Spark性能优化(二)
资源调优
调优概述
在开发完Spark作业之后,就该为作业配置合适的资源了。Spark的资源参数,基本都可以在spark-submit命令中作为参数设置。很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参数,最后就只能胡乱设置,甚至压根儿不设置。资源参数设置的不合理,可能会导致没有充分利用集群资源,作业运行会极其缓慢;或者设置的资源过大,队列没有足够的资源来提供,进而导致各种异常。总之,无论是哪种情况,都会导致Spark作业的运行效率低下,甚至根本无法运行。因此我们必须对Spark作业的资源使用原理有一个清晰的认识,并知道在Spark作业运行过程中,有哪些资源参数是可以设置的,以及如何设置合适的参数值。
Spark作业基本运行原理
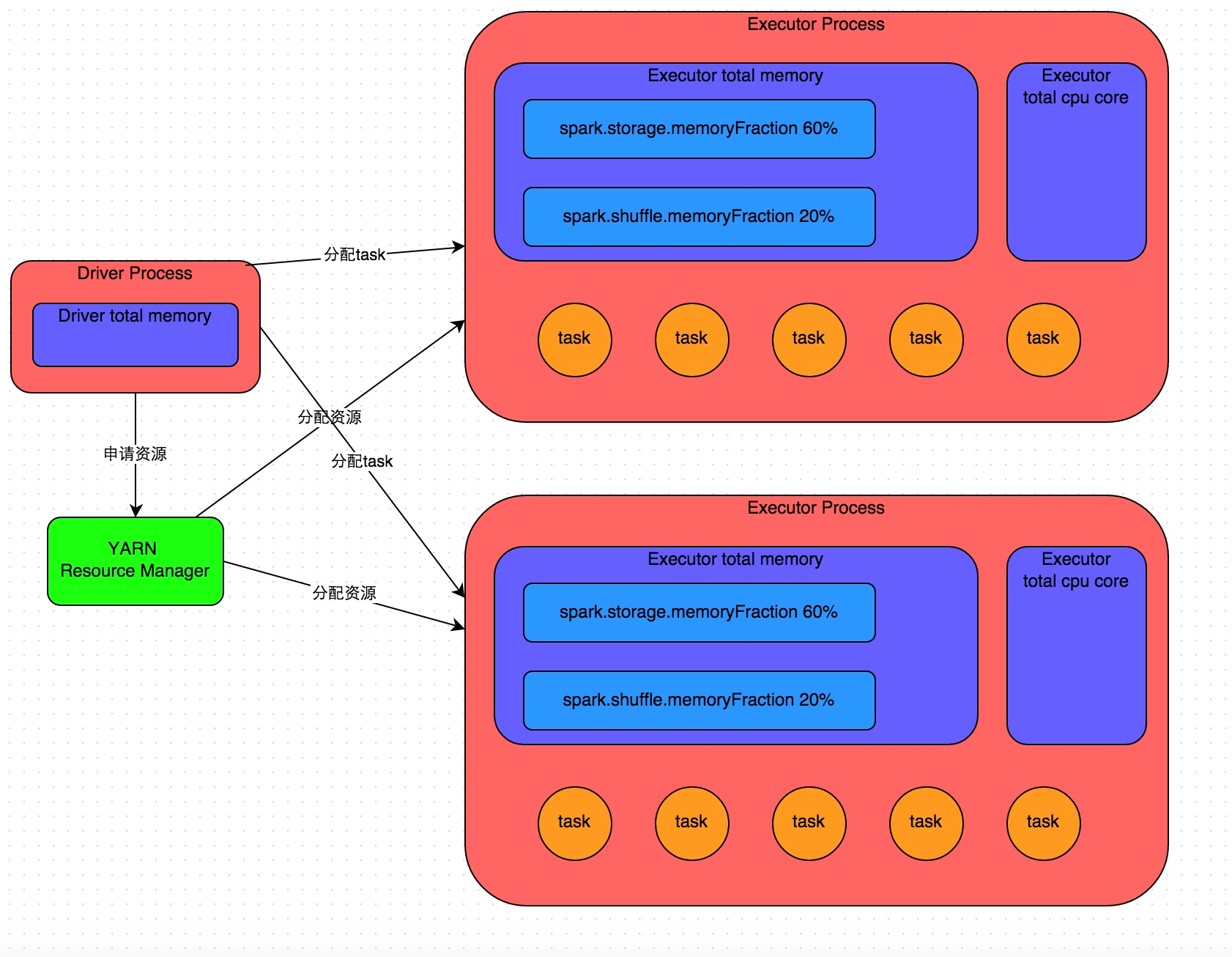
详细原理见上图。我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
以上就是Spark作业的基本运行原理的说明,大家可以结合上图来理解。理解作业基本原理,是我们进行资源参数调优的基本前提。
资源参数调优
了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升Spark作业的执行性能。以下参数就是Spark中主要的资源参数,每个参数都对应着作业运行原理中的某个部分,我们同时也给出了一个调优的参考值。
num-executors
- 参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
- 参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory
- 参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
- 参数调优建议:每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores
- 参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
- 参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
driver-memory
- 参数说明:该参数用于设置Driver进程的内存。
- 参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
spark.default.parallelism
- 参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
- 参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
spark.storage.memoryFraction
- 参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
- 参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
spark.shuffle.memoryFraction
- 参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
- 参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
资源参数的调优,没有一个固定的值,需要同学们根据自己的实际情况(包括Spark作业中的shuffle操作数量、RDD持久化操作数量以及spark web ui中显示的作业gc情况),同时参考本篇文章中给出的原理以及调优建议,合理地设置上述参数。
资源参数参考示例
以下是一份spark-submit命令的示例,大家可以参考一下,并根据自己的实际情况进行调节:
./bin/spark-submit \
--master yarn-cluster \
--num-executors \
--executor-memory 6G \
--executor-cores \
--driver-memory 1G \
--conf spark.default.parallelism= \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \
写在最后的话
根据实践经验来看,大部分Spark作业经过本次基础篇所讲解的开发调优与资源调优之后,一般都能以较高的性能运行了,足以满足我们的需求。但是在不同的生产环境和项目背景下,可能会遇到其他更加棘手的问题(比如各种数据倾斜),也可能会遇到更高的性能要求。为了应对这些挑战,需要使用更高级的技巧来处理这类问题。在后续的《Spark性能优化指南——高级篇》中,我们会详细讲解数据倾斜调优以及Shuffle调优。
Spark性能优化(二)的更多相关文章
- 【转载】Spark性能优化指南——高级篇
