基于tensorflow的RBF神经网络案例
1 前言
在使用RBF神经网络实现函数逼近中,笔者介绍了使用 Matlab 训练RBF神经网络。本博客将介绍使用 tensorflow 训练RBF神经网络。代码资源见:RBF案例(更新版)
这几天,笔者在寻找 tensorflow 中 RBF 官方案例,没找到,又看了一些博客,发现这些博客或不能逼近多元函数,或不能批量训练。于是,自己手撕了一下代码。
RBF神经网络中需要求解的参数有4个:基函数的中心和方差、隐含层到输出层的权值和偏值。
RBF 神经网络的关键在于中心的选取,一般有如下三种方法:
- 直接计算法:直接通过先验经验固定中心,并计算方差,再通过有监督学习得到其他参数
- 自组织学习法:先通过k-means等聚类算法求出中心(无监督学习),并计算方差,再通过有监督学习得到其他参数
- 有监督学习法:直接通过有监督学习求出所有参数
在直接计算法和自组织学习法中,方差的计算公式如下:
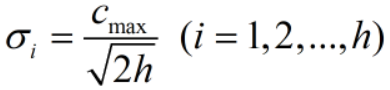
其中 Cmax 表示 h 个中心间的最大距离。
本博客主要介绍后两种中心计算方法实现 RBF 神经网络。
笔者工作空间如下:
2 RBF神经网络实现
2.1 自组织学习选取RBF中心
RBF_kmeans.py
import tensorflow as tf
import numpy as np
from sklearn.cluster import KMeans
class RBF:
#初始化学习率、学习步数
def __init__(self,learning_rate=0.002,step_num=10001,hidden_size=10):
self.learning_rate=learning_rate
self.step_num=step_num
self.hidden_size=hidden_size
#使用 k-means 获取聚类中心、标准差
def getC_S(self,x,class_num):
estimator=KMeans(n_clusters=class_num,max_iter=10000) #构造聚类器
estimator.fit(x) #聚类
c=estimator.cluster_centers_
n=len(c)
s=0;
for i in range(n):
j=i+1
while j<n:
t=np.sum((c[i]-c[j])**2)
s=max(s,t)
j=j+1
s=np.sqrt(s)/np.sqrt(2*n)
return c,s
#高斯核函数(c为中心,s为标准差)
def kernel(self,x,c,s):
x1=tf.tile(x,[1,self.hidden_size]) #将x水平复制 hidden次
x2=tf.reshape(x1,[-1,self.hidden_size,self.feature])
dist=tf.reduce_sum((x2-c)**2,2)
return tf.exp(-dist/(2*s**2))
#训练RBF神经网络
def train(self,x,y):
self.feature=np.shape(x)[1] #输入值的特征数
self.c,self.s=self.getC_S(x,self.hidden_size) #获取聚类中心、标准差
x_=tf.placeholder(tf.float32,[None,self.feature]) #定义placeholder
y_=tf.placeholder(tf.float32,[None,1]) #定义placeholder
#定义径向基层
z=self.kernel(x_,self.c,self.s)
#定义输出层
w=tf.Variable(tf.random_normal([self.hidden_size,1]))
b=tf.Variable(tf.zeros([1]))
yf=tf.matmul(z,w)+b
loss=tf.reduce_mean(tf.square(y_-yf))#二次代价函数
optimizer=tf.train.AdamOptimizer(self.learning_rate) #Adam优化器
train=optimizer.minimize(loss) #最小化代价函数
init=tf.global_variables_initializer() #变量初始化
with tf.Session() as sess:
sess.run(init)
for epoch in range(self.step_num):
sess.run(train,feed_dict={x_:x,y_:y})
if epoch>0 and epoch%500==0:
mse=sess.run(loss,feed_dict={x_:x,y_:y})
