可观测性数据收集集大成者 Vector 介绍
如果企业提供 IT 在线服务,那么可观测性能力是必不可少的。“可观测性” 这个词近来也越发火爆,不懂 “可观测性” 都不好意思出门了。但是可观测性能力的构建却着实不易,每个企业都会用到一堆技术栈来组装建设。比如数据收集,可能来自某个 exporter,可能来自 telegraf,可能来自 OTEL,可能来自某个日志文件,可能来自 statsd,收集到数据之后还需要做各种过滤、转换、聚合、采样等操作,烦不胜烦,今天我们就给大家介绍一款开源的数据收集+路由器工具:Vector,解除你的上述烦恼。
Vector 简介
Vector 通常用作 logstash 的替代品,logstash 属于 ELK 生态,使用广泛,但是性能不太好。Vector 使用 Rust 编写,声称比同类方案快 10 倍。Vector 来自 Datadog,如果你了解监控、可观测性,大概率知道 Datadog,作为行业老大哥,其他小弟拍马难及。Datadog 在 2021 年左右收购了 Vector,现在 Vector 已经开源,地址是:
Vector 不止是收集、路由日志数据,也可以路由指标数据,甚至可以从日志中提取指标,功能强大。下面是 Vector 的架构图:
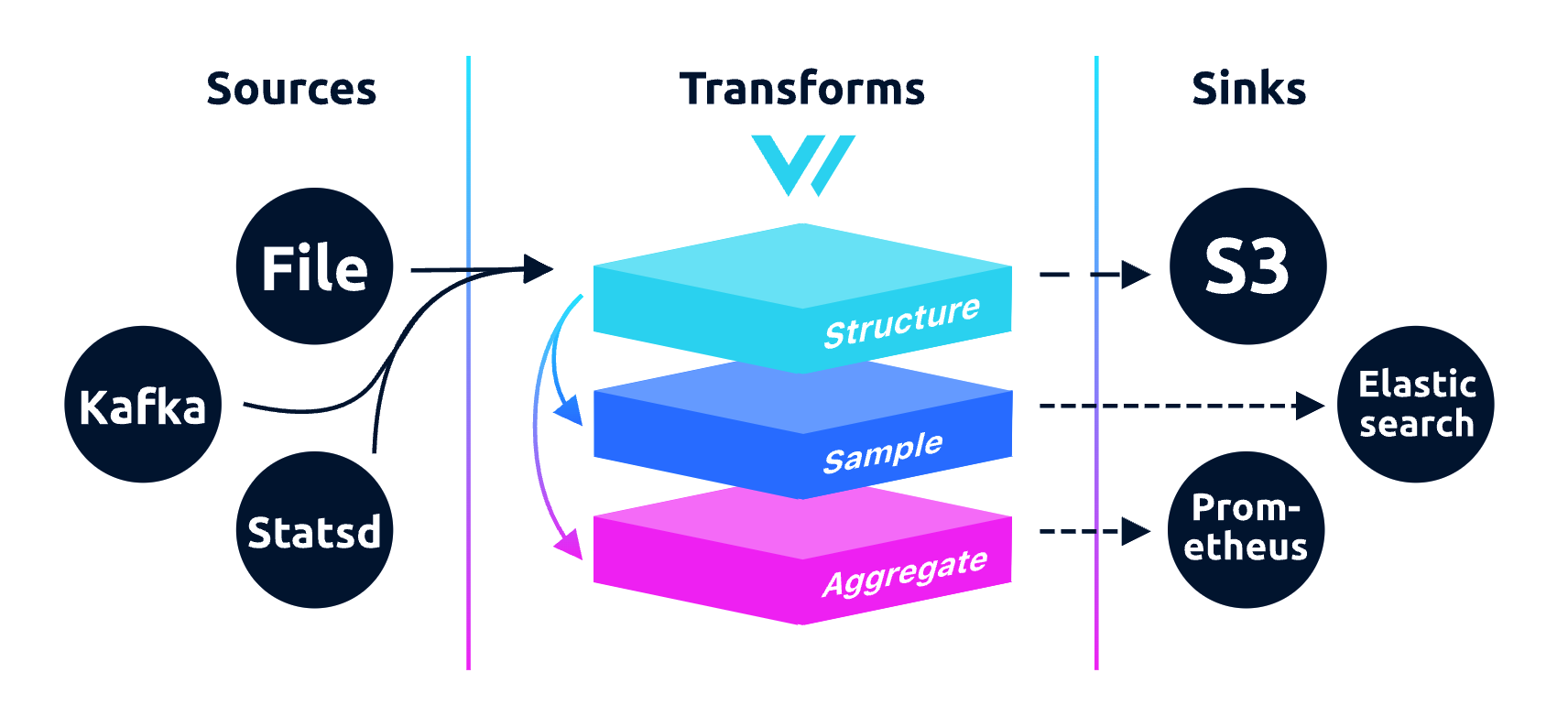
看起来和其他同类产品是类似的,核心就是 pipeline 的处理,有 Source 端做采集,有中间的 Transform 环节做数据加工处理,有 Sink 端做数据转发。魔鬼在细节,Vector 有如下一些特点,让它显得卓尔不群:
- 超级快速可靠:Vector采用Rust构建,速度极快,内存效率高,旨在处理最苛刻的工作负载
- 端到端:Vector 致力于成为从 A 到 B 获取可观测性数据所需的唯一工具,并作为守护程序、边车或聚合器进行部署
- 统一:Vector 支持日志和指标,使您可以轻松收集和处理所有可观测性数据
- 供应商中立:Vector 不偏向任何特定的供应商平台,并以您的最佳利益为出发点,培育公平、开放的生态系统。免锁定且面向未来
- 可编程转换:Vector 的高度可配置转换为您提供可编程运行时的全部功能。无限制地处理复杂的用例
Vector 安装
Vector 的安装比较简单,一条命令即可搞定,其他安装方式可以参考其 官方文档。
curl --proto '=https' --tlsv1.2 -sSf https://sh.vector.dev | bashVector 配置测试
Vector 的配置文件可以是 yaml、json、toml 格式,下面是一个 toml 的例子,其作用是读取 /var/log/system.log 日志文件,然后把 syslog 格式的日志转换成 json 格式,最后输出到标准输出:
[sources.syslog_demo]
