机器学习之利用KNN近邻算法预测数据
前半部分是简介, 后半部分是案例
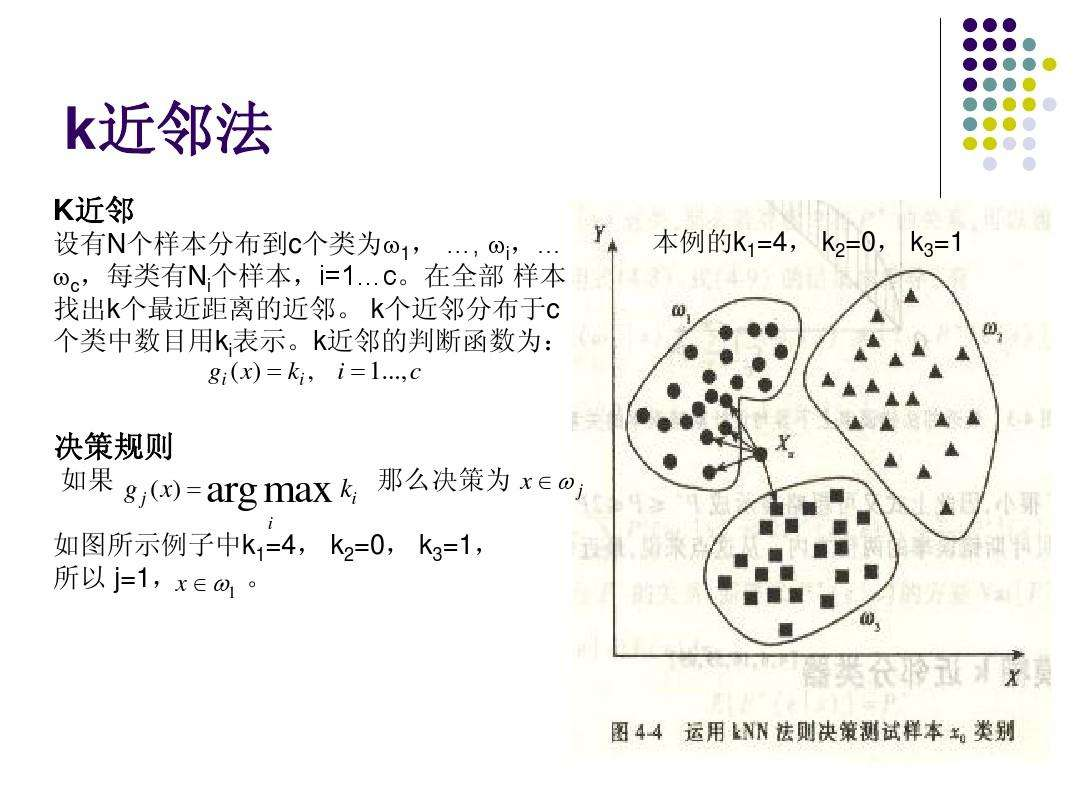
KNN近邻算法:
简单说就是采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor,KNN)
优点: 精度高、对异常值不敏感、无数据输入假定
缺点:时间复杂度高、空间复杂度高
- 1、当样本不平衡时,比如一个类的样本容量很大,其他类的样本容量很小,输入一个样本的时候,K个临近值中大多数都是大样本容量的那个类,这时可能就会导致分类错误。改进方法是对K临近点进行加权,也就是距离近的点的权值大,距离远的点权值小。
- 2、计算量较大,每个待分类的样本都要计算它到全部点的距离,根据距离排序才能求得K个临近点,改进方法是:先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
适用数据范围:
- 标称型(离散型):标称型目标变量的结果只在有限目标集中取值,如真与假(标称型目标变量主要用于分类)
- 数值型:数值型目标变量则可以从无限的数值集合中取值,如0.100,42.001等 (数值型目标变量主要用于回归分析)
工作原理:
- 训练样本集—>存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。 最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
- 电影类别KNN分析(图片来源于网络)
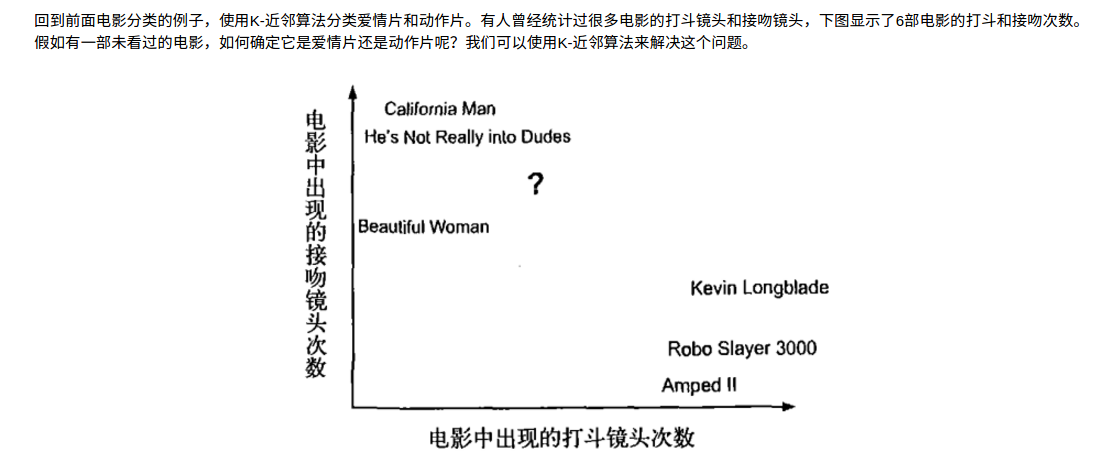

- 欧氏距离(Euclidean Distance,欧几里得度量)

- 计算过程图
- 案例
代码都是在 jupyter notebook 中写的
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
# 以上导入的包都是自己习惯性导入, 因为随时都可能会用到, 就每次先把这些都导入了 #这儿是我自己写了一个excel表格,方便快速的读取数据, 演示使用, 就不用series或者dataframe写了
film = pd.read_excel('films.xlsx',sheet_name=1)
