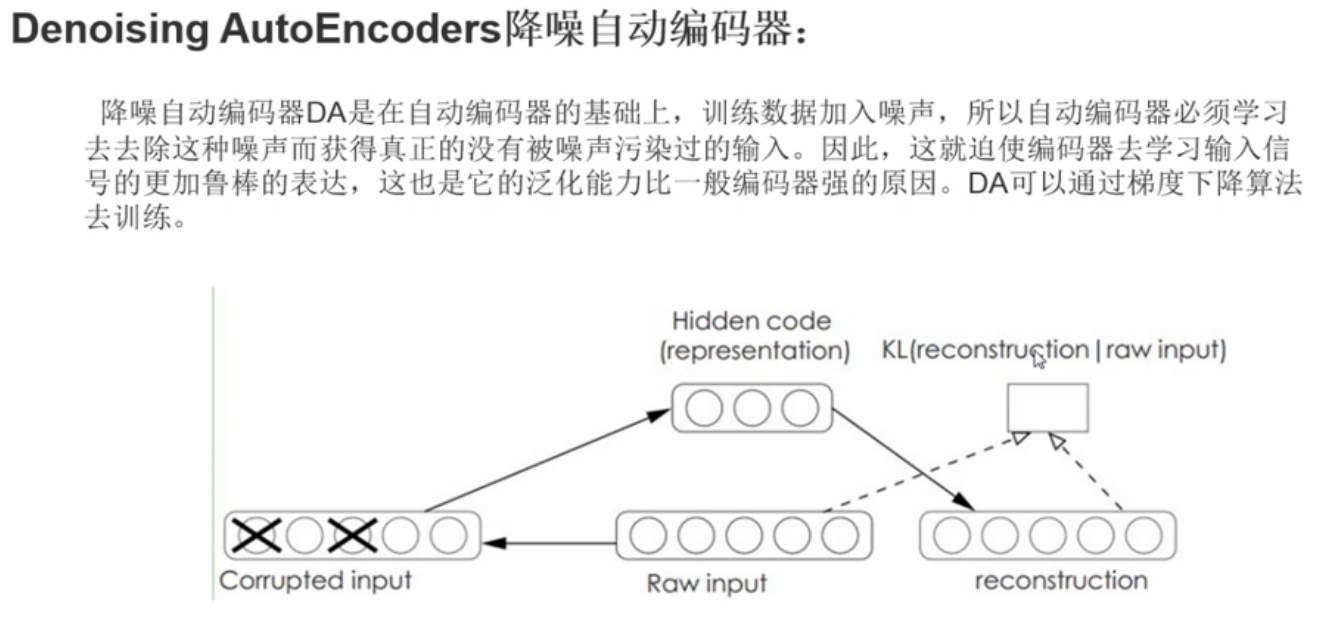
『TensorFlow』降噪自编码器设计
背景简介
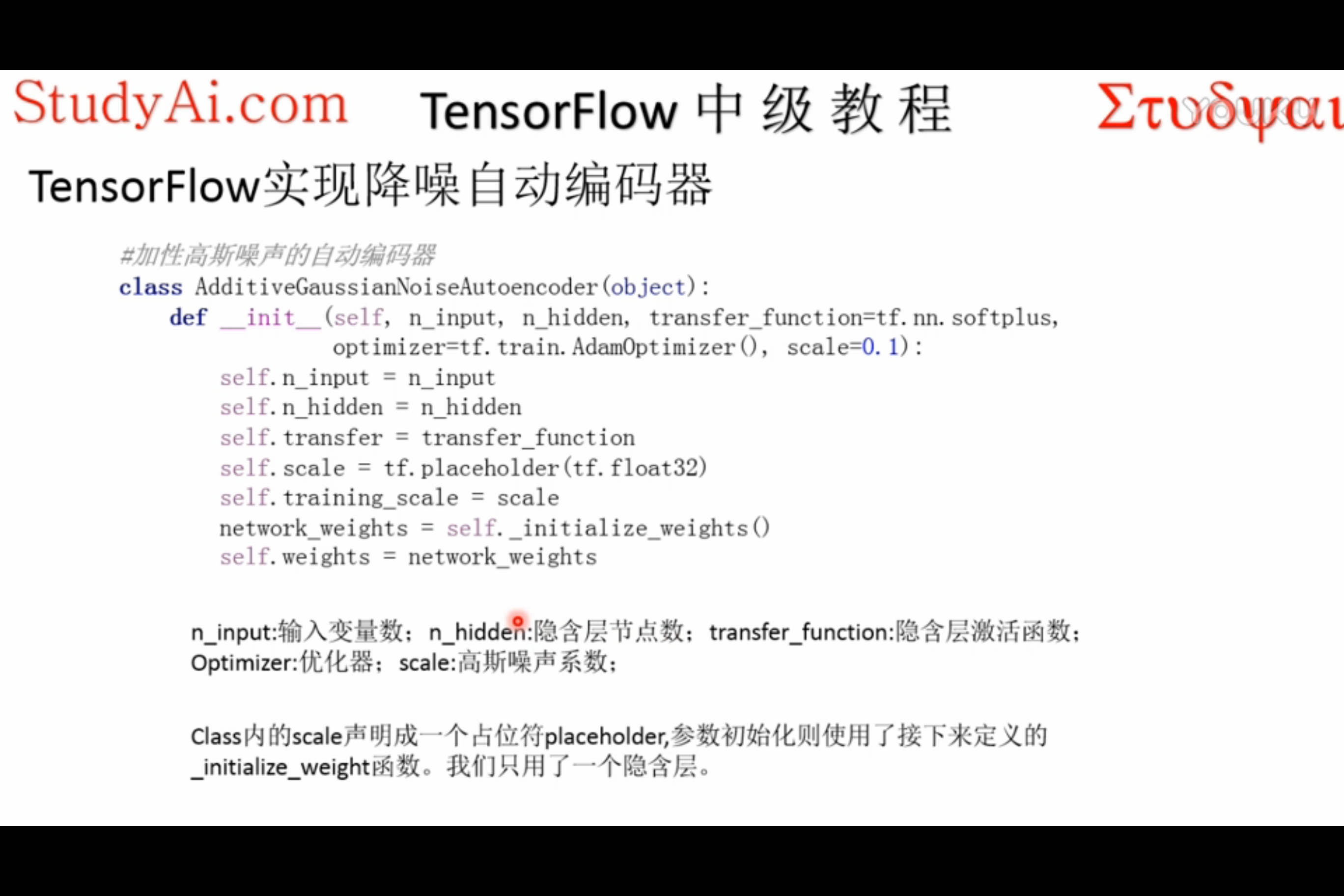
TensorFlow实现讲解
设计新思路:
1.使用类来记录整个网络:
使用_init_()属性来记录 网络超参数 & 网络框架 & 训练过程
使用一个隐式方法初始化网络参数
2.使用字典存储初始化的各个参数(w&b)
参数初始化新思路:


主程序:



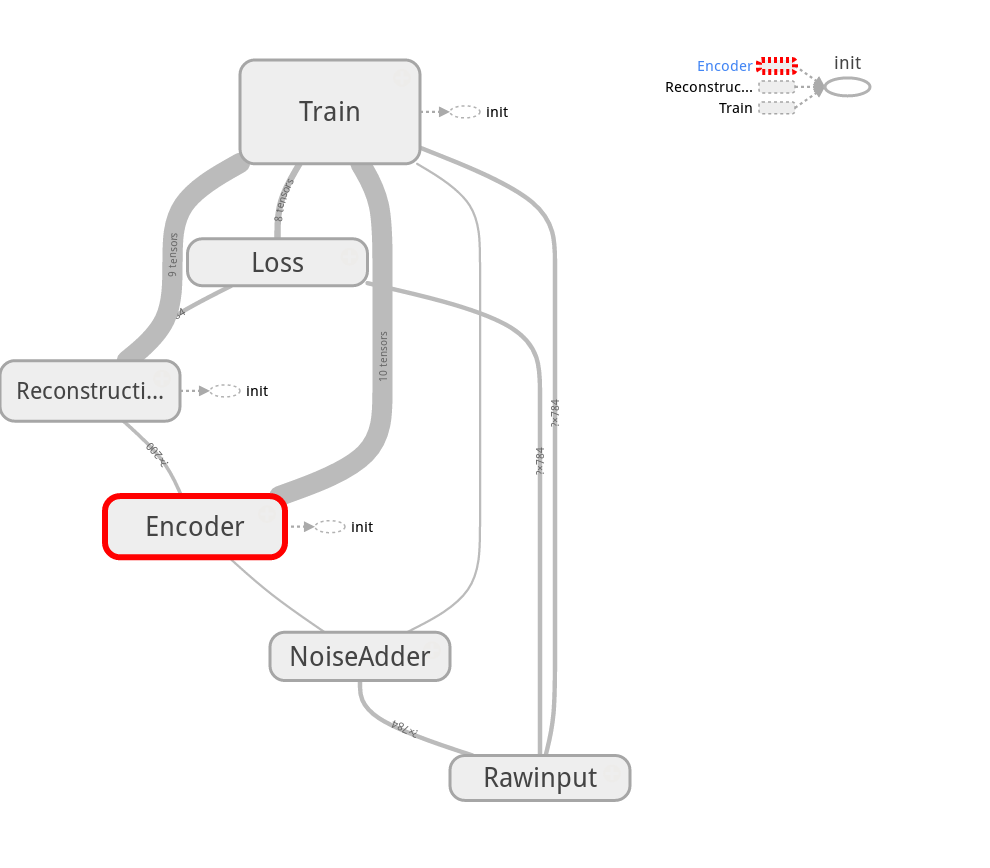
图结构实际实现
Version1:
导入包:
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
关闭日志警告:
级别2是警告信息忽略,级别3是错误信息忽略
# 关闭tensorflow的警告信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
均匀分布参数生成函数:
# 标准均匀分布
def xavier_init(fan_in,fan_out,constant = 1):
low = -constant * np.sqrt(6.0/(fan_in+fan_out))
hight = constant * np.sqrt(6.0/(fan_in+fan_out))
return tf.random_uniform((fan_in,fan_out),maxval=hight,minval=low,dtype=tf.float32)
网络类:
class AdditiveGuassianNoiseAutoencoder():
def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus,
optimzer=tf.train.AdamOptimizer(),scale=0.1):
# 网络参数
self.n_input = n_input
self.n_hidden = n_hidden
self.transfer = transfer_function # 激活函数
self.training_scale = scale # 噪声水平
network_weights = self._initialize_weights()
self.weights = network_weights # 网络结构
self.x = tf.placeholder(tf.float32, [None, self.n_input])
self.hidden = self.transfer(
tf.add(tf.matmul(self.x + scale * tf.random_normal((n_input,)),
self.weights['w1']), self.weights['b1']))
self.reconstruction = tf.add(tf.matmul(self.hidden, self.weights['w2']),
self.weights['b2']) # 训练部分
self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction, self.x), 2))
self.optimizer = optimzer.minimize(self.cost)
init = tf.global_variables_initializer()
self.sess = tf.Session()
self.sess.run(init) print('begin to run session... ...') def _initialize_weights(self):
all_weights = dict()
all_weights['w1'] = tf.Variable(xavier_init(self.n_input, self.n_hidden))
all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype=tf.float32))
all_weights['w2'] = tf.Variable(xavier_init(self.n_hidden, self.n_input))
all_weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype=tf.float32))
return all_weights
主函数:
AGN_AC = AdditiveGuassianNoiseAutoencoder(n_input=784, n_hidden=200,
transfer_function=tf.nn.softplus,
optimzer=tf.train.AdamOptimizer(learning_rate=0.01),
scale=0.01)
writer = tf.summary.FileWriter(logdir='logs', graph=AGN_AC.sess.graph)