type = "file"
include = ["/var/log/system.log"]
data_dir = "/Users/ulric/works/vector-test"
[transforms.remap_syslog]
inputs = [ "syslog_demo"]
type = "remap"
source = '''
structured = parse_syslog!(.message)
. = merge(., structured)
'''
[sinks.emit_syslog]
inputs = ["remap_syslog"]
type = "console"
encoding.codec = "json"首先,[sources.syslog_demo] 定义了一个 source,取名为 syslog_demo,这个 source 的类型是 file,表示从文件中读取数据,文件路径是 /var/log/system.log,data_dir 是存储 checkpoint 数据不用关心,只要给一个可写的目录就行(Vector 自用)。然后定义了一个 transform,名字为 remap_syslog,指定这个 transform 的数据来源(即上游)是 syslog_demo,其类型是 remap,remap 是 Vector 里非常重要的一个 transform,可以做各类数据转换,在 source 字段里定义了一段代码,其工作逻辑是:
- 来自 syslog_demo 这个 source 的日志数据,日志原文在 message 字段里(除了日志原文 message 字段,Vector 还会对采集的数据附加 host、timestamp 等字段),需要先解析成结构化的数据,通过 parse_syslog 这个函数做转换
- 转换之后,相当于把非结构化的日志数据转换成了结构化的数据,赋值给 structured 变量,然后通过 merge 函数把结构化的这个数据和原始就有的 host、timestamp 等字段合并,然后把合并的结果继续往 pipeline 后续环节传递
[sinks.emit_syslog] 定义了一个 sink,名字是 emit_syslog,通过 inputs 指明了上游数据来自 remap_syslog 这个 transform,通过 type 指明要把数据输出给 console,即控制台,然后通过 encoding.codec 指定输出的数据格式是 json。然后通过下面的命令启动 Vector:
vector -c vector.toml然后,你就会看到一堆的日志输出(当然,前提是你的机器上有 system.log 这个文件,我是 macbook,所以用的这个文件测试的),样例如下:
ulric@ulric-flashcat vector-test % vector -c vector.toml
...