#输入film后出现表格
fil

# 电影的样本特征
train=film[['动作镜头','接吻镜头']]
# 样本标签,即要预测的标签,这儿要预测新数据是属于什么类别的电影
target=film['电影类别']
# 创建机器学习模型,需要导入
from sklearn.neighbors import KNeighborsClassifier
# 创建对象, 这儿的数据因为是离散型, 所以使用KNeighborsClassifier,
knn=KNeighborsClassifier()
# 对knn模型进行训练, 传入样本特征 和 样本标签
# 构建函数原型、构建损失函数、求损失函数最优解
knn.fit(train,target)
knn
当输入knn后出现如下代码, 表示训练完成
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
# 这儿随意写3个样本数据,需要按照样本数据的维度来写
cat=np.array([[5,19],[21,6],[23,24]])
# cat=np.array([[21,4]]) 也可以写1个
# 使用predict函数对数据进行预测
knn.predict(cat)
运行会出现下图:

预测完成 ! 成功判断出3个新样本的归属类别
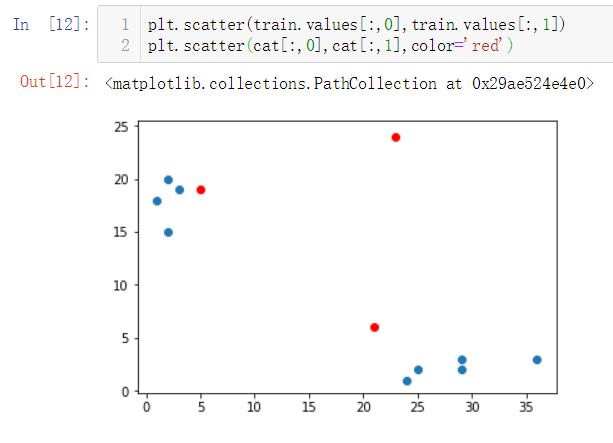
接下来也可以绘制图, 直观的查看近邻情况
# scatter画出来的是散点图, 取数据使用 .values,二维数组中, 一维全部取出, 二维取0,表示出来就是[:,0]
plt.scatter(train.values[:,0],train.values[:,1])
# scatter可以有一些属性, 下边的color可以自定义显示的颜色
plt.scatter(cat[:,0],cat[:,1],color='red')
效果图为:
在使用KNN近邻算法时, 注意要分清楚样本集, 样本特征,样本标签
技术交流可以留言评论哦 ! 虚心学习, 不忘初心, 共同奋进 !
