticsearch]$ mv elasticsearch-2.2./* ./
[es@log1 elasticsearch]$ rm -rf elasticsearch-2.2.1
[es@log1 elasticsearch]$ rm -f elasticsearch-2.2.1.tar.gz
下载安装elasticsearch
5. 配置elasticsearch
(1)配置elasticsearch 堆内存,编辑bin/elasticsearch.in.sh
[es@log1 elasticsearch]$ vim bin/elasticsearch.in.sh
将参数:ES_MIN_MEM、ES_MAX_MEM设置为当前物理机内存的一半(注意单位,并保证两个值相等)

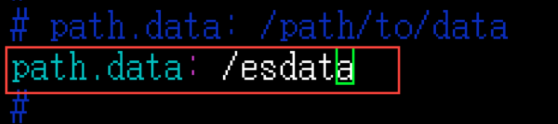
(2)配置Elasticsearch集群名称以及节点名称、是否为主节点、path data等信息
[es@log1 elasticsearch]$ vim config/elasticsearch.yml

(3)配置保护Elasticsearch使用的内存防止其被swapped
在memory section下,启用配置:bootstrap.mlockall: true

(4)配置network host

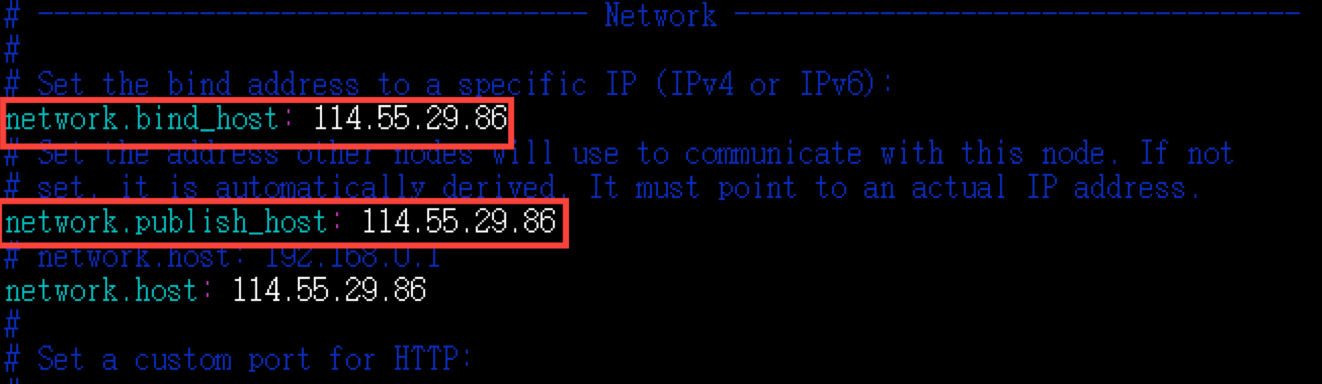
【注意】:另外,请在Network段在多加两个配置,内容如下:
network.bind_host: 114.55.29.86
# Set the address other nodes will use to communicate with this node. If not
# set, it is automatically derived. It must point to an actual IP address.
network.publish_host: 114.55.29.86
如果不加上如上的配置,程序在连接时会报错:
^A[-- ::08.791] [ERROR] [godseye] [godseye] [RMI TCP Connection()-127.0.0.1] [com.wisedu.godseye.search.util.SearchUtil] [buildIndex:] NoNodeAvailableException[None of the configured nodes are available: [{#transport#-}{114.55.29.86}{114.55.29.86:}]]
(5)配置Elasticsearch的自动发现机制

另外两台也是做如上的安装配置。只不过在配置中需要修改下面几处。


三、Elasticsearch优化
1. 检验配置中的bootstrap.mlockall: true是否生效
启动Elasticsearch:
[es@log1 elasticsearch]$ bin/elasticsearch -d
在shell终端执行命令:
curl http://114.55.29.86:9200/_nodes/process?pretty
关注这个这个请求返回数据中的mlockall的值,如果为false,则说明锁定内存失败,这可能由于运行elasticsearch的用户不具备这样的权限。解决该问题的方法是: 在运行elasticsearch之前,以root身份执行:
ulimit -l unlimited
然后再次重启elasticsearch。并查看上面的请求中的mlockall的值是否为true。
【注意】:这时候需要在root执行ulimit -l unlimited的shell终端上su - es,然后重启elasticsearch。因为这是命令行设置的ulimit -l unlimited,只对当前会话生效。
[root@log1 ~]# ulimit -l unlimited
[root@log1 ~]# su - es
[es@log1 ~]$ ps -ef|grep elasticsearch
[es@log1 ~]$ kill -
[es@log1 ~]$ /usr/local/elasticsearch/bin/elasticsearch -d
[es@log1 ~]$ curl http://114.55.29.86:9200/_nodes/process?pretty

