目标检测(五)YOLOv1—You Only Look Once:Unified,Real-Time Object Detection
之前的目标检测算法大都采用proposals+classifier的做法(proposal提供位置信息,分类器提供类别信息),虽然精度很高,但是速度比较慢,也可能无法进行end-to-end训练。而该论文提出的yolo网络是一个统一的single network,能够进行端到端的优化。作者说到,该结构特别快,base YOLO model可以做到每秒实时处理45帧图像。另外,yolo的smaller version,Fast YOLO,处理速度高达每秒155帧,虽然mAP有所下降,但是仍是其它实时检测算法的2倍。在效果上,与state-of-the-art 算法相比,YOLO的定位误差较高,不过分类精度相比有所提升。yolo的大致结构如Fig.1所示:

yolo的特点如下:
- yolo非常快。作者在设计网络时将detection视为回归问题,没有使用复杂的pipelines,而是仅仅使用了一个neural network,所以网络的速度很快;
- 与RCNN和Fast RCNN采用SS提取到的region proposals进行网络optimization的方式不同,yolo是在整幅图像上进行训练;
- yolo可以端到端地直接对detection performance进行优化,其训练与Fast RCNN都是single-stage(RCNN的训练是在multi-stage pipelines,因为存在SVMs等部分);
- yolo在进行预测时可以理解整幅图像。与基于sliding window和region proposal的技术不同,yolo在训练和测试时能够”看到“entire image,所以yolo实际上理解了每个类别的上下文信息(context-tual information)和特征。也正是因为这个原因,yolo的分类精度比Fast RCNN高;
- yolo学习到的是目标的泛化表示(generalizable representations)。当用在natural images上训练的yolo在art-work上测试时,yolo的表现远超其它检测方法。因为Yolo的泛化能力非常强,所以更容易应用于新的领域或输入;
- yolov1没有使用anchor boxes,只是指定每个cell预测两个bounding boxes。由于没有先验知识anchor boxes,在训练时不需要根据 anchor boxes 调整训练集中 ground-truth boxes 的size,直接使用即可。
yolo的缺陷:
- 虽然yolo能够快速地识别图像中的目标,但是它很难精确定位一些目标,比如相互靠得很近物体(紧挨且中点在一个cell)、很小的群体目标(飞鸟等)。这是因为一个Grid cell只预测两个bounding boxes,并且每个cell只能有一类目标;
- 当测试时图像中的object以不常见的aspect ratio(长宽比)或者其它情况出现时,yolo表现的泛化能力很差;
- 虽然损失函数缓解大小bounding boxes定位误差权重相同的问题,但是影响仍然存在
Network Design
网络前部的convolutional layers(24层)用于从原始图像中提取特征,后面的全连接层(2层)用来预测输出概率和坐标。