{"appname":"syslogd","file":"/var/log/system.log","host":"ulric-flashcat.local","hostname":"ulric-flashcat","message":"ASL Sender Statistics","procid":332,"source_type":"file","timestamp":"2023-09-27T07:31:22Z"}如上,就说明正常采集到了数据,而且转换成了 json 并打印到了控制台,实验成功。当然,打印到控制台只是个测试,Vector 可以把数据推给各类后端,典型的比如 ElasticSearch、S3、ClickHouse、Kafka 等。
Vector 部署模式
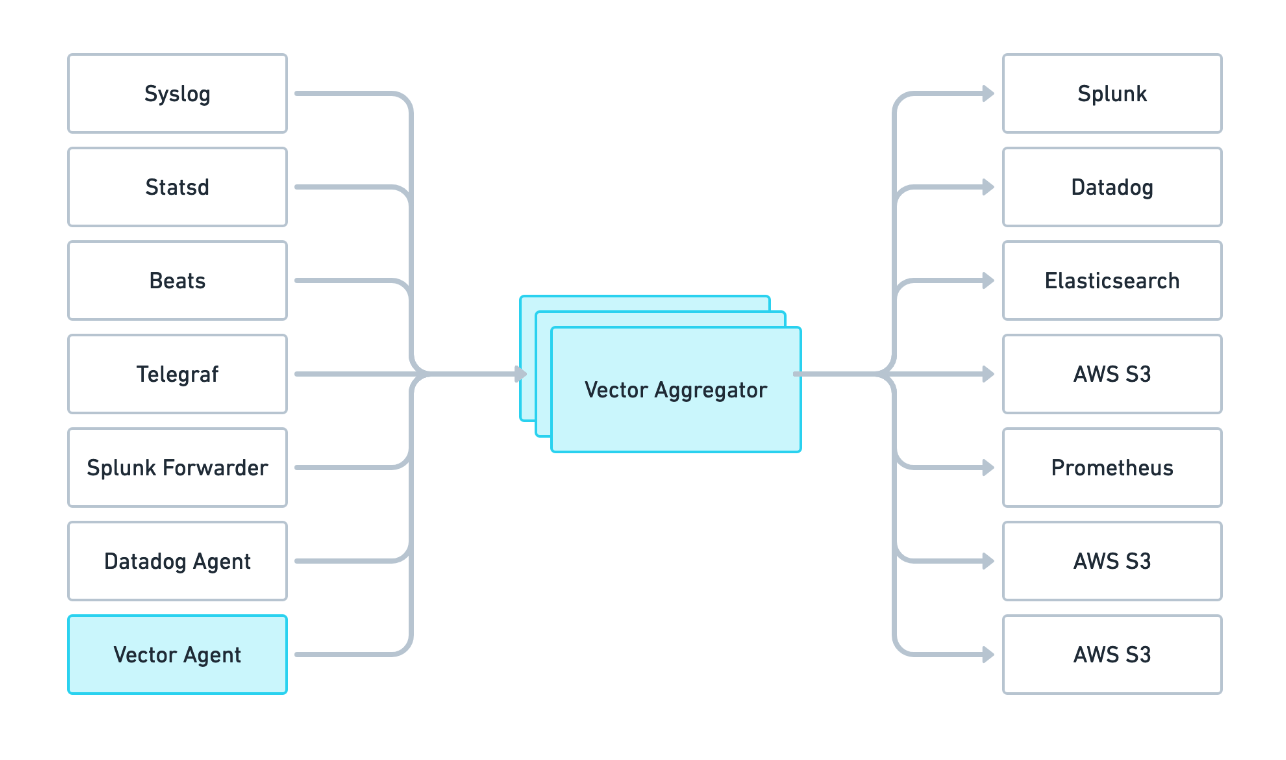
Vector 可以部署为两个角色,既可以作为数据采集的 agent,也可以作为数据聚合、路由的 aggregator,架构示例如下:
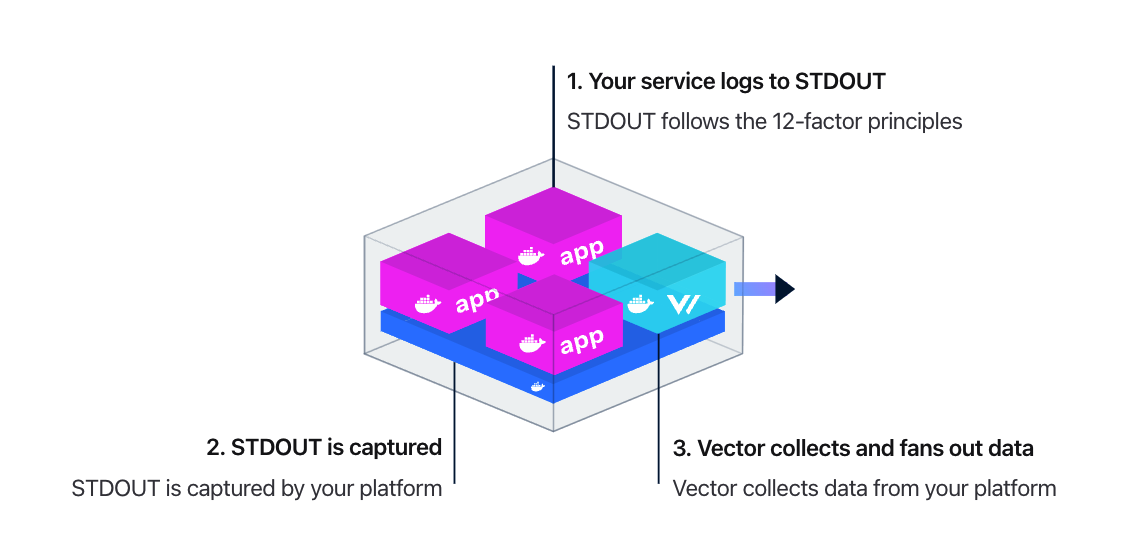
当 Vector 作为 agent 的时候,又有两种使用模式:Daemon 和 Sidecar。Daemon 模式旨在收集单个主机上的所有数据,这是数据收集的推荐方式,因为它最有效地利用主机资源。比如把 Vector 部署为 DaemonSet,收集这个机器上的所有容器中应用的日志,容器中的应用的日志推荐使用 stdout 方式打印,符合云原生 12 条要素。架构图如下:
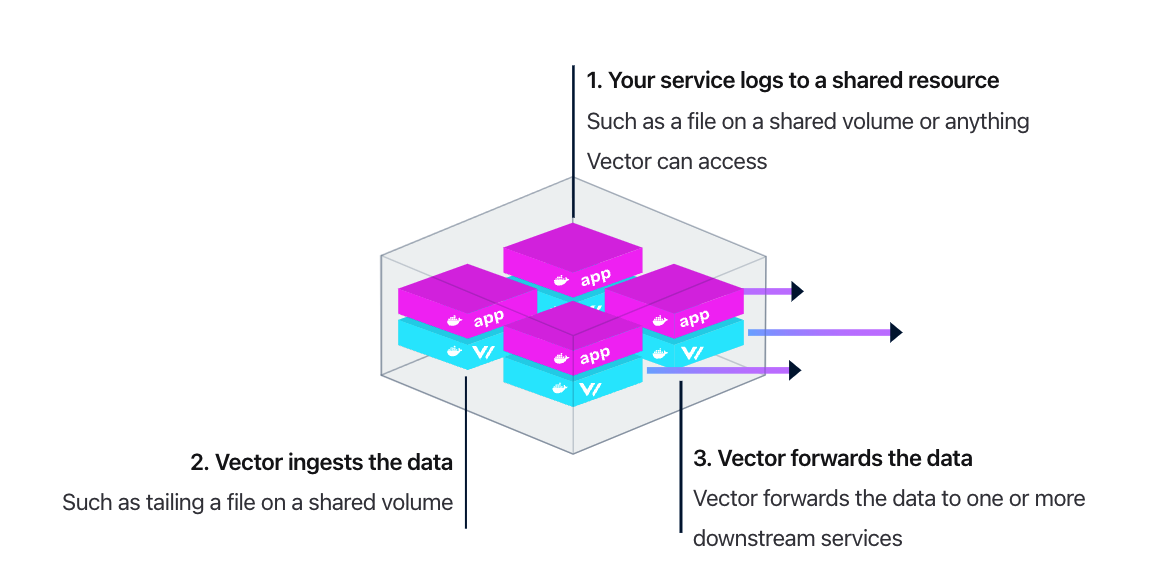
当然,也可以使用 Sidecar 模式部署,这样占用的资源更多(毕竟,每个 Pod 里都要塞一个 Vector 容器),但是更灵活,服务所有者可以随意搞自己的日志收集方案,不用依赖统一的日志收集方案。架构图如下:
Vector 总结
夜莺社区里已经有很多小伙伴从 logstash 迁移到了 Vector,并普遍表示 Vector YYDS,如果你还没听过 Vector,赶紧去试试吧。其他的我也不啰嗦,请各位移步 Vector 官方文档,本文最重要的价值就是让你知道有这么个好东西 :-)
扩展阅读:
- 鄙人专栏:运维监控系统实战笔记,体系化学习监控知识
- 方法论:面向故障处理的可观测性体系建设
- 白皮书:事件OnCall中心建设方法
- 好工具:FlashDuty - 一站式告警处理平台:告警降噪、排班OnCall
- 好工具:Grafana 开源了一款 eBPF 采集器 Beyla
- 好工具:日志存储领域的后起之秀 VictoriaLogs
可观测性数据收集集大成者 Vector 介绍的更多相关文章
- 第六版PMBOK中工具与技术的介绍:数据收集数据分析数据表现
数据收集技术: 1.头脑风暴:收集关于项目方法的创意和解决方案.2.焦点小组:召集预定的相关方和主题专家,了解他们对所讨论的产品服务或成果的期望和态度.主持人引导大家互动式讨论.3.访谈:通过与相关方 ...