如果仍然是false,可能是下面的原因:
Another possible reason why mlockall can fail is that the temporary directory (usually /tmp) is mounted with the noexec option. This can be solved by specifying a new temp directory, by starting Elasticsearch with:
./bin/elasticsearch -Djna.tmpdir=/path/to/new/dir
要想永久修改锁定内存大小无限制,需修改/etc/security/limits.conf,添加下面的内容,改完不需要重启系统,但是需要重新打开一个shell建立会话。
es - memlock -
其中,es代表运行elasticsearch的用户,-表示同时设置了soft和hard,memlock代表设置的是”锁定内存”这个类型,-1(unlimited或者infinity)代表没限制。
2. 配置操作系统文件描述符数
查看elasticsearch能打开的最大文件描述符个数:
curl http://114.55.29.86:9200/_nodes/stats/process?pretty
查看参数:max_file_descriptors。推荐设置到32K甚至64K。

或者输入下面的命令进行查看:
$ ulimit -a
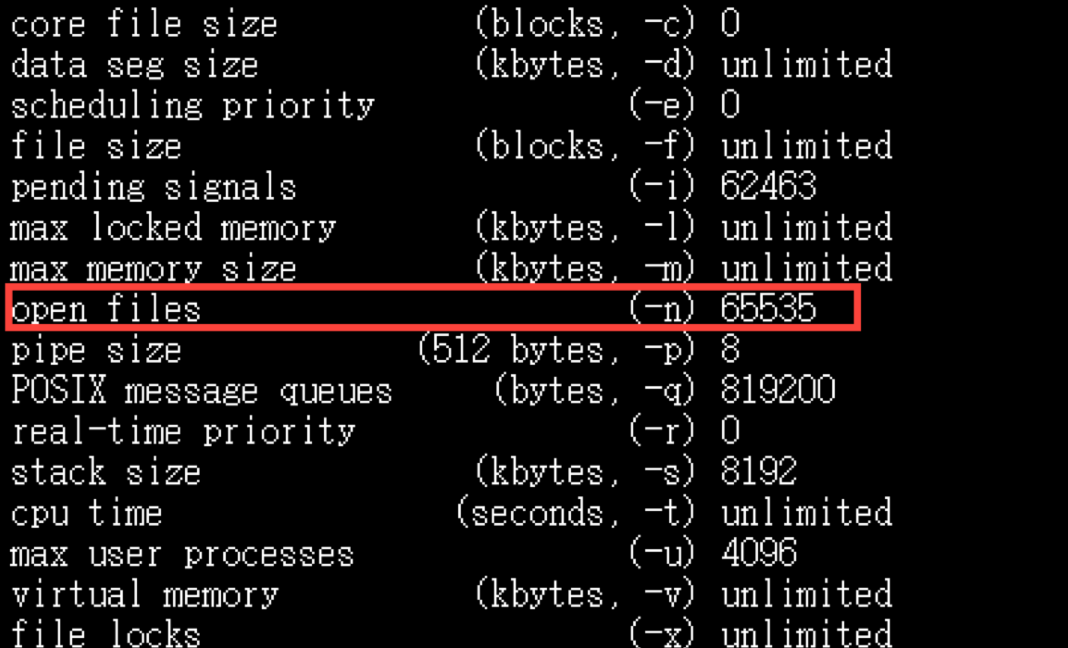
设置需要修改:
vim /etc/security/limits.conf
es - nofile
3. 增大虚拟内存mmap count配置
备注:如果你以.deb或.rpm包安装,则默认不需要设置此项,因为已经被自动设置,查看方式为:
sysctl vm.max_map_count
如果是手动安装,以root身份执行如下命令:
sysctl vm.max_map_count=
并修改文件使设置永久生效:
[root@log1 ~]# vim /etc/sysctl.conf
添加一行:
vm.max_map_count =
使生效:
[root@log1 ~]# sysctl -p
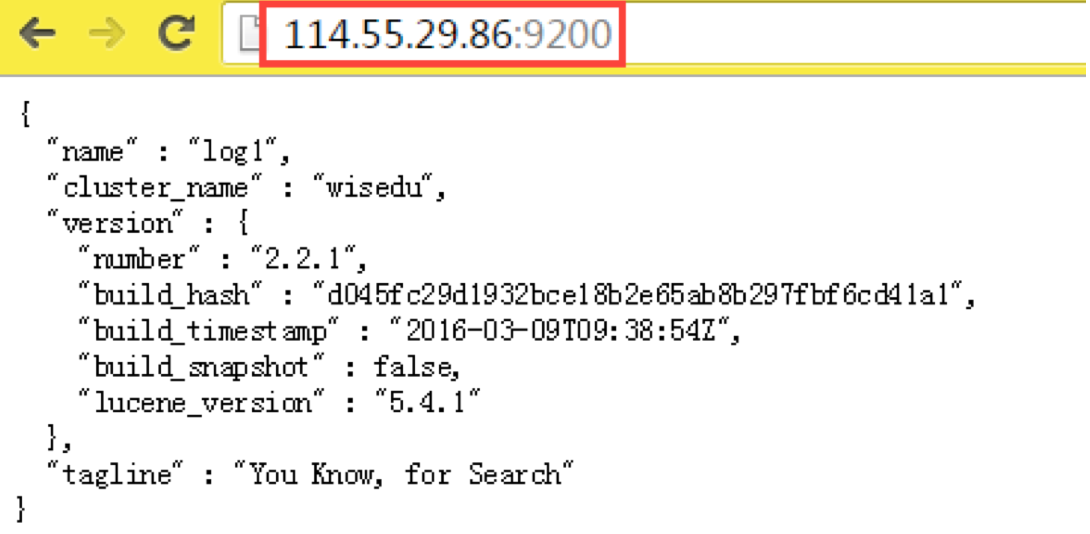
改完后,重启elasticsearch。 在浏览器输入http://ip:9200/,查看页面信息,是否正常启动。
另外两台也需要做这些优化。
四、安装插件:中文分词器ik
elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库。项目地址为:https://github.com/medcl/elasticsearch-analysis-ik
1. 安装Maven
由于该项目使用了Maven来管理,源代码放到github上。所以要先在服务器上面安装Maven,便可以直接在服务器上面生成项目jar包,部署起来更加方便了。
[root@log1 ~]# yum install -y maven
2. 安装ik
注意分词插件的版本,2.2.3对应的插件版本是1.9.3。