print(epoch,mse)
self.w,self.b=sess.run([w,b],feed_dict={x_:x,y_:y})
def kernel2(self,x,c,s): #预测时使用
x1=np.tile(x,[1,self.hidden_size]) #将x水平复制 hidden次
x2=np.reshape(x1,[-1,self.hidden_size,self.feature])
dist=np.sum((x2-c)**2,2)
return np.exp(-dist/(2*s**2))
def predict(self,x):
z=self.kernel2(x,self.c,self.s)
pre=np.matmul(z,self.w)+self.b
return pre
2.2 有监督学习选取RBF中心
RBF_Supervised.py
import numpy as np
import tensorflow as tf
class RBF:
#初始化学习率、学习步数
def __init__(self,learning_rate=0.002,step_num=10001,hidden_size=10):
self.learning_rate=learning_rate
self.step_num=step_num
self.hidden_size=hidden_size
#高斯核函数(c为中心,s为标准差)
def kernel(self,x,c,s): #训练时使用
x1=tf.tile(x,[1,self.hidden_size]) #将x水平复制 hidden次
x2=tf.reshape(x1,[-1,self.hidden_size,self.feature])
dist=tf.reduce_sum((x2-c)**2,2)
return tf.exp(-dist/(2*s**2))
#训练RBF神经网络
def train(self,x,y):
self.feature=np.shape(x)[1] #输入值的特征数
x_=tf.placeholder(tf.float32,[None,self.feature]) #定义placeholder
y_=tf.placeholder(tf.float32,[None,1]) #定义placeholder
#定义径向基层
c=tf.Variable(tf.random_normal([self.hidden_size,self.feature]))
s=tf.Variable(tf.random_normal([self.hidden_size]))
z=self.kernel(x_,c,s)
#定义输出层
w=tf.Variable(tf.random_normal([self.hidden_size,1]))
b=tf.Variable(tf.zeros([1]))
yf=tf.matmul(z,w)+b
loss=tf.reduce_mean(tf.square(y_-yf))#二次代价函数
optimizer=tf.train.AdamOptimizer(self.learning_rate) #Adam优化器
train=optimizer.minimize(loss) #最小化代价函数
init=tf.global_variables_initializer() #变量初始化
with tf.Session() as sess:
sess.run(init)
for epoch in range(self.step_num):
sess.run(train,feed_dict={x_:x,y_:y})
if epoch>0 and epoch%500==0:
mse=sess.run(loss,feed_dict={x_:x,y_:y})
print(epoch,mse)
self.c,self.s,self.w,self.b=sess.run([c,s,w,b],feed_dict={x_:x,y_:y})
def kernel2(self,x,c,s): #预测时使用
x1=np.tile(x,[1,self.hidden_size]) #将x水平复制 hidden次
x2=np.reshape(x1,[-1,self.hidden_size,self.feature])
dist=np.sum((x2-c)**2,2)
return np.exp(-dist/(2*s**2))
def predict(self,x):
z=self.kernel2(x,self.c,self.s)
pre=np.matmul(z,self.w)+self.b
return pre
3 案例
3.1 一元函数逼近
待逼近函数:
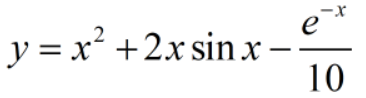
(1)自组织学习选取RBF中心