前言 数据倾斜调优 调优概述 数据倾斜发生时的现象 数据倾斜发生的原理 如何定位导致数据倾斜的代码 查看导致数据倾斜的key的数据分布情况 数据倾斜的解决方案 解决方案一:使用Hive ETL预处理数 ...
- 【转载】 Spark性能优化指南——基础篇
转自:http://tech.meituan.com/spark-tuning-basic.html?from=timeline 前言 开发调优 调优概述 原则一:避免创建重复的RDD 原则二:尽可能 ...
- 【转】【技术博客】Spark性能优化指南——高级篇
http://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651745207&idx=1&sn=3d70d59cede236e ...
- 【转】Spark性能优化指南——基础篇
http://mp.weixin.qq.com/s?__biz=MjM5NDMwNjMzNA==&mid=2651805828&idx=1&sn=2f413828d1fdc6a ...
- Spark性能优化指南——高级篇(转载)
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能优化指南——基础篇(转载)
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark性能优化指南-高级篇
转自https://tech.meituan.com/spark-tuning-pro.html,感谢原作者的贡献 前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作 ...
- Spark性能优化指南——基础篇
本文转自:http://tech.meituan.com/spark-tuning-basic.html 感谢原作者 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一 ...
- Spark性能优化指南——高级篇
本文转载自:https://tech.meituan.com/spark-tuning-pro.html 美团技术点评团队) Spark性能优化指南——高级篇 李雪蕤 ·2016-05-12 14:4 ...
随机推荐
- 《转》windows下通过cmd切换python2和python3版本
当电脑中同时安装了python2和python3时,往往会由切换版本的需求.那么如何通过cmd命令行做到呢? 方法:修改python.exe的文件名 举个栗子: 我的电脑中同时安装了py2.7.10和 ...
- 基于链表的C语言堆内存检测
说明 本文基于链表实现C语言堆内存的检测机制,可检测内存泄露.越界和重复释放等操作问题. 本文仅提供即视代码层面的检测机制,不考虑编译链接级的注入或钩子.此外,该机制暂未考虑并发保护. 相关性文章参见 ...
- wex5 onactive不执行的解决办法
由index.w点击某个图片,转到adetail,希望每次adetail加载时,取到参数id index.w <tbody class="x-list-template" x ...
- 【CF873F】Forbidden Indices 后缀自动机
[CF873F]Forbidden Indices 题意:给你一个串s,其中一些位置是危险的.定义一个子串的出现次数为:它的所有出现位置中,不是危险位置的个数.求s的所有子串中,长度*出现次数的最大值 ...
- iOS - 开源框架、项目和学习资料汇总(动画篇)
动画 1. Core Animation笔记,基本的使用方法 – Core Animation笔记,基本的使用方法:1.基本动画,2.多步动画,3.沿路径的动画,4.时间函数,5.动画组.2. awe ...
- JDBC 连接数据库,包含连接池
1.不使用连接池方式(Jdbc) 1.1 工具类(JdbcUtil.java) package com.jdbc.util; import java.io.IOException;import jav ...
- split陷阱
如果split最后一个为空,则要这么写 String[] lines=line.split(",",-1);
- 判断强联通图中每条边是否只在一个环上(hdu3594)
hdu3594 Cactus Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) T ...
- 利用Python读取外部数据文件
不论是数据分析,数据可视化,还是数据挖掘,一切的一切全都是以数据作为最基础的元素.利用Python进行数据分析,同样最重要的一步就是如何将数据导入到Python中,然后才可以实现后面的数据分析.数 ...
- win10中强制vs2015使用管理员启动
文章转自: win10中强制vs2015使用管理员启动 首先,和网上流传的版本一样,需要做这下面这两步: 1. 打开VS快捷方式的属性对话框. 2.勾选“用管理员身份运行” 现在,你双击V ...