yolo的网络结构参考了GoogLeNet模型,但是作者没有使用GoogLeNet模型中的inception modules,而是简单的采用了后面接着3*3 convolutional layers的1*1 reduction layers(降维层)。这种做法与NIN论文中提到的类似。整个网络如Fig.3所示(Fig.3中的层注释有点问题,顺序不对,红框之前的应该属于第二块注释):

从Fig.3中可以看到,网络输入的是分辨率为448*448的图像,输出是7*7*30(VOC)的tensor。
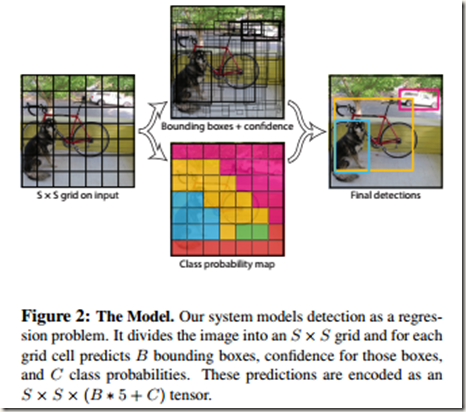
yolo将输入图像分割成S*S的网格,每个网格负责检测中心落在其中的Objects。检测时,每个网格预测B个bounding boxes、B个对应的confidence scores以及C个条件类概率。
每个box的信息包括x, y, w, h, confidence。其中,x和y是box相对所在grid cell的bounds的中心坐标;w和h是预测到的相对整幅图像的宽和高;而confidence则反映了该box包含object的几率以及预测到的box的位置精确性,所以定义为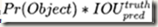 。训练时如果cell内不存在ground truth box,那么Pr(Object)=0,confidence自然为0,反之为1;如果predicted box与ground truth box的IOU较高,则说明预测的box位置比较精确。当Pr(Object)=1时,confidence就等于IOU值。
。训练时如果cell内不存在ground truth box,那么Pr(Object)=0,confidence自然为0,反之为1;如果predicted box与ground truth box的IOU较高,则说明预测的box位置比较精确。当Pr(Object)=1时,confidence就等于IOU值。
至于条件类别概率,可以表示为Pr(Classi|Object),即在该cell包含object的情况下,box属于各类别的概率,因此每个cell的conditional class probabilities数目等于类别数。需要注意的是,是每个grid cell 而不是每个box有C个类别概率。
这样,在测试时通过将预测到的conditional class probabilities与cell内每个box的confidence相乘就可以得到每个box的指定类别的confidence scores。如下:

很明显,confidence scores表示的是每个box属于各个类别的几率与定位精度。
在每个cell内网络预测B个boxes,C个条件类别概率,而每个box包含x,y,w,h,confidence 5个信息,所以每个grid cell对应(B*5+C)个值。前面又提到,yolo将输入图像分割成S*S的网格,不难得出网络的最终预测输出共有S*S*(B*5+C)个值(也是网络输出张量的shape)。以VOC数据集(C=20)为例,yolo在该数据集上进行评估时使用S=7,B=2,得到的最终输出就是一个7*7*30的tensor。下图可以清晰地展现输出的组成(转自):
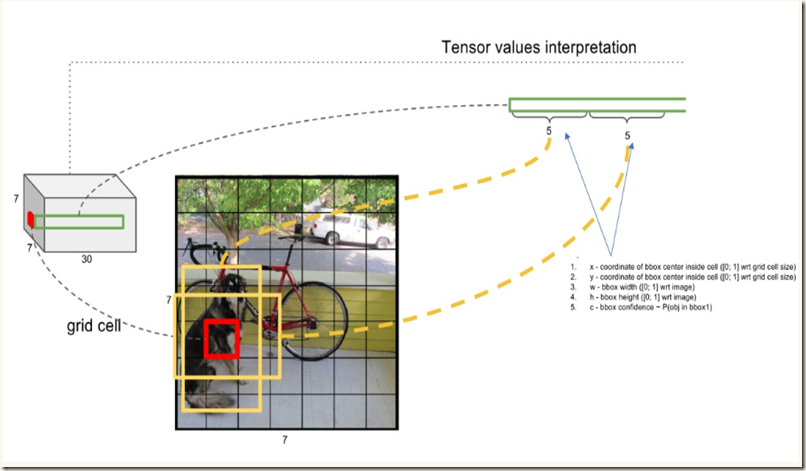
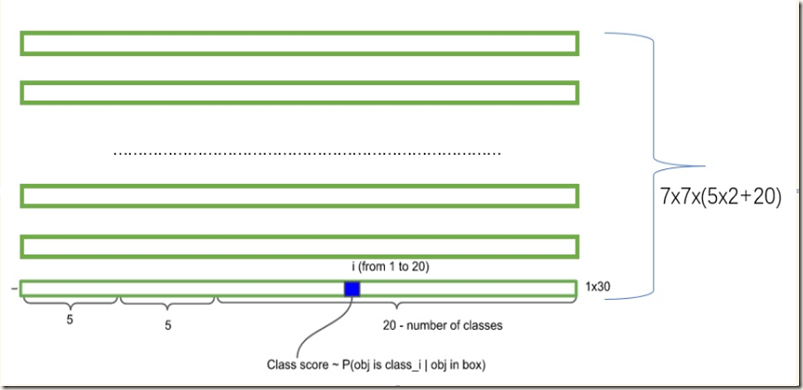
Training
作者先使用Fig.3中前20层卷积层+1层average-pooling layer+1层fully connected layer组成的网络在ImageNet上进行分类器预训练,输入图像尺寸选择为224*224.