test_kmeans.py
import numpy as np
import matplotlib.pyplot as plt
from RBF_kmeans import RBF
#待逼近的函数
def fun(x):
return x*x+2*x*np.sin(x)-np.exp(-x)/10
#生成样本
def generate_samples():
n=150 #样本点个数
wideX=0.03 #横轴噪声的宽度
wideY=0.5 #纵轴噪声宽度
t=np.linspace(-5,5,n).reshape(-1,1) #横轴理想值
u=fun(t) #纵轴理想值
noisyX=np.random.uniform(-wideX,wideX,n).reshape(n,-1) #横轴噪声
noisyY=np.random.uniform(-wideY,wideY,n).reshape(n,-1) #纵轴噪声
x=t+noisyX #横轴实际值
y=u+noisyY #纵轴实际值
return t,u,x,y
t,u,x,y=generate_samples()
rbf=RBF(0.003,20001,4) #学习率
rbf.train(x,y)
pre=rbf.predict(t)
plt.plot(x,y,'+')
plt.plot(t,u)
plt.plot(t,pre)
plt.legend(['dot','real','pre'],loc='upper left')
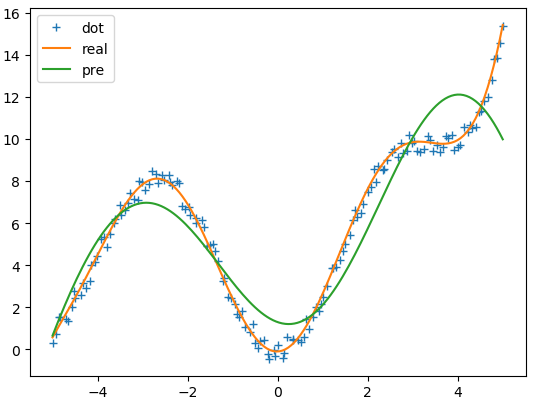 自组织学习选取RBF中心
自组织学习选取RBF中心
(2)有监督学习选取RBF中心
test_Supervised.py
import numpy as np
import matplotlib.pyplot as plt
from RBF_Supervised import RBF
#待逼近的函数
def fun(x):
return x*x+2*x*np.sin(x)-np.exp(-x)/10
#生成样本
def generate_samples():
n=150 #样本点个数
wideX=0.03 #横轴噪声的宽度
wideY=0.5 #纵轴噪声宽度
t=np.linspace(-5,5,n).reshape(-1,1) #横轴理想值
u=fun(t) #纵轴理想值
noisyX=np.random.uniform(-wideX,wideX,n).reshape(n,-1) #横轴噪声
noisyY=np.random.uniform(-wideY,wideY,n).reshape(n,-1) #纵轴噪声
x=t+noisyX #横轴实际值
y=u+noisyY #纵轴实际值
return t,u,x,y
t,u,x,y=generate_samples()
rbf=RBF(0.003,20001,4) #学习率
rbf.train(x,y)
pre=rbf.predict(t)
plt.plot(x,y,'+')
plt.plot(t,u)
plt.plot(t,pre)
plt.legend(['dot','real','pre'],loc='upper left')
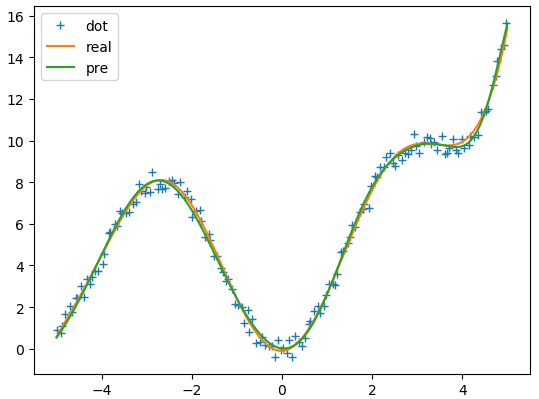 有监督学习选取RBF中心
有监督学习选取RBF中心
3.2 二元函数逼近
待逼近函数:
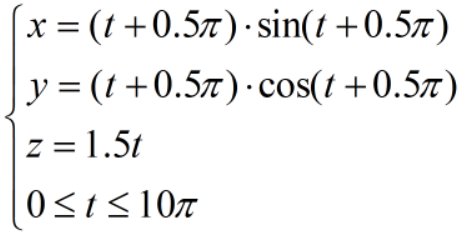
(1)自组织学习选取RBF中心
test_kmeans2.py
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
from RBF_kmeans import RBF
#待逼近的函数
def fun(t):
x1=(t+0.5*np.pi)*np.sin(t+0.5*np.pi)
x2=(t+0.5*np.pi)*np.cos(t+0.5*np.pi)
y=1.5*t
x=np.append(x1,x2,1)
return x,y
#生成样本
def generate_samples():
n=200 #样本点个数
wideX=0.6 #水平方向噪声的宽度
wideY=1 #纵轴噪声宽度
t=np.linspace(0,10*np.pi,n).reshape(-1,1) #横轴理想值
u,v=fun(t) #纵轴理想值
noisyX=np.random.uniform(-wideX,wideX,u.shape).reshape(n,-1) #水平方向噪声
noisyY=np.random.uniform(-wideY,wideY,n).reshape(n,-1) #纵轴噪声
x=u+noisyX #横轴实际值
y=v+noisyY #纵轴实际值
return u,v,x,y