writer.close()
图:

VersionV2
添加了命名空间,使节点更为清晰,但实际图结构显得凌乱,由于W&b的节点没有被划归到层节点下的关系
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os # 关闭tensorflow的警告信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 标准均匀分布
def xavier_init(fan_in,fan_out,constant = 1):
low = -constant * np.sqrt(6.0/(fan_in+fan_out))
hight = constant * np.sqrt(6.0/(fan_in+fan_out))
return tf.random_uniform((fan_in,fan_out),maxval=hight,minval=low,dtype=tf.float32) class AdditiveGuassianNoiseAutoencoder():
def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus,
optimzer=tf.train.AdamOptimizer(),scale=0.1):
# 网络参数
self.n_input = n_input
self.n_hidden = n_hidden
self.transfer = transfer_function # 激活函数
self.training_scale = scale # 噪声水平
network_weights = self._initialize_weights()
self.weights = network_weights # 网络结构
with tf.name_scope('Rawinput'): #<---
self.x = tf.placeholder(tf.float32, [None, self.n_input])
with tf.name_scope('NoiseAdder'): #<---
self.scale = tf.placeholder(dtype=tf.float32) #<---使用占位符取代了固定的scale,增加了feed量
self.noise_x = self.x + self.scale * tf.random_normal((n_input,)) #<---
with tf.name_scope('Encoder'): #<---
self.hidden = self.transfer(
tf.add(tf.matmul(self.noise_x, self.weights['w1']), self.weights['b1']))
with tf.name_scope('Reconstruction'): #<---
self.reconstruction = tf.add(
tf.matmul(self.hidden, self.weights['w2']), self.weights['b2']) # 训练部分
with tf.name_scope('Loss'): #<---
self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction, self.x), 2))
with tf.name_scope('Train'):
self.optimizer = optimzer.minimize(self.cost)
init = tf.global_variables_initializer()
self.sess = tf.Session()
self.sess.run(init) print('begin to run session... ...') def _initialize_weights(self):
all_weights = dict()
all_weights['w1'] = tf.Variable(xavier_init(self.n_input, self.n_hidden) ,name='weight1') #<---
all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype=tf.float32), name='bias1')
all_weights['w2'] = tf.Variable(xavier_init(self.n_hidden, self.n_input), name='weight2')
all_weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype=tf.float32), name='bias2')
return all_weights AGN_AC = AdditiveGuassianNoiseAutoencoder(n_input=784, n_hidden=200,
