机器学习:SVM(scikit-learn 中的 SVM:LinearSVC)
一、基础理解
- Hard Margin SVM 和 Soft Margin SVM 都是解决线性分类问题,无论是线性可分的问题,还是线性不可分的问题;
- 和 kNN 算法一样,使用 SVM 算法前,要对数据做标准化处理;
- 原因:SVM 算法中设计到计算 Margin 距离,如果数据点在不同的维度上的量纲不同,会使得距离的计算有问题;
- 例如:样本的两种特征,如果相差太大,使用 SVM 经过计算得到的决策边界几乎为一条水平的直线——因为两种特征的数据量纲相差太大,水平方向的距离可以忽略,因此,得到的最大的 Margin 就是两条虚线的垂直距离;
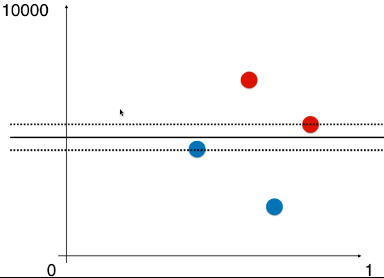
- 只有不同特征的数据的量纲一样时,得到的决策边界才没有问题;
二、例
1)导入并绘制数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X[y<2, :2]
y = y[y<2] plt.scatter(X[y==0, 0], X[y==0, 1], color='red')
plt.scatter(X[y==1, 0], X[y==1, 1], color='blue')
plt.show()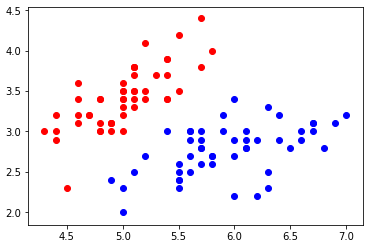
2)LinearSVC(线性 SVM 算法)
- LinearSVC:该算法使用了支撑向量机的思想;
- 数据标准化
from sklearn.preprocessing import StandardScaler standardScaler = StandardScaler()
standardScaler.fit(X)
X_standard = standardScaler.transform(X) - 调用 LinearSVC
from sklearn.svm import LinearSVC svc = LinearSVC(C=10**9)
svc.fit(X_standard, y) - 导入绘制决策边界的函数,并绘制模型决策边界:Hard Margin SVM 思想
def plot_decision_boundary(model, axis): x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) plot_decision_boundary(svc, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[y==0, 0], X_standard[y==0, 1], color='red')
plt.scatter(X_standard[y==1, 0], X_standard[y==1, 1], color='blue')
plt.show()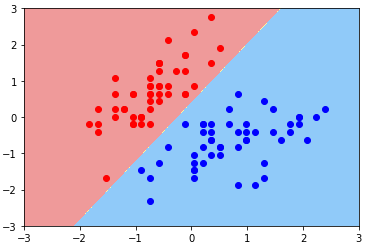
- 绘制决策边界:Soft Margin SVM 思想
svc2 = LinearSVC(C=0.01)
svc2.fit(X_standard, y) plot_decision_boundary(svc2, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[y==0, 0], X_standard[y==0, 1], color='red')
plt.scatter(X_standard[y==1, 0], X_standard[y==1, 1], color='blue')
plt.show()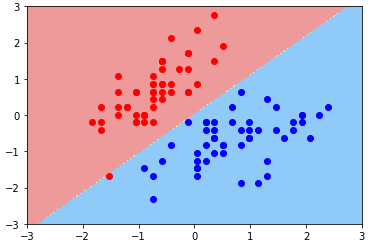
3)绘制支撑向量所在的直线
- svc.coef_:算法模型的系数,有两个值,因为样本有两种特征,每个特征对应一个系数;
- 系数:特征与样本分类结果的关系系数;
- svc.intercept_:模型的截距,一维向量,只有一个数,因为只有一条直线;
- 系数:w = svc.coef_
- 截距:b = svc.intercept_
- 决策边界直线方程:w[0] * x0 + w[1] * x1 + b = 0
- 支撑向量直线方程:w[0] * x0 + w[1] * x1 + b = ±1
- 变形:
- 决策边界:x1 = -w[0]/w[1] * x0 - b/w[1]
- 支撑向量:x1 = -w[0]/w[1] * x0 - b/w[1] ± 1/w[1]
修改绘图函数
# 绘制:决策边界、支撑向量所在的直线
def plot_svc_decision_boundary(model, axis): x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) w = model.coef_[0]
b = model.intercept_[0] plot_x = np.linspace(axis[0], axis[1], 200)
up_y = -w[0]/w[1] * plot_x - b/w[1] + 1/w[1]
down_y = -w[0]/w[1] * plot_x - b/w[1] - 1/w[1] # 将 plot_x 与 up_y、down_y 的关系以折线图的形式表示出来
# 此处有一个问题:up_y和down_y的结果可能超过了 axis 中 y 坐标的范围,需要添加一个过滤条件:
# up_index:布尔向量,元素 True 表示,up_y 中的满足 axis 中的 y 的范围的值在 up_y 中的引索;
# down_index:布尔向量,同理 up_index;
up_index = (up_y >= axis[2]) & (up_y <= axis[3])
down_index = (down_y >= axis[2]) & (down_y <= axis[3])
plt.plot(plot_x[up_index], up_y[up_index], color='black')