预训练完成后,将上述预训练好的网络转换成执行检测任务的model,做法是:在预训练后的前20层卷积层后面添加4层卷积层+2层全连接层,权重随机初始化(参考Object detection networks on convolutional feature maps)。另外,为了获得细粒度的视觉信息,将输入图像的分辨率由224*224提高到448*448。下图展示了整个模型的结构,其中梯形框代表预训练后的20层卷积层,C.R代表添加的4层卷积层,FCR和FC表示添加的2层全连接层(R表示使用斜率为0.1的Leaky Rectified Linear activation,最后一层FC使用线性激活函数):
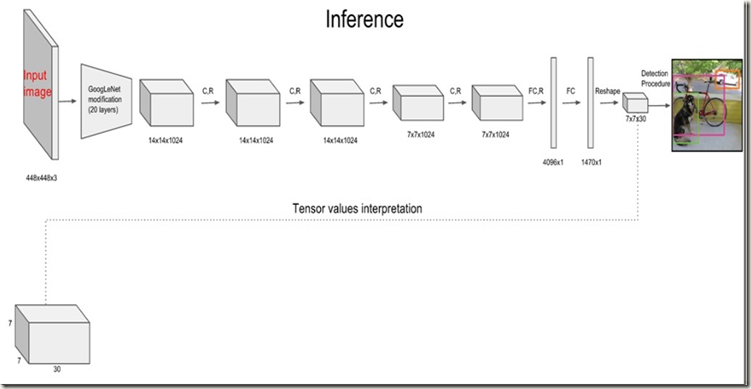
网络的最后一层全连接层同时预测出类别概率和bouding box坐标。不过,输出的box坐标xy被参数化成所在grid cell的位置的offsets,因而所在范围是[0,1];同时,box的长宽也被输入图像的长宽归一化,自然也是在[0,1]范围内。在训练时,数据的真实输出也会被调整成相同的形式,以便于计算损失。
在损失函数设计方面,作者希望坐标(x, y, w, h)、confidence、classification这三个方面达到很好的均衡。虽然使用sum-squared error 会很容易优化,但简单地全部采用sum-squared error loss来计算会有如下不足:1)8维的定位误差和20维的分类误差同样重要显然不合理;2)在图像中,很多cells不包含任何object,这就会将这些网格中boxes的confidence scores push为0,相比于较少的有object的网格,这种做法是overpowering的(我暂时理解为不平衡),这会导致网络不稳定甚至发散。对此,作者的采取的做法是:增加坐标预测的损失权重,同时降低那些不包含objects的boxes带来的confidence loss权重,具体做法是引入两个参数λcoord=5、λnoobj = 0.5;另外,那些有object的bbox的confidence loss和classification loss的weight正常取1。这样损失函数就分成了4部分。
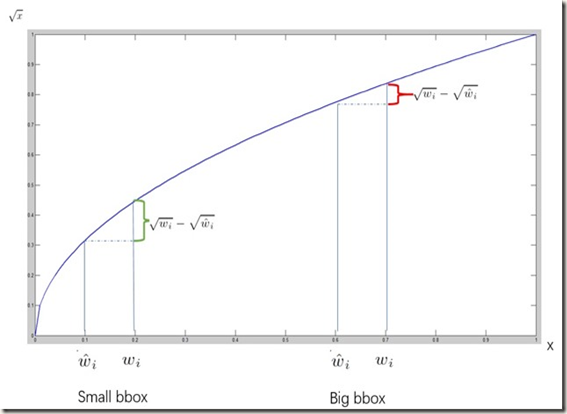
此外,在对不同大小的boxes进行预测时,小的boxes预测偏一点比大的boxes预测偏一点更加明显,而sum-square error loss对同样的偏移loss是一样的。为了缓解这个问题,作者使用了一个巧妙的办法,就是将box的width和height取平方根代替原本的height和width。如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大:
在训练时,一个grid cell预测多个bounding box,我们希望每个object只有一个bounding box负责。具体做法是选择与ground true box的IOU最大的bounding box负责该object的预测。这种做法称为bounding box prediction的specialization。每个预测器会对特定(sizes,aspect ratio or classed of object)的ground true box预测的越来越好。
至此,可以得出训练使用的multi-part loss function,一共分为四部分,如下图:
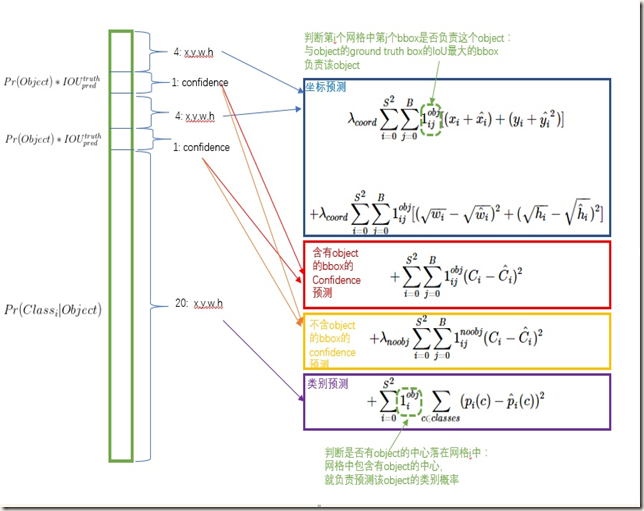
需要注意的是,loss function只处罚(penalizes)有object的grid cell的classification error,同样,也只处罚对ground true box负责的bounding boxes的定位误差,上图中有显示。这很好理解,不存在object的cell和bbox根本就没有误差。
论文中训练的细节:
- 在取自PASCAL VOC 2007和2012的训练集和验证集上训练网络135 epochs,然后仍然在VOC 2007和2012数据集上进行测试。在训练过程中batch size 为64,冲量为0.9,衰减因子为0.0005;
- learning rate schedule如下:在最初的若干epochs内,缓慢的将学习速率从e-3提高到e-2。如果训练之初就使用较高的学习速率,可能会因为梯度不稳定导致模型发散。然后在继续使用e-2训练75 epochs后再使用e-3训练30 epochs,最后再使用e-4训练30 epochs
- 为了避免过拟合,作者使用了Dropout和data augmentation两种方法。网络中在第一个全连接层之后使用了rate=0.5的dropout layer,目的是prevents co-adaptation between layers(防止层间的共同作用,参见论文)。在数据增强时,随机scale和translation原始图像的尺寸的20%。同时,还在HSV颜色空间对图像的曝光度和饱和度随机调整最高1.5倍。
Testing(Inference):