transfer_function=tf.nn.softplus,
optimzer=tf.train.AdamOptimizer(learning_rate=0.01),
scale=0.01)
writer = tf.summary.FileWriter(logdir='logs', graph=AGN_AC.sess.graph)
writer.close()
图:

Version3
保留字典结构存储W&b
但是把字典key&value生成拆开放在了每一层中
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os # 关闭tensorflow的警告信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 标准均匀分布
def xavier_init(fan_in,fan_out,constant = 1):
low = -constant * np.sqrt(6.0/(fan_in+fan_out))
hight = constant * np.sqrt(6.0/(fan_in+fan_out))
return tf.random_uniform((fan_in,fan_out),maxval=hight,minval=low,dtype=tf.float32) class AdditiveGuassianNoiseAutoencoder():
def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus,
optimzer=tf.train.AdamOptimizer(),scale=0.1):
# 网络参数
self.n_input = n_input
self.n_hidden = n_hidden
self.transfer = transfer_function # 激活函数
self.training_scale = scale # 噪声水平
self.weights = dict() #<---
# network_weights = self._initialize_weights()
# self.weights = network_weights # 网络结构
with tf.name_scope('Rawinput'):
self.x = tf.placeholder(tf.float32, [None, self.n_input])
with tf.name_scope('NoiseAdder'):
self.scale = tf.placeholder(dtype=tf.float32)
self.noise_x = self.x + self.scale * tf.random_normal((n_input,))
with tf.name_scope('Encoder'):
self.weights['w1'] = tf.Variable(xavier_init(self.n_input, self.n_hidden), name='weight1') #<---
self.weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype=tf.float32), name='bias1') #<---
self.hidden = self.transfer(
tf.add(tf.matmul(self.noise_x, self.weights['w1']), self.weights['b1']))
with tf.name_scope('Reconstruction'):
self.weights['w2'] = tf.Variable(xavier_init(self.n_hidden, self.n_input), name='weight2') #<---
self.weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype=tf.float32), name='bias2') #<---
self.reconstruction = tf.add(
tf.matmul(self.hidden, self.weights['w2']), self.weights['b2']) # 训练部分
with tf.name_scope('Loss'):
self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction, self.x), 2))
with tf.name_scope('Train'):
self.optimizer = optimzer.minimize(self.cost)
init = tf.global_variables_initializer()
self.sess = tf.Session()
self.sess.run(init) print('begin to run session... ...') # def _initialize_weights(self):