- SQL Server自动化运维系列——关于数据收集(多服务器数据收集和性能监控)
需求描述 在生产环境中,很多情况下需要采集数据,用以定位问题或者形成基线. 关于SQL Server中的数据采集有着很多种的解决思路,可以采用Trace.Profile.SQLdiag.扩展事件等诸多 ...
- C++ 中的std::vector介绍(转)
vector是C++标准模板库中的部分内容,它是一个多功能的,能够操作多种数据结构和算法的模板类和函数库.vector之所以被认为是一个容器,是因为它能够像容器一样存放各种类型的对象,简单地说,vec ...
- 网站统计中的数据收集原理及实现(share)
转载自:http://blog.codinglabs.org/articles/how-web-analytics-data-collection-system-work.html 网站数据统计分析工 ...
- std::vector介绍
vector是C++标准模板库中的部分内容,它是一个多功能的,能够操作多种数据结构和算法的模板类和函数库.vector之所以被认为是一个容器,是因为它能够像容器一样存放各种类型的对象,简单地说,vec ...
- 使用nginx lua实现网站统计中的数据收集
导读网站数据统计分析工具是各网站站长和运营人员经常使用的一种工具,常用的有 谷歌分析.百度统计和腾讯分析等等.所有这些统计分析工具的第一步都是网站访问数据的收集.目前主流的数据收集方式基本都是基于ja ...