u,v,x,y=generate_samples()
rbf=RBF(0.02,20001,10) #学习率
rbf.train(x,y)
pre=rbf.predict(u)
ax=plt.figure().gca(projection='3d')
ax.plot(x[:,0],x[:,1],y[:,0],'+')
ax.plot(u[:,0],u[:,1],v[:,0])
ax.plot(u[:,0],u[:,1],pre[:,0])
plt.legend(['dot','real','pre'],loc='upper left')
plt.show()
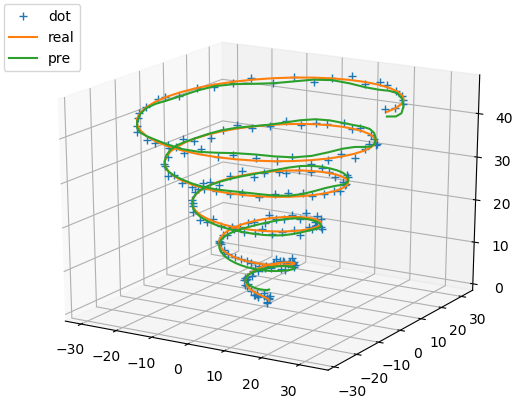 自组织学习选取RBF中心
自组织学习选取RBF中心
(2)有监督学习选取RBF中心
test_Supervised2.py
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
from RBF_Supervised import RBF
#待逼近的函数
def fun(t):
x1=(t+0.5*np.pi)*np.sin(t+0.5*np.pi)
x2=(t+0.5*np.pi)*np.cos(t+0.5*np.pi)
y=1.5*t
x=np.append(x1,x2,1)
return x,y
#生成样本
def generate_samples():
n=200 #样本点个数
wideX=0.6 #水平方向噪声的宽度
wideY=1 #纵轴噪声宽度
t=np.linspace(0,10*np.pi,n).reshape(-1,1) #横轴理想值
u,v=fun(t) #纵轴理想值
noisyX=np.random.uniform(-wideX,wideX,u.shape).reshape(n,-1) #水平方向噪声
noisyY=np.random.uniform(-wideY,wideY,n).reshape(n,-1) #纵轴噪声
x=u+noisyX #横轴实际值
y=v+noisyY #纵轴实际值
return u,v,x,y
u,v,x,y=generate_samples()
rbf=RBF(0.02,20001,10) #学习率
rbf.train(x,y)
pre=rbf.predict(u)
ax=plt.figure().gca(projection='3d')
ax.plot(x[:,0],x[:,1],y[:,0],'+')
ax.plot(u[:,0],u[:,1],v[:,0])
ax.plot(u[:,0],u[:,1],pre[:,0])
plt.legend(['dot','real','pre'],loc='upper left')
plt.show()
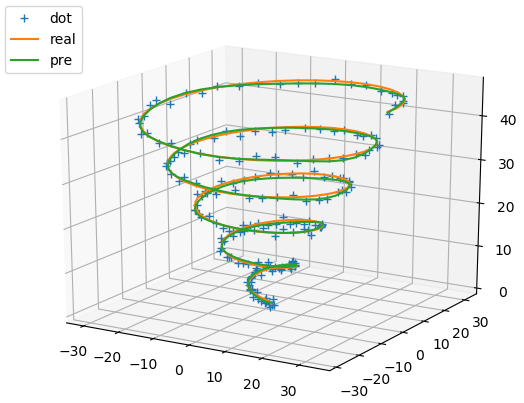 有监督学习选取RBF中心
有监督学习选取RBF中心
通过实验可以看到:无论是一元函数逼近还是二元函数逼近,在隐藏层神经元个数、学习率、学习步数相同的情况下,有监督学习法都比自组织学习法效果好。
声明:本文转自基于tensorflow的RBF神经网络案例
基于tensorflow的RBF神经网络案例的更多相关文章
- 基于HHT和RBF神经网络的故障检测——第二篇论文读后感
故障诊断主要包括三部分: 1.故障信号检测方法(定子电流信号检测 [ 定子电流幅值和电流频谱 ] ,振动信号检测,温度信号检测,磁通检测法,绝缘检测法,噪声检测法) 2.故障信号的处理方法,即故障特征 ...
- 基于tensorflow搭建一个神经网络
一,tensorflow的简介 Tensorflow是一个采用数据流图,用于数值计算的 开源软件库.节点在图中表示数字操作,图中的线 则表示在节点间相互联系的多维数据数组,即张量 它灵活的架构让你可以 ...
- 基于TensorFlow的循环神经网络(RNN)
RNN适用场景 循环神经网络(Recurrent Neural Network)适合处理和预测时序数据 RNN的特点 RNN的隐藏层之间的节点是有连接的,他的输入是输入层的输出向量.extend(上一 ...
- 基于 SoC 的卷积神经网络车牌识别系统设计(1)概述
NOTES: 这是第三届全国大学生集成电路创新创业大赛 - Arm 杯 - 片上系统设计挑战赛(本人指导的一个比赛).主要划分为以下的 Top5 重点.难点.亮点.热点以及创新点:1.通过 Arm C ...
- Chinese-Text-Classification,用卷积神经网络基于 Tensorflow 实现的中文文本分类。
用卷积神经网络基于 Tensorflow 实现的中文文本分类 项目地址: https://github.com/fendouai/Chinese-Text-Classification 欢迎提问:ht ...