# all_weights = dict()
# all_weights['w1'] = tf.Variable(xavier_init(self.n_input, self.n_hidden) ,name='weight1')
# all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype=tf.float32), name='bias1')
# all_weights['w2'] = tf.Variable(xavier_init(self.n_hidden, self.n_input), name='weight2')
# all_weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype=tf.float32), name='bias2')
# return all_weights AGN_AC = AdditiveGuassianNoiseAutoencoder(n_input=784, n_hidden=200,
transfer_function=tf.nn.softplus,
optimzer=tf.train.AdamOptimizer(learning_rate=0.01),
scale=0.01)
writer = tf.summary.FileWriter(logdir='logs', graph=AGN_AC.sess.graph)
writer.close()
图:
总结:
1.参数变量使用字典保存提升规整性;
2.参数变量生成仍然要放在层中,可视化效果更好。
降噪自编码器完整程序
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os # 关闭tensorflow的警告信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 标准均匀分布
def xavier_init(fan_in,fan_out,constant = 1):
low = -constant * np.sqrt(6.0/(fan_in+fan_out))
hight = constant * np.sqrt(6.0/(fan_in+fan_out))
return tf.random_uniform((fan_in,fan_out),maxval=hight,minval=low,dtype=tf.float32) class AdditiveGuassianNoiseAutoencoder():
def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus,
optimzer=tf.train.AdamOptimizer(),scale=0.1):
# 网络参数
self.n_input = n_input
self.n_hidden = n_hidden
self.transfer = transfer_function # 激活函数
self.training_scale = scale # 噪声水平
self.weights = dict()
# network_weights = self._initialize_weights()
# self.weights = network_weights # 网络结构
with tf.name_scope('Rawinput'):
self.x = tf.placeholder(tf.float32, [None, self.n_input])
with tf.name_scope('NoiseAdder'):
self.scale = tf.placeholder(dtype=tf.float32)
self.noise_x = self.x + self.scale * tf.random_normal((n_input,))
with tf.name_scope('Encoder'):
self.weights['w1'] = tf.Variable(xavier_init(self.n_input, self.n_hidden), name='weight1') # <---
self.weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype=tf.float32), name='bias1')
self.hidden = self.transfer(
tf.add(tf.matmul(self.noise_x, self.weights['w1']), self.weights['b1']))
with tf.name_scope('Reconstruction'):
self.weights['w2'] = tf.Variable(xavier_init(self.n_hidden, self.n_input), name='weight2') # <---
