R 分组计算描述性统计量
统计学区内各个小区的房价均值
数据格式
|
id|community_name|house_area|house_structure|house_total|house_avg|agency_name|house_floor_curr|house_floor_total|house_floor_type 6328500962692431872|尚东花园|77.0|3室2厅|285.0|37013.0|利众置业|5|5|多层 6328500979813580800|赛世香樟园|93.0|2室2厅|265.0|28495.0|苏商房产仙林店|9|11|小高层 |
导入数据
|
house<- read.table("house_data.txt", header = TRUE, sep='|',fileEncoding ="UTF-8", stringsAsFactors = FALSE, colClasses = c("character","character","numeric", "character","numeric","numeric","character", "numeric","numeric","character")) houseXQ<- sqldf("select * from house where community_name!='东郊小镇' ",row.names=TRUE) |
选择列
|
selectedColumns<- c("community_name","house_avg") |
将小区名转换成因子
communityFactor<- factor(houseXQ$community_name, order=FALSE) |
将因子列整合到数据框中
houseXQ <-cbind(houseXQ, communityFactor) |
重新选择列
selectedColumns<- c("communityFactor","house_avg")
|
看一下数据
head(houseXQ[selectedColumns]) |
按小区名分组计算均值
aggregate(houseXQ[selectedColumns], by=list(communityFactor=houseXQ$communityFactor),mean) |
结果:
自定义函数计算统计量
|
funcMystats<- function(x, na.omit= FALSE){ if(na.omit){ x<- x[!is.na(x)] } m<- mean(x) n<- length(x) s<- sd(x) skew<- sum((x-m)^3/s^3)/n kurt<- sum((x-m)^4/s^4)/n-3 return (c(n=n,mean=m, stdev=s, skew=skew, kurtosis=kurt)) } funcDstats <- function(x) sapply(x, funcMystats)#对于每个X调用 funcMystats 函数 by(houseXQ[selectedColumns], houseXQ$community_name, funcDstats) |
结果(部分)
houseXQ$community_name: 东方天郡 communityFactor house_avg n 51 51.0000000 mean NA 38255.8039216 stdev 0 2145.6443696 skew NA -0.4395676 kurtosis NA 0.6015383 ------------------------------------------------------------ houseXQ$community_name: 康桥圣菲 communityFactor house_avg n 9 9.0000000 mean NA 34359.0000000 stdev 0 1567.1059313 skew NA -0.9804274 kurtosis NA -0.8342473 ------------------------------------------------------------ houseXQ$community_name: 南师大茶苑 communityFactor house_avg n 1 1 mean NA 31691 stdev NA NA skew NA NA kurtosis NA NA ------------------------------------------------------------ houseXQ$community_name: 赛世香樟园 communityFactor house_avg n 3 3.0000000 mean NA 28938.3333333 stdev 0 1654.1733081 skew NA 0.2487582 kurtosis NA -2.3333333 ------------------------------------------------------------ houseXQ$community_name: 三味公寓 communityFactor house_avg n 2 2.0000 mean NA 28662.0000 stdev 0 576.9991 skew NA 0.0000 kurtosis NA -2.7500 ------------------------------------------------------------ houseXQ$community_name: 尚东花园 communityFactor house_avg n 1 1 mean NA 37013 stdev NA NA skew NA NA kurtosis NA NA ------------------------------------------------------------ |
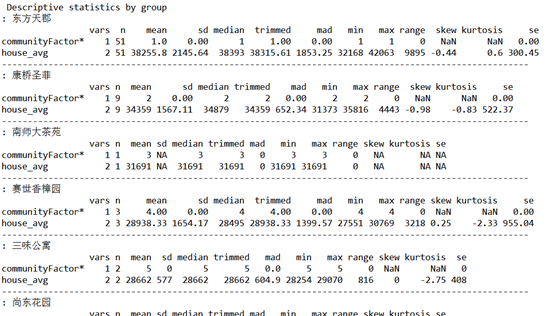
使用 psych 包中的 describeBy()分组计算概述统计量
library(psych) selectedColumns<- c("communityFactor","house_avg")
describeBy(houseXQ[selectedColumns], list(houseXQ$communityFactor)) |
结果如下(部分)
R 分组计算描述性统计量的更多相关文章
- R语言笔记006——分组获取描述性统计量
方法一:使用aggregate()分组获取描述性统计量 aggregate(mtcars[vars],by=list(am=mtcars$am),mean) aggregate(mtcars[vars ...