与训练相同,对一幅图像的测试也只需要经过a single network。
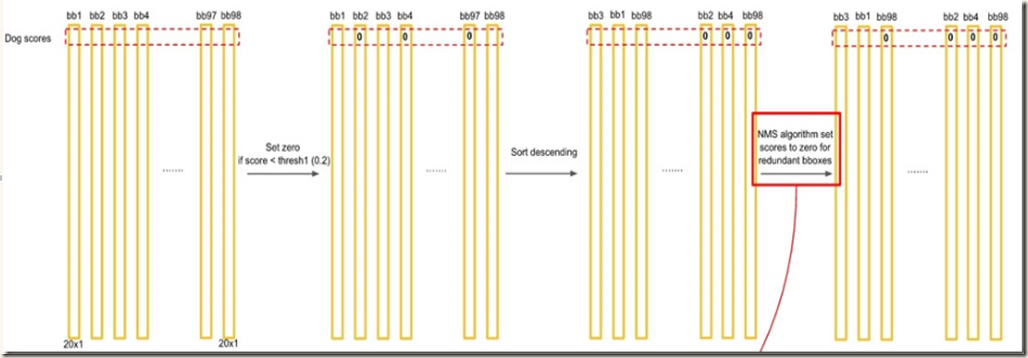
测试时输出tensor的shape为(S, S, B*(4+1)+C),需要对其进行翻译(interpretation)才能得出bounding boxes和类别信息。翻译时,先按照如下公式计算出各boxes的confidence scores,然后根据设定的阈值滤掉得分低的boxes,最后使用NMS来剔除冗余的bounding boxes:

之所以使用非极大值抑制,是因为预测的结果中可能多个bounding box对应一个ground true box,比如一些大object和靠近多个cells的object可能会被多个cells定位,这时就需要使用Non-maximal suppresion来剔除冗余的bounding boxes。论文中说到,NMS在mAP上提升了2%-3%。
翻译过程如下列图片所示:
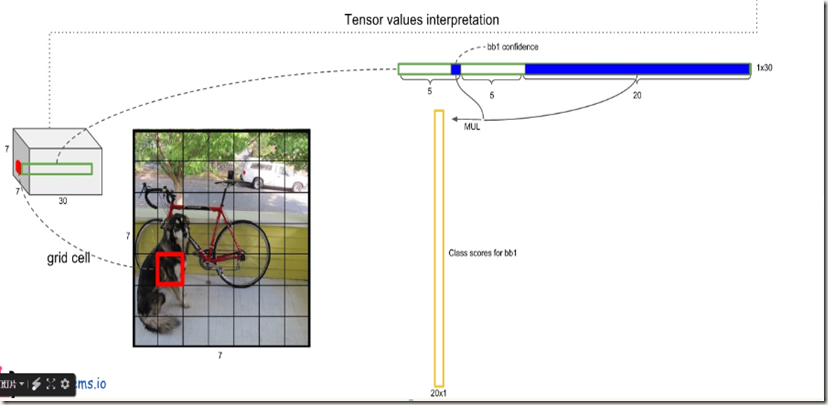

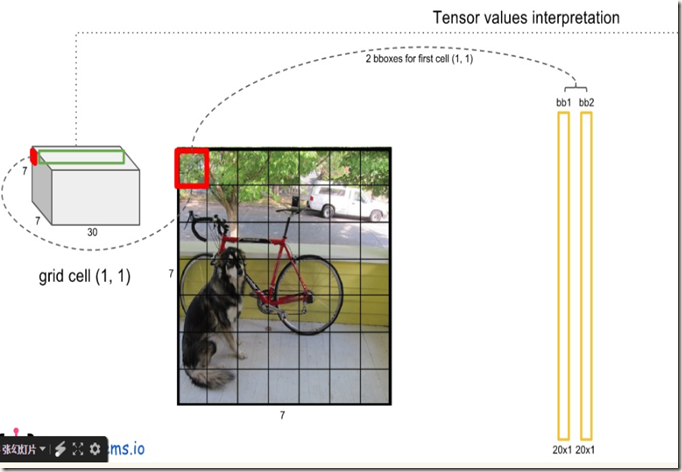
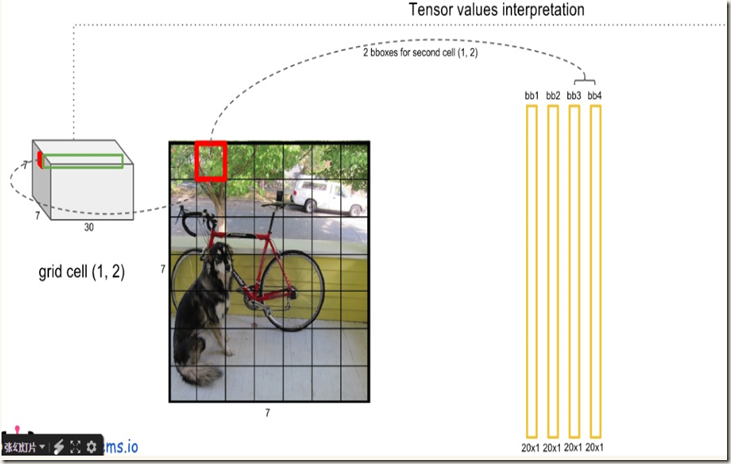
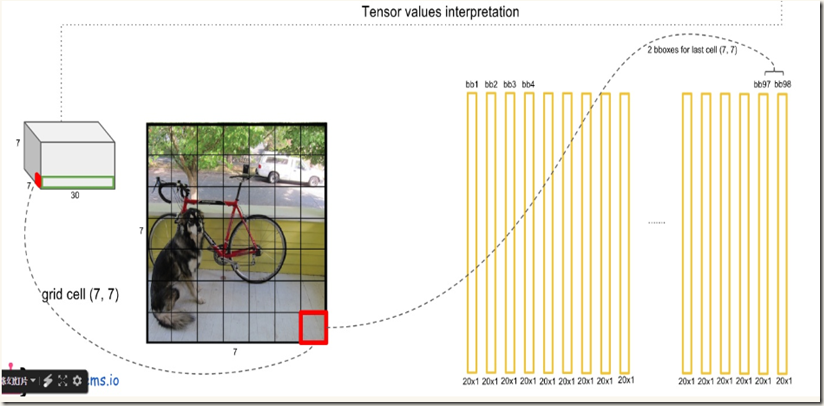
得到每个bbox的class-specific confidence score以后(初步得到7*7*2=98个boxes),设置阈值,滤掉得分低的boxes(有些boxes不含有object),对保留的boxes进行非极大值抑制处理,就得到最终的检测结果。
参考文章:
- 图解YOLO
- 深刻解读YOLO V1(图解)
- YOLO:实时目标检测
- darknet版源码
- tensorflow版源码
- YOLO源码解析
- 论文You Only Look Once: Unified, Real-Time Object Detection
目标检测(五)YOLOv1—You Only Look Once:Unified,Real-Time Object Detection的更多相关文章
- 三维目标检测论文阅读:Deep Continuous Fusion for Multi-Sensor 3D Object Detection
题目:Deep Continuous Fusion for Multi-Sensor 3D Object Detection 来自:Uber: Ming Liang Note: 没有代码,主要看思想吧 ...