self.weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype=tf.float32), name='bias2')
self.reconstruction = tf.add(
tf.matmul(self.hidden, self.weights['w2']), self.weights['b2']) # 训练部分
with tf.name_scope('Loss'):
self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction, self.x), 2))
with tf.name_scope('Train'):
self.optimizer = optimzer.minimize(self.cost)
init = tf.global_variables_initializer()
self.sess = tf.Session()
self.sess.run(init) print('begin to run session... ...') def partial_fit(self, X):
'''
训练并计算cost
:param X:
:return:
'''
cost, opt = self.sess.run([self.cost, self.optimizer],
feed_dict={self.x:X, self.scale:self.training_scale})
return cost def calc_cost(self, X):
'''
不训练,只计算cost
:param X:
:return:
'''
return self.sess.run(self.cost, feed_dict={self.x: X, self.scale: self.training_scale}) # 数据集预处理
def standard_scale(X_train, X_test): #<-----数据集预处理部分
'''
0均值,1标准差
:param X_train:
:param X_test:
:return:
'''
# 根据预估的训练集的参数生成预处理器
preprocessor = prep.StandardScaler().fit(X_train)
X_train = preprocessor.transform(X_train)
X_test = preprocessor.transform(X_test)
return X_train, X_test def get_random_block_from_data(data, batch_size):
'''
随机取一个batch的数据
:param data:
:param batch_size:
:return:
'''
start_index = np.random.randint(0, len(data) - batch_size)
return data[start_index:(start_index+batch_size)] # 展示计算图
AGN_AC = AdditiveGuassianNoiseAutoencoder(n_input=784, n_hidden=200,
transfer_function=tf.nn.softplus,
optimzer=tf.train.AdamOptimizer(learning_rate=0.01),
scale=0.01)
writer = tf.summary.FileWriter(logdir='logs', graph=AGN_AC.sess.graph)
writer.close() # 读取数据
mnist = input_data.read_data_sets('../Mnist_data/', one_hot=True)
X_train, X_test = standard_scale(mnist.train.images, mnist.test.images) n_samples = int(mnist.train.num_examples) # 训练样本总数
training_epochs = 20 # 训练轮数,1轮等于n_samples/batch_size
batch_size = 128 # batch容量
display_step = 1 # 展示间隔 # 训练
for epoch in range(training_epochs):
avg_cost = 0 # 平均损失
total_batch = int(n_samples/batch_size) # 每一轮中step总数
for i in range(total_batch):
batch_xs = get_random_block_from_data(X_train, batch_size)
cost = AGN_AC.partial_fit(batch_xs)
avg_cost += cost / batch_size
avg_cost /= total_batch if epoch % display_step == 0:
print('epoch : %04d, cost = %.9f' % (epoch+1, avg_cost)) # 计算测试集上的cost
print('Total coat:', str(AGN_AC.calc_cost(X_test)))
引入了数据预处理机制:
import sklearn.preprocessing as prep # 数据集预处理
def standard_scale(X_train, X_test): #<-----一个新的尝试
'''
0均值,1标准差
:param X_train:
:param X_test:
:return:
'''
# 根据预估的训练集的参数生成预处理器
preprocessor = prep.StandardScaler().fit(X_train)
X_train = preprocessor.transform(X_train)
X_test = preprocessor.transform(X_test)
return X_train, X_test
因为就是个范例而已,所以并没有加入更多的步骤。
输出:
Python 3.6.0 |Anaconda 4.3.1 (64-bit)| (default, Dec 23 2016, 12:22:00)
Type "copyright", "credits" or "license" for more information.
IPython 5.1.0 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
PyDev console: using IPython 5.1.0
Running /home/hellcat/PycharmProjects/data_analysis/TensorFlow/autoencodes/denoise.py
Backend Qt5Agg is interactive backend. Turning interactive mode on.
begin to run session... ...
Extracting ../Mnist_data/train-images-idx3-ubyte.gz
Extracting ../Mnist_data/train-labels-idx1-ubyte.gz
Extracting ../Mnist_data/t10k-images-idx3-ubyte.gz
Extracting ../Mnist_data/t10k-labels-idx1-ubyte.gz
epoch : 0001, cost = 172728.840323210
epoch : 0002, cost = 384090.340043217
epoch : 0003, cost = 1424137.733514817
epoch : 0004, cost = 252195.476644165
epoch : 0005, cost = 1989602.406287275
epoch : 0006, cost = 82078.567135613
epoch : 0007, cost = 4571607.288953234
epoch : 0008, cost = 12936386.999440582
epoch : 0009, cost = 192551.124642752
epoch : 0010, cost = 40848.185927740
epoch : 0011, cost = 2998.114711095
epoch : 0012, cost = 15210.583374379
epoch : 0013, cost = 38411.792979990
epoch : 0014, cost = 5556.733809144
epoch : 0015, cost = 35625.806443790
epoch : 0016, cost = 1274942.135287910
epoch : 0017, cost = 214436.171889868
epoch : 0018, cost = 29740.634501637
epoch : 0019, cost = 1136.356513888
epoch : 0020, cost = 2248.695473340
Total coat: 4.2886e+06
『TensorFlow』降噪自编码器设计的更多相关文章
- 『TensorFlow』读书笔记_降噪自编码器
『TensorFlow』降噪自编码器设计 之前学习过的代码,又敲了一遍,新的收获也还是有的,因为这次注释写的比较详尽,所以再次记录一下,具体的相关知识查阅之前写的文章即可(见上面链接). # Aut ...
- 『TensorFlow』专题汇总
TensorFlow:官方文档 TensorFlow:项目地址 本篇列出文章对于全零新手不太合适,可以尝试TensorFlow入门系列博客,搭配其他资料进行学习. Keras使用tf.Session训 ...
