spark完整的数据倾斜解决方案
1、数据倾斜的原理
2、数据倾斜的现象
3、数据倾斜的产生原因与定位
在执行shuffle操作的时候,大家都知道,我们之前讲解过shuffle的原理。
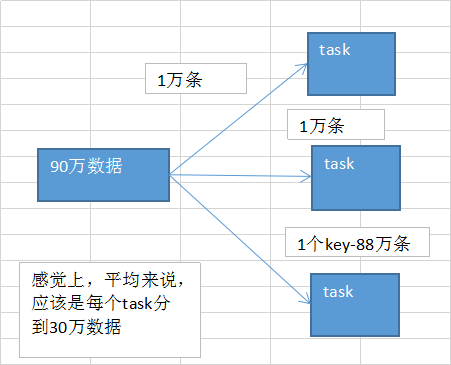
是按照key,来进行values的数据的输出、拉取和聚合的。 同一个key的values,一定是分配到一个reduce task进行处理的。 多个key对应的values,总共是90万。
但是问题是,可能某个key对应了88万数据,key-88万values,分配到一个task上去面去执行。 另外两个task,可能各分配到了1万数据,可能是数百个key,对应的1万条数据。
想象一下,出现数据倾斜以后的运行的情况。很糟糕!极其糟糕!无比糟糕!
第一个和第二个task,各分配到了1万数据;那么可能1万条数据,需要10分钟计算完毕;第一个和第二个task,可能同时在10分钟内都运行完了;第三个task要88万条,88 * 10 = 880分钟 = 14.5个小时;
大家看看,本来另外两个task很快就运行完毕了(10分钟),但是由于一个拖后腿的家伙,第三个task,要14.5个小时才能运行完,就导致整个spark作业,也得14.5个小时才能运行完。
导致spark作业,跑的特别特别特别特别慢!!!像老牛拉破车! 数据倾斜,一旦出现,是不是性能杀手。。。。
发生数据倾斜以后的现象:
spark数据倾斜,有两种表现:
1、你的大部分的task,都执行的特别特别快,刷刷刷,就执行完了(你要用client模式,standalone client,yarn client,本地机器主要一执行spark-submit脚本,就会开始打印log),task175 finished;剩下几个task,执行的特别特别慢,前面的task,一般1s可以执行完5个;最后发现1000个task,998,999 task,要执行1个小时,2个小时才能执行完一个task。 出现数据倾斜了 还算好的,因为虽然老牛拉破车一样,非常慢,但是至少还能跑。
2、运行的时候,其他task都刷刷刷执行完了,也没什么特别的问题;但是有的task,就是会突然间,啪,报了一个OOM,JVM Out Of Memory,内存溢出了,task failed,task lost,resubmitting task。反复执行几次都到了某个task就是跑不通,最后就挂掉。 某个task就直接OOM,那么基本上也是因为数据倾斜了,task分配的数量实在是太大了!!!所以内存放不下,然后你的task每处理一条数据,还要创建大量的对象。内存爆掉了。 出现数据倾斜了 这种就不太好了,因为你的程序如果不去解决数据倾斜的问题,压根儿就跑不出来。 作业都跑不完,还谈什么性能调优这些东西。扯淡。。。
定位原因与出现问题的位置:
根据log去定位 出现数据倾斜的原因,基本只可能是因为发生了shuffle操作,在shuffle的过程中,出现了数据倾斜的问题。因为某个,或者某些key对应的数据,远远的高于其他的key。
1、你在自己的程序里面找找,哪些地方用了会产生shuffle的算子,groupByKey、countByKey、reduceByKey、join
2、看log log一般会报是在你的哪一行代码,导致了OOM异常;或者呢,看log,看看是执行到了第几个stage!!! 我们这里不会去剖析stage的划分算法,spark代码,是怎么划分成一个一个的stage的。哪一个stage,task特别慢,就能够自己用肉眼去对你的spark代码进行stage的划分,就能够通过stage定位到你的代码,哪里发生了数据倾斜 去找找,代码那个地方,是哪个shuffle操作。
=================================================================================================================================================
数据倾斜的解决,跟之前讲解的性能调优,有一点异曲同工之妙。 性能调优,跟大家讲过一个道理,“重剑无锋”。性能调优,调了半天,最有效,最直接,最简单的方式,就是加资源,加并行度,注意RDD架构(复用同一个RDD,加上cache缓存);shuffle、jvm等,次要的。 数据倾斜,解决方案,第一个方案和第二个方案,一起来讲。最朴素、最简谱、最直接、最有效、最简单的,解决数据倾斜问题的方案。 第一个方案:聚合源数据 第二个方案:过滤导致倾斜的key 重剑无锋。后面的五个方案,尤其是最后4个方案,都是那种特别炫酷的方案。双重group聚合方案;sample抽样分解聚合方案;如果碰到了数据倾斜的问题。上来就先考虑考虑第一个和第二个方案,能不能做,如果能做的话,后面的5个方案,都不用去搞了。 有效。简单。直接。效果是非常之好的。彻底根除了数据倾斜的问题。