- 基于TensorFlow解决手写数字识别的Softmax方法、多层卷积网络方法和前馈神经网络方法
一.基于TensorFlow的softmax回归模型解决手写字母识别问题 详细步骤如下: 1.加载MNIST数据: input_data.read_data_sets('MNIST_data',one ...
- 深度学习(五)基于tensorflow实现简单卷积神经网络Lenet5
原文作者:aircraft 原文地址:https://www.cnblogs.com/DOMLX/p/8954892.html 参考博客:https://blog.csdn.net/u01287127 ...
- 使用TensorFlow的递归神经网络(LSTM)进行序列预测
本篇文章介绍使用TensorFlow的递归神经网络(LSTM)进行序列预测.作者在网上找到的使用LSTM模型的案例都是解决自然语言处理的问题,而没有一个是来预测连续值的. 所以呢,这里是基于历史观察数 ...
- 基于Tensorflow + Opencv 实现CNN自定义图像分类
摘要:本篇文章主要通过Tensorflow+Opencv实现CNN自定义图像分类案例,它能解决我们现实论文或实践中的图像分类问题,并与机器学习的图像分类算法进行对比实验. 本文分享自华为云社区< ...
- 从环境搭建到回归神经网络案例,带你掌握Keras
摘要:Keras作为神经网络的高级包,能够快速搭建神经网络,它的兼容性非常广,兼容了TensorFlow和Theano. 本文分享自华为云社区<[Python人工智能] 十六.Keras环境搭建 ...
随机推荐
- Oracle实例的启动和关闭
启动模式 1.NoMount 模式(启动实例不加载数据库) 命令:startup nomount 讲解:这种启动模式只会创建实例,并不加载数据库,Oracle仅为实例创建各种内存结构和服务进程,不会打 ...
- K8s集群CoreDNS监控告警最佳实践
本文分享自华为云社区<K8s集群CoreDNS监控告警最佳实践>,作者:可以交个朋友. 一 背景 coreDNS作为K8s集群中的关键组成部分.主要负责k8s集群中的服务发现,域名解析等功 ...
- 【面试题精讲】Java Stream排序的实现方式
首发博客地址 系列文章地址 如何使用Java Stream进行排序 在Java中,使用Stream进行排序可以通过sorted()方法来实现.sorted()方法用于对Stream中的元素进行排序操作 ...
- [转帖]shell编程之条件语句
目录 一.条件测试 test命令 文件测试与整数测试 文件测试 整数值比较 字符串测试与逻辑测试 字符串比较 逻辑测试 二.if语句 if单分支语句 单分支结构 if双分支语句 双分支结构 if多分支 ...
- [转帖]ramfs、tmpfs、rootfs、ramdisk介绍
ramfs.tmpfs.rootfs.ramdisk介绍 bootleader--->kernel---->initrd(是xz.cpio.是ramfs的一种,主要是驱动和为了加载ro ...
- [转帖]Rocksdb的优劣及应用场景分析
研究Rocksdb已经有七个月的时间了,这期间阅读了它的大部分代码,对底层存储引擎进行了适配,同时也做了大量的测试.在正式研究之前由于对其在本地存储引擎这个江湖地位的膜拜,把它想象的很完美,深入摸 ...
- [转帖]关于https://goproxy.cn,direct与https://proxy.golang.org的问题,国内无法访问https://proxy.golang.org设置了GOPROXY仍不可行
关于https://goproxy.cn,direct与https://proxy.golang.org的问题,国内无法访问https://proxy.golang.org设置了GOPROXY仍不可行 ...
- [转帖]修改jmeter内存配置(win&mac&linux)
目录 一.背景: 二.win环境下修改jmeter内存 三.mac&linux环境下修改jmeter内存 四.验证内存是否修改成功 一.背景: 在进行大数据.高并发压测的过程性,有时会遇上JM ...
- [转帖]Linux-find命令报错: missing argument to `-exec'
https://www.cnblogs.com/yeyuzhuanjia/p/17427143.html 报错提示:find: missing argument to `-exec' 今天写一个清理脚 ...
- 记一次flex布局中子项目尺寸不受flex-shrink限制的问题
预期是写一个如下所示的布局内容: 即有一个固定高度的外部容器,顶部的header已知高度,在header占据了固定高度后,剩下的都分给body部分.因此采用flex布局,header设置flex-sh ...