mapreduce的cleanUp和setUp的特殊用法(TopN问题)和常规用法
一:特殊用法
我们上来不讲普通用法,普通用法放到最后。我们来谈一谈特殊用法,了解这一用法,让你的mapreduce编程能力提高一个档次,毫不夸张!!!扯淡了,让我们进入正题:
我们知道reduce和map都有一个局限性就是map是读一行执行一次,reduce是每一组执行一次
但是当我们想全部得到数据之后,按照需求删选然后再输出怎么办?
这时候只使用map和reduce显然是达不到目的的?
那该怎么呢?这时候我们想到了 setUp和cleanUp的特性,只执行一次。
这样我们对于最终数据的过滤,然后输出要放在cleanUp中。这样就能实现对数据,不一组一组输出,而是全部拿到,最后过滤输出。经典运用常见,mapreduce分析数据然后再求数据的topN 问题。
以求出单词出现次数前三名为例
MAPREDUCE求topn问题
以wordcount为例,求出单词出现数量前三名
数据:
love you do
you like me
me like you do
love you do
you like me
me like you do
love you do
you like me
me like you do
love you do
you like me
分析:
我们知道mapreduce有分许聚合的功能,所以第一步就是:
把每个单词读出来,然后在reduce中聚合,求出每个单词出现的次数
但是怎么控制只输出前三名呢?
我们知道,map是读一行执行一次,reduce是每一组执行一次
所以只用map,和reduce是无法控制输出的次数的
但是我们又知道,无论map或者reduce都有 setUp 和cleanUp而且这两个执行一次
所以我们可以在reduce阶段把每一个单词当做key,单词出现的次数当做value,每一组存放到一个map里面,此时只存,不写出。在reduce的cleanUp阶段map排序,然后输出前三名
代码:
maper代码
public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] split = value.toString().split(" ");
for (String word : split) {
context.write(new Text(word), new IntWritable(1));
}
}
}
reduce代码
public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
Map<String,Integer> map=new HashMap<String, Integer>();
protected void reduce(Text key, Iterable<IntWritable> iter,
Reducer<Text, IntWritable, Text, IntWritable>.Context conext) throws IOException, InterruptedException {
int count=0;
for (IntWritable wordCount : iter) {
count+=wordCount.get();
}
String name=key.toString();
map.put(name, count);
}
@Override
protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//这里将map.entrySet()转换成list
List<Map.Entry<String,Integer>> list=new LinkedList<Map.Entry<String,Integer>>(map.entrySet());
//通过比较器来实现排序
Collections.sort(list,new Comparator<Map.Entry<String,Integer>>() {
//降序排序
@Override
public int compare(Entry<String, Integer> arg0,Entry<String, Integer> arg1) {
return (int) (arg1.getValue() - arg0.getValue());
}
});
for(int i=0;i<3;i++){
context.write(new Text(list.get(i).getKey()), new IntWritable(list.get(i).getValue()));
}
}}
job客户端代码
public class JobClient{
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//conf.set("fs.defaultFS", "hdfs://wangzhihua1:9000/");
conf.set("mapreduce.framework", "local");
Job job = Job.getInstance(conf);
// 封装本mr程序相关到信息到job对象中
//job.setJar("d:/wc.jar");
job.setJarByClass(JobClient.class);
// 指定mapreduce程序用jar包中的哪个类作为Mapper逻辑类
job.setMapperClass(WcMapper.class);
// 指定mapreduce程序用jar包中的哪个类作为Reducer逻辑类
job.setReducerClass(WcReducer.class);
// 告诉mapreduce程序,我们的map逻辑输出的KEY.VALUE的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 告诉mapreduce程序,我们的reduce逻辑输出的KEY.VALUE的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 告诉mapreduce程序,我们的原始文件在哪里
FileInputFormat.setInputPaths(job, new Path("d:/wc/input/"));
// 告诉mapreduce程序,结果数据往哪里写
FileOutputFormat.setOutputPath(job, new Path("d:/wc/output/"));
// 设置reduce task的运行实例数
job.setNumReduceTasks(1); // 默认是1
// 调用job对象的方法来提交任务
job.submit();
}
}
二 常规用法
在hadoop的源码中,基类Mapper类和Reducer类中都是只包含四个方法:setup方法,cleanup方法,run方法,map方法。如下所示:
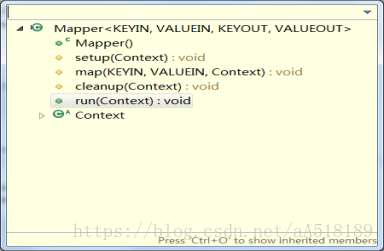
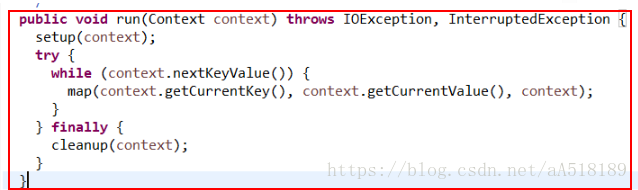
其方法的调用方式是在run方法中,如下所示:
可以看出,在run方法中调用了上面的三个方法:setup方法,map方法,cleanup方法。其中setup方法和cleanup方法默认是不做任何操作,且它们只被执行一次。但是setup方法一般会在map函数之前执行一些准备工作,如作业的一些配置信息等;cleanup方法则是在map方法运行完之后最后执行 的,该方法是完成一些结尾清理的工作,如:资源释放等。如果需要做一些配置和清理的工作,需要在Mapper/Reducer的子类中进行重写来实现相应的功能。map方法会在对应的子类中重新实现,就是我们自定义的map方法。该方法在一个while循环里面,表明该方法是执行很多次的。run方法就是每个maptask调用的方
hadoop中的MapReduce框架里已经预定义了相关的接口,其中如Mapper类下的方法setup()和cleanup()。
setup(),此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高!
cleanup(),此方法被MapReduce框架仅且执行一次,在执行完毕Map任务后,进行相关变量或资源的释放工作。若是将释放资源工作放入方法map()中,也会导致Mapper任务在解析、处理每一行文本后释放资源,而且在下一行文本解析前还要重复初始化,导致反复重复,程序运行效率不高!