第一个方案:聚合源数据 咱们现在,做一些聚合的操作,groupByKey、reduceByKey;groupByKey,说白了,就是拿到每个key对应的values;reduceByKey,说白了,就是对每个key对应的values执行一定的计算。 现在这些操作,比如groupByKey和reduceByKey,包括之前说的join。都是在spark作业中执行的。 spark作业的数据来源,通常是哪里呢?90%的情况下,数据来源都是hive表(hdfs,大数据分布式存储系统)。hdfs上存储的大数据。hive表,hive表中的数据,通常是怎么出来的呢?有了spark以后,hive比较适合做什么事情?hive就是适合做离线的,晚上凌晨跑的,ETL(extract transform load,数据的采集、清洗、导入),hive sql,去做这些事情,从而去形成一个完整的hive中的数据仓库;说白了,数据仓库,就是一堆表。 spark作业的源表,hive表,其实通常情况下来说,也是通过某些hive etl生成的。hive etl可能是晚上凌晨在那儿跑。今天跑昨天的数九。 数据倾斜,某个key对应的80万数据,某些key对应几百条,某些key对应几十条;现在,咱们直接在生成hive表的hive etl中,对数据进行聚合。比如按key来分组,将key对应的所有的values,全部用一种特殊的格式,拼接到一个字符串里面去,比如“key=sessionid, value: action_seq=1|user_id=1|search_keyword=火锅|category_id=001;action_seq=2|user_id=1|search_keyword=涮肉|category_id=001”。
对key进行group,在spark中,拿到key=sessionid,values<Iterable>;hive etl中,直接对key进行了聚合。那么也就意味着,每个key就只对应一条数据。在spark中,就不需要再去执行groupByKey+map这种操作了。直接对每个key对应的values字符串,map操作,进行你需要的操作即可。key,values串。 spark中,可能对这个操作,就不需要执行shffule操作了,也就根本不可能导致数据倾斜。 或者是,对每个key在hive etl中进行聚合,对所有values聚合一下,不一定是拼接起来,可能是直接进行计算。reduceByKey,计算函数,应用在hive etl中,每个key的values。
聚合源数据方案,第二种做法 你可能没有办法对每个key,就聚合出来一条数据; 那么也可以做一个妥协;对每个key对应的数据,10万条;有好几个粒度,比如10万条里面包含了几个城市、几天、几个地区的数据,现在放粗粒度;直接就按照城市粒度,做一下聚合,几个城市,几天、几个地区粒度的数据,都给聚合起来。比如说 city_id date area_id select ... from ... group by city_id 尽量去聚合,减少每个key对应的数量,也许聚合到比较粗的粒度之后,原先有10万数据量的key,现在只有1万数据量。减轻数据倾斜的现象和问题。
上面讲的第一种方案,其实这里没法讲的太具体和仔细;只能给一个思路。但是我觉得,思路已经讲的非常清晰了;一般来说,大家只要有一些大数据(hive)。经验,我觉得都是可以理解的。 具体怎么去在hive etl中聚合和操作,就得根据你碰到数据倾斜问题的时候,你的spark作业的源hive表的具体情况,具体需求,具体功能,具体分析。
对于我们的程序来说,完全可以将aggregateBySession()这一步操作,放在一个hive etl中来做,形成一个新的表。对每天的用户访问行为数据,都按session粒度进行聚合,写一个hive sql。 在spark程序中,就不要去做groupByKey+mapToPair这种算子了。直接从当天的session聚合表中,用Spark SQL查询出来对应的数据,即可。这个RDD在后面就可以使用了。
第二个方案:过滤导致倾斜的key 如果你能够接受某些数据,在spark作业中直接就摒弃掉,不使用。比如说,总共有100万个key。只有2个key,是数据量达到10万的。其他所有的key,对应的数量都是几十。 这个时候,你自己可以去取舍,如果业务和需求可以理解和接受的话,在你从hive表查询源数据的时候,直接在sql中用where条件,过滤掉某几个key。 那么这几个原先有大量数据,会导致数据倾斜的key,被过滤掉之后,那么在你的spark作业中,自然就不会发生数据倾斜了。
spark完整的数据倾斜解决方案的更多相关文章
- 最完整的数据倾斜解决方案(spark)
一.了解数据倾斜 数据倾斜的原理: 在执行shuffle操作的时候,按照key,来进行values的数据的输出,拉取和聚合.同一个key的values,一定是分配到一个Reduce task进行处理. ...