plt.plot(plot_x[down_index], down_y[down_index], color='black')绘图:Hard Margin SVM
plot_svc_decision_boundary(svc, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[y==0, 0], X_standard[y==0, 1], color='red')
plt.scatter(X_standard[y==1, 0], X_standard[y==1, 1], color='blue')
plt.show()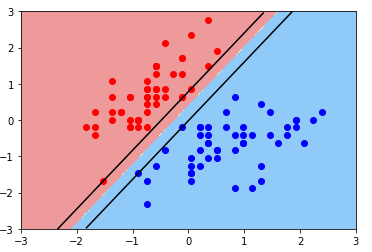
绘图:Soft Margin SVM
plot_svc_decision_boundary(svc2, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[y==0, 0], X_standard[y==0, 1], color='red')
plt.scatter(X_standard[y==1, 0], X_standard[y==1, 1], color='blue')
plt.show()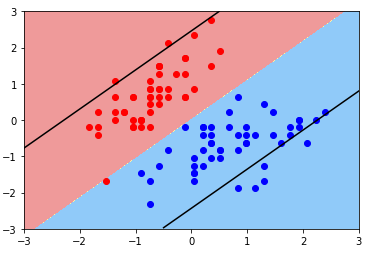
- 现象:Margin 非常大,中间容错了很多样本点;
- 原因:C 超参数过小,模型容错空间过大;
- 方案:调参;
机器学习:SVM(scikit-learn 中的 SVM:LinearSVC)的更多相关文章
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- 100天搞定机器学习|Day16 通过内核技巧实现SVM
前情回顾 机器学习100天|Day1数据预处理100天搞定机器学习|Day2简单线性回归分析100天搞定机器学习|Day3多元线性回归100天搞定机器学习|Day4-6 逻辑回归100天搞定机器学习| ...
- 机器学习基石--学习笔记01--linear hard SVM
背景 支持向量机(SVM)背后的数学知识比较复杂,之前尝试过在网上搜索一些资料自学,但是效果不佳.所以,在我的数据挖掘工具箱中,一直不会使用SVM这个利器.最近,台大林轩田老师在Coursera上的机 ...
- OpenCV中的SVM參数优化
SVM(支持向量机)是机器学习算法里用得最多的一种算法.SVM最经常使用的是用于分类,只是SVM也能够用于回归,我的实验中就是用SVM来实现SVR(支持向量回归). 对于功能这么强的算法,opencv ...
- sklearn中的SVM
scikit-learn中SVM的算法库分为两类,一类是分类的算法库,包括SVC, NuSVC,和LinearSVC 3个类.另一类是回归算法库,包括SVR, NuSVR,和LinearSVR 3个类 ...
- OpenCV中的SVM参数优化
OpenCV中的SVM参数优化 svm参数优化opencv SVMSVR参数优化CvSVMopencv CvSVM SVM(支持向量机)是机器学习算法里用得最多的一种算法.SVM最常用的 ...
随机推荐
- Oracle配置文件
在oracle安装目录$HOME/network/admin下,,经常看到sqlnet.ora tnsnames.ora listener.ora这三个文件,除了tnsnames.ora,其他两个文件 ...
- MVC 控件系列
下拉框:@Html.DropDownList("GroupId"); 文本框:@Html.TextBox("RoleCode", "", n ...
- table-layout 属性
最近被测试提了一个bug,表单的某个字段有1300的字数限制,测试填了1300字,提交后,表格上的呈现丑爆了,那个字段的所在的列撑满了整个表格,其他列被压缩的很小. 后来知道了table-layout ...
- POJ2741 Colored Cubes
Description There are several colored cubes. All of them are of the same size but they may be colore ...
- 虚拟机CentOS7网络配置
*关于查看IP信息 window中是 ipconfig Linux一般都是 ifconfig 不过CentOS7中 这个命令发生了更改 :ip addr 设置网络 再新建虚拟机向导过程中,有一步[网 ...
- oracle创建存储过程中遇到的问题
create or replace PROCEDURE CLEAR AS tname varchar(200);BEGIN tname:='''immediate trace name flush_c ...
- Spring Boot入门——freemarker
使用步骤: 1.在pom.xml中添加相关依赖 <!-- 添加freemarker依赖 --> <dependency> <groupId>org.springfr ...
- java的Random()类使用方法
//随机生成1~100之间的一个整数 int randomNumber = (int)(Math.random() * 100) + 1; System.out.println(randomNumbe ...
- web测试中的测试点和测试方法总结
测试是一种思维,包括情感思维和智力思维,情感思维主要体现在一句俗语:思想决定行动上(要怀疑一切),智力思维主要体现在测试用例的设计上.具有了这样的思想,就会找出更多的bug. 一.输入框 1.字符 ...
- Windows 运行中的命令
辅助功能选项 access.cpl 添加硬件向导 hdwwiz.cpl 添加或删除程序 appwiz.cpl 管理工具 control admintools 自动更新 wuaucpl.cpl Blue ...