机器学习之利用KNN近邻算法预测数据的更多相关文章
- KNN近邻算法
K近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.kNN算法的核 ...
- 机器学习入门KNN近邻算法(一)
1 机器学习处理流程: 2 机器学习分类: 有监督学习 主要用于决策支持,它利用有标识的历史数据进行训练,以实现对新数据的表示的预测 1 分类 分类计数预测的数据对象是离散的.如短信是否为垃圾短信,用 ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 《机器学习实战》-k近邻算法
目录 K-近邻算法 k-近邻算法概述 解析和导入数据 使用 Python 导入数据 实施 kNN 分类算法 测试分类器 使用 k-近邻算法改进约会网站的配对效果 收集数据 准备数据:使用 Python ...
- 机器学习:1.K近邻算法
1.简单案例:预测男女,根据身高,体重,鞋码 import numpy as np import matplotlib import sklearn from skleran.neighbors im ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
随机推荐
- if 里面嵌套一个if&else (我自己又细分了别的条件,加了elif)
场景: 一个陌生人敲门..... gender = input("你是男的是女的?") if gender == "女": print("请进&quo ...
- 如何处理高并发情况下的DB插入
1. 我们需要接收一个外部的订单,而这个订单号是不允许重复的 2. 数据库对外部订单号没有做唯一性约束 3. 外部经常插入相同的订单,对于已经存在的订单则拒绝处理 对于这个需求,很简单我们会用下 ...
- python decorator的本质
推荐查看博客:python的修饰器 对于Python的这个@注解语法糖- Syntactic Sugar 来说,当你在用某个@decorator来修饰某个函数func时,如下所示: @decorato ...
- [luogu1600] 天天爱跑步
题面 直接写正解吧, 不想再写部分分了, 对于\(u\)和\(v\), 我们可以将它拆成两条路径, \(u\)到\(lca(u, v)\)和\(lca(u, v)\)到v, 在这里只分析从\(u\ ...
- virtualbox+vagrant学习-2(command cli)-26-vagrant share命令
Share share命令初始化了一个vagrant share会话,允许你与世界上任何一个人共享vagrant环境,允许在几乎任何网络环境中直接在vagrant环境中进行协作. 你可以在本博客的vi ...
- Python之Cubes框架使用
本文主要内容包含Cubes框架的介绍和简单使用. 一. 介绍和安装 Cubes是一个轻量级的Python框架和一套工具,用于开发报告和分析应用程序,在线分析处理(OLAP),多维分析和聚合数据的浏览. ...
- Ubuntu下查看自己的GPU型号
1.在命令行中输入:lspci 即可看到当前显卡型号. 2.Ubuntu 14.04 安装 Nvidia 私有驱动 sudo apt-get install nvidia-331 3.进行双显卡切换n ...
- Kafka设计解析(二)Kafka High Availability (上)
转载自 技术世界,原文链接 Kafka设计解析(二)- Kafka High Availability (上) Kafka从0.8版本开始提供High Availability机制,从而提高了系统可用 ...
- 【vue】父子组件间通信----传值
官方文档参考 (一)父组件 向 子组件 传值 ①在父组件中调用子组件处,绑定要传的数据data1, 如 <nav :data1=" " ></nav> ...
- node vue 开发环境部署时,外部访问页面出现: Invalid Host header 服务器域名访问出现的问题
这是新版本 webpack-dev-server 出于安全考虑, 默认检查 hostname,如果hostname不是配置内的,将中断访问.顾仅存在于开发环境: npm run dev,打包之后不会 ...