洗礼灵魂,修炼python(58)--爬虫篇—【转载】urllib3模块
urllib3
1.简介
urllib3相比urllib,urlib2,又有些一些新的功能,可以实现很多东西,而这个模块有点特殊的是,并且还可以同时存在于python2和python3,但说实话,用的真的很少的。
2.方法/属性

3.常用方法/属性解析
由于用的很少,所以相关资料也很少,我反正是很少用,要嘛就用urllib,urlib2,要嘛直接用python3里的urllib包,或者直接用第三方模块requests。说到requests,就是由于有requests,urllib3用的才少,因为urlib3里有的功能,requests基本都有,urllib3功能还是挺实用的,不过用的真的不是很多。但是urllib3模块的用法还是讲着走的对吧,庆幸的是,我发现博客园里居然有大佬更过urllib3模块的博文,那么我就直接转载这大佬的了,感兴趣的可以看下,讲得很不错。
作者:Victor 原文链接:传送门(如果原作者有任何异议,请联系我立即删除)
详细内容:
Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库里所没有的重要特性:
1、 线程安全
2、 连接池
3、 客户端SSL/TLS验证
4、 文件分部编码上传
5、 协助处理重复请求和HTTP重定位
6、 支持压缩编码
7、 支持HTTP和SOCKS代理
8、 100%测试覆盖率
Urllib3功能非常强大,但是用起来却十分简单:

安装:
Urllib3 能通过pip来安装:
$pip install urllib3
你也可以在github上下载最新的源码,解压之后进行安装:
$git clone git://github.com/shazow/urllib3.git
$python setup.py install
urllib3的使用:
生成请求(request):
首先,你必须导入urllib3模块:

然后你需要一个PoolManager实例来生成请求,由该实例对象处理与线程池的连接以及线程安全的所有细节,不需要任何人为操作:

通过request()方法创建一个请求:

request()方法返回一个HTTPResponse对象。
你还可以通过request()方法向请求(request)中添加一些其他信息,如:

请求(request)中的数据项(request data)可包括:
Headers:
在request()方法中,可以定义一个字典类型(dictionary),并作为headers参数传入:
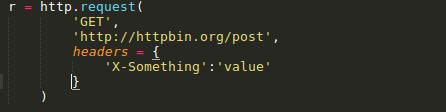
Query parameters:
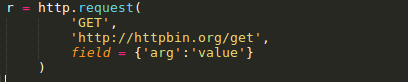
对于GET、HEAD和DELETE请求,可以简单的通过定义一个字典类型作为fields参数传入即可:
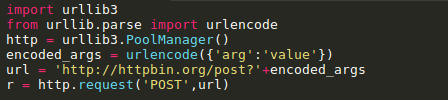
对于POST和PUT请求(request),需要手动对传入数据进行编码,然后加在URL之后:
Form data:
对于PUT和POST请求(request),urllib3会自动将字典类型的field参数编码成表格类型.
JSON:
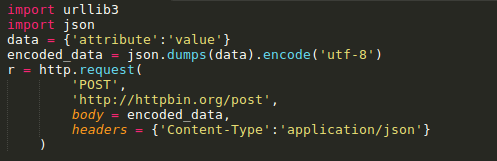
在发起请求时,可以通过定义body 参数并定义headers的Content-Type参数来发送一个已经过编译的JSON数据:
Files & binary data:
使用multipart/form-data编码方式上传文件,可以使用和传入Form data数据一样的方法进行,并将文件定义为一个元组的形式 (file_name,file_data):
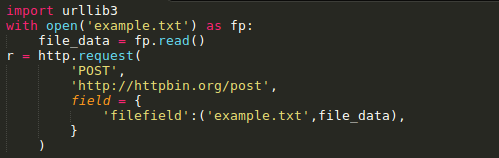
文件名(filename)的定义不是严格要求的,但是推荐使用,以使得表现得更像浏览器。同时,还可以向元组中再增加一个数据来定义文件的 MIME类型:
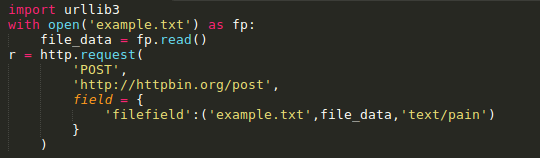
如果是发送原始二进制数据,只要将其定义为body参数即可。同时,建议对header的Content-Type参数进行设置:

Timeout :
使用timeout,可以控制请求的运行时间。在一些简单的应用中,可以将timeout参数设置为一个浮点数:

要进行更精细的控制,可以使用Timeout实例,将连接的timeout和读的timeout分开设置:

如果想让所有的request都遵循一个timeout,可以将timeout参数定义在PoolManager中:

或者

当在具体的request中再次定义timeout时,会覆盖PoolManager层面上的timeout。
请求重试(retrying requests):
Urllib3 可以自动重试幂等请求,原理和handles redirect一样。可以通过设置retries参数对重试进行控制。Urllib3默认进行3次请求重 试,并进行3次方向改变。
给retries参数定义一个整型来改变请求重试的次数:

关闭请求重试(retrying request)及重定向(redirect)只要将retries定义为False即可:

关闭重定向(redirect)但保持重试(retrying request),将redirect参数定义为False即可:

要进行更精细的控制,可以使用retry实例,通过该实例可以对请求的重试进行更精细的控制。
例如,进行3次请求重试,但是只进行2次重定向:

如果想让所有请求都遵循一个retry策略,可以在PoolManager中定义retry参数:

或者

当在具体的request中再次定义retry时,会覆盖 PoolManager层面上的retry。
洗礼灵魂,修炼python(58)--爬虫篇—【转载】urllib3模块的更多相关文章
- Python学习—基础篇之常用模块
常用模块 模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要 ...
- Python学习—爬虫篇之破解ntml登陆问题
之前帮公司爬取过内部的一个问题单网站,要求将每个问题单的下的附件下载下来.一开始的时候我就遇到一个破解登陆验证的大坑...... (╬ ̄皿 ̄)=○ 由于在公司使用的都是内网,代码和网站的描述 ...
- Python学习——爬虫篇
requests 使用requests进行爬取 下面是我编写的第一个爬虫的脚本 import requests # 导入reques ...
- python网络爬虫之二requests模块
requests http请求库 requests是基于python内置的urllib3来编写的,它比urllib更加方便,特别是在添加headers, post请求,以及cookies的设置上,处理 ...
- 进击python第4篇:初探模块
模块,用一砣代码实现了某个功能的代码集合,任何python程序都可以作为模块导入,n个 .py 文件组成的代码集合就称为模块. but 为什么要引入模块概念?主要原因是代码重用(code reuse) ...
- python网络爬虫之三re正则表达式模块
""" re正则表达式,正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的 一些特定字符,及这些特定字符的组合,组成一个"规则字符串",然后用 ...
- 【python网络爬虫】之requests相关模块
python网络爬虫的学习第一步 [python网络爬虫]之0 爬虫与反扒 [python网络爬虫]之一 简单介绍 [python网络爬虫]之二 python uillib库 [python网络爬虫] ...
- 洗礼灵魂,修炼python(71)--爬虫篇—【转载】xpath/lxml模块,爬虫精髓讲解
Xpath,lxml模块用法 转载的原因和前面的一样,我写的没别人写的好,所以我也不浪费时间了,直接转载这位崔庆才大佬的 原帖链接:传送门 以下为转载内容: --------------------- ...
- 洗礼灵魂,修炼python(52)--爬虫篇—【转载】爬虫工具列表
与爬虫相关的常用模块列表. 原文出处:传送门链接 网络 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pycurl). pycurl – 网络 ...
随机推荐
- 【原创】InputStream has already been read - do not use InputStreamResource if a stream needs to be read multiple times
一.背景 基于SpringBoot 构建了一个http文件下载服务,检查tomcat access 发现偶尔出现500 状态码的请求,检查抛出的异常堆栈 2019-03-20 10:03:14,273 ...
- scrapy 框架入门
运行流程 官网:https://docs.scrapy.org/en/latest/intro/overview.html 流程图如下: 组件 1.引擎(EGINE):负责控制系统所有组件之间的数据流 ...
- spring boot 上传文件
spring.servlet.multipart.max-file-size=23KBspring.servlet.multipart.maxRequestSize=23KB <form act ...
- vue-cli3.0 升级记录
年三十时 vue2.6 发布,向 3.0 看齐,说明 3.0 不远了.作为开发者也应该为vue3.0 做点准备.首先是把 vue-cli 升级到 3.x ,在这记录下 vue-cli2.x 升级 vu ...
- python常用函数和方法 - 备忘
语法语句篇 除法运算(精确运算和截断运算) 在python2中,除法运算通常是截断除法.什么是截断除法: >>> 3/4 0 # 自动忽略小数项 要是想 得到正确结果 怎么办呢? m ...
- java实现网页结构分析列表发现
现在的网站千奇百怪,什么样格式的都有,需要提取网页中的列表数据,有时候挨个分析处理很头疼,本文是一个页面结构分析的程序,可以分析处理页面大致列表结构. 废话不多说,我也不会说,show me code ...
- 交换路由中期测验20181226(动态路由配置与重分发、NAT转换、ACL访问控制列表)
测试拓扑: 接口配置信息 HostName 接口 IP地址 网关 Server 0 Fa0 172.16.15.1/24 172.16.15.254 Server 1 Fa0 100.2.15.200 ...
- 获取C#中方法的执行时间及其代码注入
在优化C#代码或对比某些API的效率时,通常需要测试某个方法的运行时间,可以通过DateTime来统计指定方法的执行时间,也可以使用命名空间System.Diagnostics中封装了高精度计时器Qu ...
- JVM笔记11-类加载器和OSGI
一.JVM 类加载器: 一个类在使用前,如何通过类调用静态字段,静态方法,或者new一个实例对象,第一步就是需要类加载,然后是连接和初始化,最后才能使用. 类从被加载到虚拟机内存中开始,到卸载出内存为 ...
- leetcode — 4sum
import java.util.Arrays; import java.util.HashSet; import java.util.Set; /** * Source : https://oj.l ...