[es@log1 ~]$ git clone https://github.com/medcl/elasticsearch-analysis-ik.git
[es@log1 ~]$ cd elasticsearch-analysis-ik/
[es@log1 elasticsearch-analysis-ik]$ mvn package
打包生成ik
3. 拷贝和解压
[es@log1 elasticsearch-analysis-ik]$ mkdir -p /usr/local/elasticsearch/plugins/ik
[es@log1 elasticsearch-analysis-ik]$ cp target/releases/elasticsearch-analysis-ik-1.9..zip /usr/local/elasticsearch/plugins/ik
[es@log1 ~]$ cd /usr/local/elasticsearch/plugins/ik/
[es@log1 ik]$ unzip -oq elasticsearch-analysis-ik-1.9..zip
拷贝和解压
4. 重启elasticsearch
直接重启就可以了,不需要在Elasticsearch中添加配置index.analysis.analyzer.ik.type : “ik” 。
[es@log1 ik]$ cd /usr/local/elasticsearch/bin/
[es@log1 bin]$ jps
Jps
Elasticsearch
[es@log1 bin]$ kill -
[es@log1 elasticsearch]$ bin/elasticsearch -d
重启Elasticsearch
另外两台也需要解压这个插件进去,重新启动。
5. 分词测试
(1)创建一个索引,名为index
[es@log1 elasticsearch]$ curl -XPUT http://114.55.29.86:9200/index
{"acknowledged":true}
(2)index some docs
命令行输入以下内容:
curl -XPOST http://114.55.29.86:9200/index/fulltext/1 -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
' curl -XPOST http://114.55.29.86:9200/index/fulltext/2 -d'
{"content":"公安部:各地校车将享最高路权"}
' curl -XPOST http:// 114.55.29.86:9200/index/fulltext/3 -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
' curl -XPOST http:// 114.55.29.86:9200/index/fulltext/4 -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
'
(3)测试
命令行输入:
curl -XPOST http://114.55.29.86:9200/index/fulltext/_search -d'
{
"query" : { "term" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
'
结果:
{"took":,"timed_out":false,"_shards":{"total":,"successful":,"failed":},"hits":{"total":,"max_score":1.5,"hits":[{"_index":"index","_type":"fulltext","_id":"","_score":1.5,"_source":
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
,"highlight":{"content":["<tag1>中国</tag1>驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"]}},{"_index":"index","_type":"fulltext","_id":"","_score":0.53699243,"_source":
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
,"highlight":{"content":["中韩渔警冲突调查:韩警平均每天扣1艘<tag1>中国</tag1>渔船"]}}]}}
结果

