OpenTSDB 数据存储详解
本文首发于 vivo互联网技术 微信公众号
链接: https://mp.weixin.qq.com/s/qayKiwk5QAIWI7-nyD3FVA
作者:DuZhimin
随着互联网、尤其是物联网的发展,我们需要把各种类型的终端实时监测、检查与分析设备所采集、产生的数据记录下来,在有时间的坐标中将这些数据连点成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
这些数据的典型特点是:产生频率快(每一个监测点一秒钟内可产生多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(实时监测系统均有成千上万的监测点,监测点每秒钟都产生数据,每天产生几十GB的数据量)。
基于时间序列数据的特点,关系型数据库无法满足对时间序列数据的有效存储与处理,因此迫切需要一种专门针对时间序列数据来做优化处理的数据库系统。
一、简介
1、时序数据
时序数据是基于时间的一系列的数据。
2、时序数据库
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。
对比传统数据库仅仅记录了数据的当前值,时序数据库则记录了所有的历史数据。同时时序数据的查询也总是会带上时间作为过滤条件。
3、OpenTSDB
毫无遗漏的接收并存储大量的时间序列数据。
3.1、存储
- 无需转换,写的是什么数据存的就是什么数据
- 时序数据以毫秒的精度保存
- 永久保留原始数据
3.2、扩展性
- 运行在Hadoop 和 HBase之上
- 可扩展到每秒数百万次写入
- 可以通过添加节点扩容
3.3、读能力
- 直接通过内置的GUI来生成图表
- 还可以通过HTTP API查询数据
- 另外还可以使用开源的前端与其交互
4、OpenTSDB核心概念
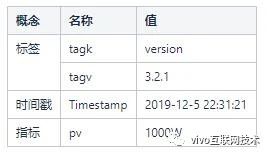
我们来看一下这样一段信息:2019-12-5 22:31:21版本号为‘3.2.1’的某产品客户端的首页PV是1000W
- Metric:指标,即平时我们所说的监控项。譬如上面的PV
- Tags:维度,也即标签,在OpenTSDB里面,Tags由tagk和tagv组成的键值对,即tagk=takv。标签是用来描述Metric的,比如上面的某产品客户端的版本号 version=‘3.2.1’
- Value:一个Value表示一个metric的实际数值,比如:1000W
- Timestamp:即时间戳,用来描述Value是什么时候发生的:比如:2019-12-5 22:31:21
- Data Point:即某个Metric在某个时间点的数值,Data Point包括以下部分:Metric、Tags、Value、Timestamp
- 保存到OpenTSDB的数据就是无数个DataPoint
上面描述2019-12-5 22:31:21版本号为‘3.2.1’的某产品客户端的首页PV是1000W,就是1个DataPoint。
二、OpenTSDB的部署架构
1、架构图
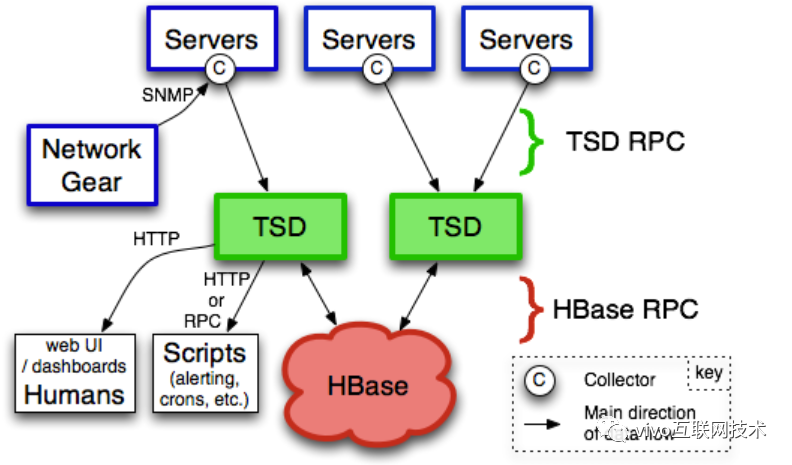
2、说明