- 目标检测算法—YOLO-V1
为什么会叫YOLO呢? YOLO:you only look once.只需要看一眼,就可以检测识别出目标,主要是突出这个算法 快 的特点.(原文:Yolo系列之前的文章:主要是rcnn系列的,他们的 ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN,Faster R-CNN
基于深度学习的目标检测技术演进:R-CNN.Fast R-CNN,Faster R-CNN object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.obj ...
- 【目标检测】Cascade R-CNN 论文解析
目录 0. 论文链接 1. 概述 2. 网络结构的合理性 3. 网络结构 4. 参考链接 @ 0. 论文链接 Cascade R-CNN 1. 概述 这是CVPR 2018的一篇文章,这篇文章也为 ...
- CVPR2020论文介绍: 3D 目标检测高效算法
CVPR2020论文介绍: 3D 目标检测高效算法 CVPR 2020: Structure Aware Single-Stage 3D Object Detection from Point Clo ...
- 3D目标检测(CVPR2020:Lidar)
3D目标检测(CVPR2020:Lidar) LiDAR-Based Online 3D Video Object Detection With Graph-Based Message Passing ...
- 目标检测复习之Anchor Free系列
目标检测之Anchor Free系列 CenterNet(Object as point) 见之前的过的博客 CenterNet笔记 YOLOX 见之前目标检测复习之YOLO系列总结 YOLOX笔记 ...
- CVPR 2020几篇论文内容点评:目标检测跟踪,人脸表情识别,姿态估计,实例分割等
CVPR 2020几篇论文内容点评:目标检测跟踪,人脸表情识别,姿态估计,实例分割等 CVPR 2020中选论文放榜后,最新开源项目合集也来了. 本届CPVR共接收6656篇论文,中选1470篇,&q ...
随机推荐
- IDEA使用笔记(九)——设置文件注释
方式一:后写文件描述信息 1:设置——如下图所示 2:验证——创建个类试试 3:验证——结果如下 4:其他,所有注释模版中包含 #parse("File Header.java") ...
- 转:一千行MYSQL 笔记
原文地址: https://shockerli.net/post/1000-line-mysql-note/ /* 启动MySQL */ net start mysql /* 连接与断开服务器 */ ...
- Beautiful Soup 解决爬虫编码格式问题,Beautiful Soup编码格式
一. 为什么要用解析框架 bs4 我觉得爬虫最难得问题就是编码格式,因为你不知道要爬取目标网站的编码格式,有可能是Unicode,utf-8, ASCII , gbk格式,但是使用Beautiful ...
- SNF软件开发机器人-子系统-功能-数据录入方式
数据录入方式 数据录入方式是指新增数据时是直接在列表上添加或者弹出表单增加数据. 1.效果展示: (1)列表 (2)表单弹出 2.使用说明: 打开显示页面,点击开发者选项的简单配置按钮.在功能表信息中 ...
- Cocos 编译android-studio
3.15.1 之前: http://www.jianshu.com/p/ac2bac4734b8 http://www.jianshu.com/p/3d0cc85460d1 在工程项目下 运行 coc ...
- C语言——数组名、取数组首地址的区别(一)
目录: 1. 开篇 2. 论数组名array.&array的区别 3. array.&array的区别表现在什么地方 4. 讨论 5. 参考 1.开篇 很多博客和贴吧都有讨论这个话题, ...
- github 搜索
1.明确搜索仓库标题.仓库描述.README GitHub 提供了便捷的搜索方式,可以限定只搜索仓库的标题.或者描述.README等. 以Spring Cloud 为例,一般一个仓库,大概是这样的 其 ...
- 深入理解String类详解
1.Stringstr = "eee" 和String str = new String("eee")的区别 先看一小段代码, 1 public static ...
- IntelliJ IDEA License Server 安装使用 Mac篇
一.下载 IntelliJ IDEA 是Java开发利器,用社区版不爽,干催就用旗舰版,这个是收费的,需要licence. IntelliJ IDEA下载地址:https://www.jetbrai ...
- ZIP解压缩工具类
import java.io.File; import org.apache.tools.ant.Project; import org.apache.tools.ant.taskdefs.Expan ...