- 【Spark调优】大表join大表,少数key导致数据倾斜解决方案
[使用场景] 两个RDD进行join的时候,如果数据量都比较大,那么此时可以sample看下两个RDD中的key分布情况.如果出现数据倾斜,是因为其中某一个RDD中的少数几个key的数据量过大,而另一 ...
- 【Spark调优】小表join大表数据倾斜解决方案
[使用场景] 对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(例如几百MB或者1~2GB),比较适用此方案. [解决方案] ...
- spark中数据倾斜解决方案
数据倾斜导致的致命后果: 1 数据倾斜直接会导致一种情况:OOM. 2 运行速度慢,特别慢,非常慢,极端的慢,不可接受的慢. 搞定数据倾斜需要: 1.搞定shuffle 2.搞定业务场景 3 搞定 c ...
- spark 性能优化 数据倾斜 故障排除
版本:V2.0 第一章 Spark 性能调优 1.1 常规性能调优 1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围 ...
- Spark调优 数据倾斜
1. Spark数据倾斜问题 Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce ...
- spak数据倾斜解决方案
数据倾斜解决方案 数据倾斜的解决,跟之前讲解的性能调优,有一点异曲同工之妙. 性能调优中最有效最直接最简单的方式就是加资源加并行度,并注意RDD架构(复用同一个RDD,加上cache缓存).相对于前面 ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
- spark调优——数据倾斜
Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce点一共要处理100万条数据,第 ...
随机推荐
- ssm项目中ueditor富文本编辑器的使用
一.下载 https://ueditor.baidu.com/website/index.html 将ueditor放到项目中合适的位置 二 . 配置文件上传路径 在utf8-jsp/jsp/conf ...
- operator、explicit与implicit
说这个之前先说下什么叫隐式转换和显示转换 1.所谓隐式转换,就是系统默认的转换,其本质是小存储容量数据类型自动转换为大存储容量数据类型. 例如:float f = 1.0: double d=f:这样 ...
- winform-windowsmediaplayer设置可视化效果之条形
winform导入windowsmediaplayer这个COM组件,他的默认可视化效果为: 而我们需要的可视化效果为: 则我们可以通过代码更改可视化效果:(参数value设为4即可!) //设置可视 ...
- 洛谷P2678跳石头(提高)
题目背景 一年一度的“跳石头”比赛又要开始了! 题目描述 这项比赛将在一条笔直的河道中进行,河道中分布着一些巨大岩石.组委会已经选择好了两块岩石作为比赛起点和终点. 在起点和终点之间,有 N 块岩石( ...
- Android记事本开发02
今天: 继续学习基础知识. 昨天: 学习了ADB工具的基本命令. Android项目的目录结构. AndroidManifest.xml Android应用程序的打包和安装 遇到的问题: 无.
- 【Luogu】P2490黑白棋(博弈DP)
题目链接 题解链接 #include<cstdio> #include<cstring> #include<algorithm> #include<cstdl ...
- js中prop和attr区别
首先 attr 是从页面搜索获得元素值,所以页面必须明确定义元素才能获取值,相对来说比较慢. 如: <input name='test' type='checkbox'> $('input ...
- 洛谷 P2634 [国家集训队]聪聪可可 解题报告
P2634 [国家集训队]聪聪可可 题目描述 聪聪和可可是兄弟俩,他们俩经常为了一些琐事打起来,例如家中只剩下最后一根冰棍而两人都想吃.两个人都想玩儿电脑(可是他们家只有一台电脑)--遇到这种问题,一 ...
- php中json_encode和json_decode的用法
1.json_encode基本用法:数组转字符串 <?php $arr = array ('a'=>1,'b'=>2,'c'=>3,'d'=>4,'e'=>5); ...
- uva1214 Manhattan Wiring 插头DP
There is a rectangular area containing n × m cells. Two cells are marked with “2”, and another two w ...