Elasticsearch介绍及安装部署的更多相关文章
- Kafka介绍及安装部署
本节内容: 消息中间件 消息中间件特点 消息中间件的传递模型 Kafka介绍 安装部署Kafka集群 安装Yahoo kafka manager kafka-manager添加kafka cluste ...
- elasticsearch+kibana+metricbeat安装部署方法
elasticsearch+kibana+metricbeat安装部署方法 本文是elasticsearch + kibana + metricbeat,没有涉及到logstash部分.通过beat收 ...
- Storm介绍及安装部署
本节内容: Apache Storm是什么 Apache Storm核心概念 Storm原理架构 Storm集群安装部署 启动storm ui.Nimbus和Supervisor 一.Apache S ...
- Apache Solr 初级教程(介绍、安装部署、Java接口、中文分词)
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- hue框架介绍和安装部署
大家好,我是来自内蒙古的小哥,我现在在北京学习大数据,我想把学到的东西分享给大家,想和大家一起学习 hue框架介绍和安装部署 hue全称:HUE=Hadoop User Experience 他是cl ...
- Elasticsearch介绍和安装与使用
转载:https://blog.csdn.net/weixin_42633131/article/details/82902812 1.Elasticsearch介绍和安装 1.1.简介1.1.1.E ...
- Elasticsearch介绍和安装
Elasticsearch介绍和安装 软件包: 链接:https://pan.baidu.com/s/1O_C0JQGfF8sC_OtcCCLNoQ 提取码:3iai 1.1.简介 1.1.1.Ela ...
- elasticsearch kibana的安装部署与简单使用(一)
1.先说说es 我早两年使用过es5.x的版本,记得当时部署还是很麻烦,因为es是java写的,要先在机器上部署java环境jvm之类的一堆东西,然后才能安装es 但是现在我使用的是目前最新的7.6版 ...
- Hadoop入门进阶课程13--Chukwa介绍与安装部署
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
随机推荐
- UVAL 7902 2016ECfinal F - Mr. Panda and Fantastic Beasts
题意: 给出n个串,求一个最短的第一个串的子串使它不在其他的n-1个串中出现,若有多个求字典序最小的. Limits: • 1 ≤ T ≤ 42. • 2 ≤ N ≤ 50000. • N ≤ S1 ...
- Qt error ------ incomplete type 'QApplication' used in nested name specifier
没有包含 ‘QApplication’ 头文件
- 开源分布式工作流任务调度系统Easy Scheduler Release 1.0.2发布
Easy Scheduler Release 1.0.2===Easy Scheduler 1.0.2是1.x系列中的第三个版本.此版本增加了调度开放接口.worker分组(指定任务运行的机器组).任 ...
- label和fieldset标签
一.label标签 作用:可以通过for属性关联input标签的 id 属性,这样可以实现在点击label标签的内容时,可以使input文本框中获取输入的光标. <body> <la ...
- K8S钩子操作
简介 我们知道,K8S可以在应用容器启动之前先执行一些预定义的操作,比如事先生成一些数据,以便于应用容器在启动的时候使用.这种方式可以通过init container技术实现,具体可以参考<Ku ...
- getContentLength() 指为 -1 的解决办法
在这个坑里3个多小时啊.这里不得不抱怨下,国内的资料坑爹,全部copy不说,还是错的. 解决办法: 在服务端加入代码: File file = new File(path); //path为要下载的文 ...
- 安装VisualSVN Server 报错The specified TCP port is occupied
安装过程中报错,如下图所示. The specified TCP port is occupied by another service.Please stop that service or use ...
- 算法进阶之Leetcode刷题记录
目录 引言 题目 1.两数之和 题目 解题笔记 7.反转整数 题目 解题笔记 9.回文数 题目 解题笔记 13.罗马数字转整数 题目 解题笔记 14.最长公共前缀 题目 解题笔记 20.有效的括号 题 ...
- bzoj千题计划172:bzoj1192: [HNOI2006]鬼谷子的钱袋
http://www.lydsy.com/JudgeOnline/problem.php?id=1192 1,2,4,8,…… n-2^k 可以表示n以内的任意数 若n-2^k 和 之前的数相等,一个 ...
- 环境变量ANDROID_SDK_HOME的作用
默认情况下,开发者创建的AVD(Android Virtual Device)存放在家目录的.android下. 如果是Linux,其路径就是 /home/<your_user_name> ...