- 『TensorFlow』TFR数据预处理探究以及框架搭建
一.TFRecord文件书写效率对比(单线程和多线程对比) 1.准备工作 # Author : Hellcat # Time : 18-1-15 ''' import os os.environ[&q ...
- 『TensorFlow』DCGAN生成动漫人物头像_下
『TensorFlow』以GAN为例的神经网络类范式 『cs231n』通过代码理解gan网络&tensorflow共享变量机制_上 『TensorFlow』通过代码理解gan网络_中 一.计算 ...
- 『TensorFlow』滑动平均
滑动平均会为目标变量维护一个影子变量,影子变量不影响原变量的更新维护,但是在测试或者实际预测过程中(非训练时),使用影子变量代替原变量. 1.滑动平均求解对象初始化 ema = tf.train.Ex ...
- 『TensorFlow』流程控制
『PyTorch』第六弹_最小二乘法对比PyTorch和TensorFlow TensorFlow 控制流程操作 TensorFlow 提供了几个操作和类,您可以使用它们来控制操作的执行并向图中添加条 ...
- 『TensorFlow』梯度优化相关
tf.trainable_variables可以得到整个模型中所有trainable=True的Variable,也是自由处理梯度的基础 基础梯度操作方法: tf.gradients 用来计算导数.该 ...
- 『TensorFlow』模型保存和载入方法汇总
『TensorFlow』第七弹_保存&载入会话_霸王回马 一.TensorFlow常规模型加载方法 保存模型 tf.train.Saver()类,.save(sess, ckpt文件目录)方法 ...
- 『TensorFlow』命令行参数解析
argparse很强大,但是我们未必需要使用这么繁杂的东西,TensorFlow自己封装了一个简化版本的解析方式,实际上是对argparse的封装 脚本化调用tensorflow的标准范式: impo ...
随机推荐
- 洛谷P1021邮票面值设计 [noip1999] dp+搜索
正解:dfs+dp 解题报告: 传送门! 第一眼以为小凯的疑惑 ummm说实话没看标签我还真没想到正解:D 本来以为这么多年前的noip应该不会很难:D 看来还是太菜了鸭QAQ 然后听说题解都可以被6 ...
- ajax验证用户名是否被注册 ; ajax提交form表单
register.html 文件代码: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" &quo ...
- 格式化输出&初始编码&运算符
一:格式化输出 % %d %s %为占位符 S替换的内容的类型为字符型 d替换的内容为整型 若在格式化输出的时候需要正常用到% 则表示时用两个%%表示 如: name = input( ...
- 使用spring data solr 实现搜索关键字高亮显示
后端实现: @Service public class ItemSearchServiceImpl implements ItemSearchService { @Autowired private ...
- sublime----------快捷键的记录
1.鼠标选中多行,按下 Ctrl Shift L (Command Shift L) 即可同时编辑这些行: 2.鼠标选中自定义的多行,ctrl+鼠标左键
- Oracle 26表空间的管理
一.查看用户表空间 熟悉与表空间相关的数据字典 查看用户的表空间 相关的数据字典:(用于查询数据库信息的数据库表)dba_tablespaces (管理员级别的表空间的描述信息) User_table ...
- Software Testing 3
Questions: • 7. Use the following method printPrimes() for questions a–d. 基于Junit及Eclemma(jacoco)实现一 ...
- 浅探网络1---tcp协议详解(三次握手和四次挥手)
TCP协议是网络多层协议中运输层的最重要的协议之一,运输层是两台主机的进程之间的通信.除了TCP还有一个是UDP协议(用户数据包协议) TCP全称是Transmission Control Proto ...
- vue全局使用axios插件请求ajax
vue全局使用axios插件请求ajax Vue 原本有一个官方推荐的 ajax 插件 vue-resource,但是自从 Vue 更新到 2.0 之后,官方宣布停止更新vue-resource,并推 ...
- 事件冒泡以及onmouseenter 和 onmouseover 的不同
1. onmouseenter onmouseenter 事件在鼠标指针移动到元素上时触发. 该事件通常与 onmouseleave 事件一同使用, 在鼠标指针移出元素上时触发. onmouseent ...