所以,建议资源初始化及释放工作,分别放入方法setup()和cleanup()中进行。
mapreduce的cleanUp和setUp的特殊用法(TopN问题)和常规用法的更多相关文章
- GridView的常规用法
GridView控件在Asp.net中相当常用,以下是控件的解释,有些是常用的,有些是偶尔用到的,查找.使用.记录,仅此而已.(最后附带DropDownList控件) ASP.NET中GridView ...
- 子查询。ANY三种用法。ALL两种用法。HAVING中使用子查询。SELECT中使用子查询。
子查询存在的意义是解决多表查询带来的性能问题. 子查询返回单行多列: ANY三种用法: ALL两种用法: HAVING中的子查询返回单行单列: SELECT中使用子查询:(了解就好,避免使用这种方法! ...
- entrySet用法 以及遍历map的用法
entrySet用法 以及遍历map的用法 keySet是键的集合,Set里面的类型即key的类型entrySet是 键-值 对的集合,Set里面的类型是Map.Entry 1.keySet( ...
- LOG4NET用法(个人比较喜欢的用法)
LOG4NET用法(个人比较喜欢的用法) http://fanrsh.cnblogs.com/archive/2006/06/08/420546.html
- 7.1 安装软件包的三种方法 7.2 rpm包介绍 7.3 rpm工具用法 7.4 yum工具用法 7.5 yum搭建本地仓库
7.1 安装软件包的三种方法 7.2 rpm包介绍 7.3 rpm工具用法 7.4 yum工具用法 7.5 yum搭建本地仓库 三种方法 rpm工具----->类型windows下的exe程序 ...
- 【python】-matplotlib.pylab常规用法
目的: 了解matplotlib.pylab常规用法 示例 import matplotlib.pylab as pl x = range(10) y = [i * i for i in x] pl. ...
- MarkDown的常规用法
MarkDown的常规用法 标题 # 一级标题 ## 二级标题 ... ###### 六级标题 列表 第二级 - 和 空格 + 和 空额 * 和 空格 第三级 代码块 多行代码块 3个` 回车 单行代 ...
- Vuex 常规用法
背景 很多时候我们已经熟悉了框架的运用,但是有时候就是忘了怎么用 所以这里想记下大部分的框架使用方法,方便使用的时候拷贝 一.安装 npm 方式 npm install vuex --save yar ...
- setUp和tearDown及setUpClass和tearDownClass的用法及区别
① setup():每个测试函数运行前运行 ② teardown():每个测试函数运行完后执行 ③ setUpClass():必须使用@classmethod 装饰器,所有test运行前运行一次 ④ ...
随机推荐
- 走进JDK(二)------String
本文基于java8. 基本概念: Jvm 内存中 String 的表示是采用 unicode 编码 UTF-8 是 Unicode 的实现方式之一 一.String定义 public final cl ...
- centos7安装python3.6后导致防火墙功能无法正常工作的解决办法
问题:因为默认python版本被设置成了python3.6,而进行防火墙的指令操作频频报错. Jul 19 16:30:51 localhost.localdomain systemd[1]: Sta ...
- 20155339 Exp9 Web安全基础
Exp9 Web安全基础 基础问题回答 (1)SQL注入攻击原理,如何防御 原理:它是利用现有应用程序,将恶意的SQL命令注入到后台数据库引擎执行的能力,它可以通过在Web表单中输入恶意SQL语句得到 ...
- Hessian 使用例子
一.协议包(数据对象需要实现序列化接口,可以用于服务端接口.客户端调用服务之用) /** * */ package com.junge.demo.protocol.model; import java ...
- AFNetworking 3.0中调用[AFHTTPSessionManager manager]方法导致内存泄漏的解决办法
在使用AFNetworking3.0框架,使用Instruments检查Leaks时,检测到1000多个内存泄漏的地方,定位到 [AFHTTPSessionManager manager] 语句中,几 ...
- iOS逆向之Reveal
Reveal是一个强大的UI分析工具,使用它可以查看各个界面的视图层级,在解决界面显示问题时非常有用.它最大的特点就是非常直观,查看UI布局的时候非常方便. 我们知道,Reveal官网提供的方法只能监 ...
- libRTMP 整体说明
函数结构 (libRTMP)的整体的函数调用结构图如下图所示: 原图地址:http://img.my.csdn.net/uploads/201602/10/1455087168_7199.png 基本 ...
- vscode 集成 cygwin 的注意事项
vscode 集成 cygwin vscode 现在是我的主力开发编辑器,它自带 terminal 不需要我各种切换,我还想要在 windows 下执行一些简单的 .sh 文件.所以,我希望有一款工具 ...
- Java异步执行多个HTTP请求的例子(需要apache http类库)
直接上代码 package org.jivesoftware.spark.util; import java.io.IOException; import java.util.concurrent.C ...
- 【xsy2305】喽 计算几何
UPD:这个做法被hack了 题目大意:给你$n$个红点和$m$个黑点,问你至少需要保留多少个黑点,才能用由黑点组成的凸包包住所有红点. 数据范围:$n≤10^5$,$m≤500$ 首先,我们将红点和 ...