- SQL Server自动化运维系列 - 多服务器数据收集和性能监控
需求描述 在生产环境中,很多情况下需要采集数据,用以定位问题或者形成基线. 关于SQL Server中的数据采集有着很多种的解决思路,可以采用Trace.Profile.SQLdiag.扩展事件等诸多 ...
- Flunetd 用于统一日志记录层的开源数据收集器
传统的日志查看方式 使用fluentd之后 一.介绍 Fluentd是一个开源的数据收集器,可以统一对数据收集和消费,以便更好地使用和理解数据. 几大特色: 使用JSON统一记录 简单灵活可插拔架构 ...
- 从0到1搭建基于Kafka、Flume和Hive的海量数据分析系统(一)数据收集应用
大数据时代,一大技术特征是对海量数据采集.存储和分析的多组件解决方案.而其中对来自于传感器.APP的SDK和各类互联网应用的原生日志数据的采集存储则是基本中的基本.本系列文章将从0到1,概述一下搭建基 ...
- SQL Server 自动化运维系列 - 多服务器数据收集和性能监控
需求描述 在生产环境中,很多情况下需要采集数据,用以定位问题或者形成基线. 关于SQL Server中的数据采集有着很多种的解决思路,可以采用Trace.Profile.SQLdiag.扩展事件等诸多 ...
随机推荐
- React后台管理系统(TypeScript、Redux状态管理)环境搭建01
搭建环境的时候,我们必须要先确保环境有node环境和npm环境,如下使用cmd命令 确保自己有了这两个环境之后我们就可以开始搭建项目,首先找一个文件夹,这个文件夹用来初始化当前环境,例如,我这里选 ...
- Taurus .Net Core 微服务开源框架:Admin 插件【3】 - 指标统计管理
前言: 继上篇:Taurus .Net Core 微服务开源框架:Admin 插件[2] - 系统环境信息管理 本篇继续介绍下一个内容: 1.系统指标节点:Metric - API 界面 界面图如下: ...
- ABP - 本地事件总线
1. 事件总线 在我们的一个应用中,经常会出现一个逻辑执行之后要跟随执行另一个逻辑的情况,例如一个用户创建了后续还需要发送邮件进行通知,或者需要初始化相应的权限等.面对这样的情况,我们当然可以顺序进行 ...
- 自研ORM 子查询&嵌套查询
作者 Mr-zhong 代码改变世界.... 一.前言 Fast Framework 基于NET6.0 封装的轻量级 ORM 框架 支持多种数据库 SqlServer Oracle MySql Pos ...
- freeswitch的mod_cdr_csv模块
概述 freeswitch是一款简单好用的VOIP开源软交换平台. 在语音呼叫的过程中,话单是重要的计价和结算依据,话单的产生需要稳定可靠,可回溯. fs中基本的话单模块mod_cdr_csv,可以满 ...
- 解决php中通过exec调用python脚本报ModuleNotFoundError错误
背景 出于某些原因,我们有时会在PHP中通过exec来调用Python代码,有可能是某些功能只能用Python实现(或用Python实现比较方便),有可能是出于性能考虑(Python可以执行耗时任务) ...
- bitfield
bitfield 作用 位域修改 溢出控制 原理 通过对redis字符串二进制形式进行操作,通过改变其值的作用 更具体 将一个Redis字符串看作是一个由二进制位组成的数组. 并能对变长位宽和任意没有 ...
- (数据科学学习手札153)基于martin的高性能矢量切片地图服务构建
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,在日常研发地图类应用的场景中, ...
- [oracle]使用impdp导入数据时卡在视图
前言 oracle 19c使用impdp的时候卡在导入视图的地方一点不动,也没啥提示.根据网上资料,oracle 19在导入视图的时候会有bug. 步骤 查看导入任务 sqlplus / as sys ...
- 利用pytorch准备数据集、构建与训练、保存与加载CNN模型
本文的主要内容是利用pytorch框架与torchvision工具箱,进行准备数据集.构建CNN网络模型.训练模型.保存和加载自定义模型等工作.本文若有疏漏.需更正.改进的地方,望读者予以指正,如果本 ...