- R语言笔记005——计算描述性统计量
数据的分布特征: 分布的集中趋势,反应各数据向其中心值靠拢或聚集的程度(平均数,中位数,四分位数,众数) 分布的离散程度,反应各数据远离其中心值的趋势(极差,四分位差,方差,标准差,离散系数) 分布的 ...
- spark 例子groupByKey分组计算
spark 例子groupByKey分组计算 例子描述: [分组.计算] 主要为两部分,将同类的数据分组归纳到一起,并将分组后的数据进行简单数学计算. 难点在于怎么去理解groupBy和groupBy ...
- R语言计算IV值
更多大数据分析.建模等内容请关注公众号<bigdatamodeling> 在对变量分箱后,需要计算变量的重要性,IV是评估变量区分度或重要性的统计量之一,R语言计算IV值的代码如下: Ca ...
- devexpress表格gridcontrol实现分组,并根据分组计算总计及平均值
1.devexpress表格控件gridcontrol提供了强大的分组功能,你几乎不用写什么代码就可以实现一个分组功能,并且可根据分组计算总计和平均值.这里我例举了一个实现根据班级分组计算班级总人数, ...
- R语言计算moran‘I
R语言计算moran‘I install.packages("maptools")#画地图的包 install.packages("spdep")#空间统计,m ...
- spark 例子groupByKey分组计算2
spark 例子groupByKey分组计算2 例子描述: 大概意思为,统计用户使用app的次数排名 原始数据: 000041b232,张三,FC:1A:11:5C:58:34,F8:E7:1E:1E ...
- R语言计算相关矩阵然后将计算结果输出到CSV文件
R语言计算出一个N个属性的相关矩阵(),然后再将相关矩阵输出到CSV文件. 读入的数据文件格式如下图所示: R程序采用如下语句: data<-read.csv("I:\\SB\land ...
- python库学习笔记——分组计算利器:pandas中的groupby技术
最近处理数据需要分组计算,又用到了groupby函数,温故而知新. 分组运算的第一阶段,pandas 对象(无论是 Series.DataFrame 还是其他的)中的数据会根据你所提供的一个或多个键被 ...
随机推荐
- Codeforces Round #394 (Div. 2) A. Dasha and Stairs 水题
A. Dasha and Stairs 题目连接: http://codeforces.com/contest/761/problem/A Description On her way to prog ...
- Linux学习笔记07—mysql的配置
一.mysql简介 说到数据库,我们大多想到的是关系型数据库,比如mysql.oracle.sqlserver等等,这些数据库软件在windows上安装都非常的方便,在Linux上如果要安装数据库,咱 ...
- Maven 项目不打包 *.hbm.xml 映射文件
使用 Maven 部署 Java Web 项目时,Hibernate 的映射文件 *.hbm.xml 没有被打包部署到目标目录下,解决方法:在 pom.xml 文件中 <build> 节点 ...
- SecureCRT发送心跳机制保持SSH在线(解决阿里云ECS)
设置如下:
- C#中执行Dos命令
//dosCommand Dos命令语句 public string Execute(string dosCommand) { ); } /// <summary> /// 执行DOS命令 ...
- Code Fragment-UI加载策略之-可视者优先加载
通常情况 通常程序的UI不太复杂,我们会直接加载这些UI信息 复杂的UI 加载的元素就相对多一些. 加载的数据相对多. 因为UI元素和数据元素都比较多,加载的时间相对多. 可视者优先加载 不是默认的加 ...
- [Bug]Unable to start process dotnet.exe
This morning I did a sync of a repo using of Visual Studio and then tried to run a web application I ...
- 在ASP.NET MVC中实现Select多选
我们知道,在ASP.NET MVC中实现多选Select的话,使用Html.ListBoxFor或Html.ListBox方法就可以.在实际应用中,到底该如何设计View Model, 控制器如何接收 ...
- 在Delphi中操作快捷方式
快捷方式减少了系统的重复文件,是快速启动程序或打开文件或文件夹的方法,快捷方式对经常使用的程序.文件和文件夹非常有用.在Windows系统中,充斥着大量的快捷方式,那么如何操作这些快捷方式就是一个很头 ...
- IOS开发常用宏定义
//release屏蔽NSLog//放在.pch文件里#ifdef DEBUG #else#define NSLog(...) {};#endif //G.C.D#define BACK(block) ...