- OpenTSDB底层是使用HBase来存储数据的,也就是说搭建OpenTSDB之前,必须先搭建好HBase环境。
- OpenTSDB是由一系列的TSD和实用的命令行工具组成。
- 应用通过运行一个或多个tsd(Time Series Daemon, OpenTSDB的节点)来与OpenTSDB的交互。
- 每个TSD是独立的,没有master,没有共享状态,所以你可以运行尽可能多的 TSD 来处理工作负载。
三、HBase简介
从OpenTSDB的部署架构中我们看到OpenTSDB是建立在HBase之上的,那么HBase又是啥呢?为了更好的剖析OpenTSDB,这里我们简要介绍一下HBase。
1、HBase是一个高可靠性、强一致性、高性能、面向列、可伸缩、实时读写的分布式开源NoSQL数据库。
2、HBase是无模式数据库,只需要提前定义列簇,并不需要指定列限定符。同时它也是无类型数据库,所有数据都是按二进制字节方式存储的。
3、它把数据存储在表中,表按“行键,列簇,列限定符和时间版本”的四维坐标系来组织,也就是说如果要唯一定位一个值,需要四个都唯一才行。下面参考Excel来说明一下:
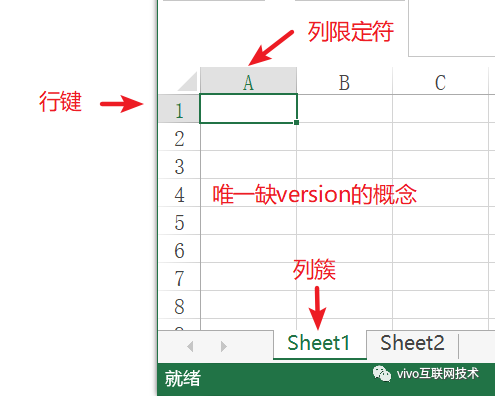
4、对 HBase 的操作和访问有 5 个基本方式,即 Get、Put、Delete 和 Scan 以及 Increment,HBase 基于非行键值查询的唯一途径是通过带过滤器的扫描。
5、数据在HBase中的存储(物理上):
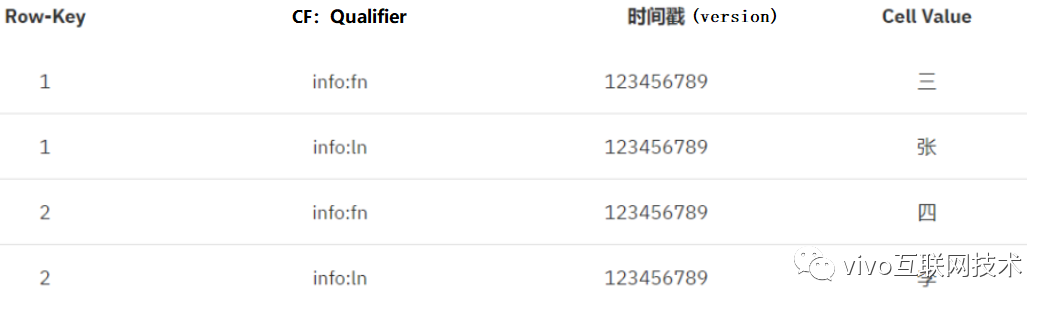
6、数据在HBase中的存储(逻辑上):

四、 支撑OpenTSDB运行的HBase表
如果你第一次用你的HBase实例运行OpenTSDB,需要创建必要的HBase表,OpenTSDB 运行仅仅需要四张表:tsdb, tsdb-uid, tsdb-tree 和 tsdb-meta,所有的DataPoint 数据都保存在这四张表中,建表语句如下:
1、tsdb-uid
create 'tsdb-uid',
{NAME => 'id', COMPRESSION => 'NONE', BLOOMFILTER => 'ROW', DATA_BLOCK_ENCODING => 'PREFIX_TREE'},
{NAME => 'name', COMPRESSION => 'NONE', BLOOMFILTER => 'ROW', DATA_BLOCK_ENCODING => 'PREFIX_TREE'}
2、tsdb
create 'tsdb',
{NAME => 't', VERSIONS => 1, COMPRESSION => 'NONE', BLOOMFILTER => 'ROW', DATA_BLOCK_ENCODING => 'PREFIX_TREE'}
3、tsdb-tree
create 'tsdb-tree',
{NAME => 't', VERSIONS => 1, COMPRESSION => 'NONE', BLOOMFILTER => 'ROW', DATA_BLOCK_ENCODING => 'PREFIX_TREE'}
4、tsdb-meta
create 'tsdb-meta',
{NAME => 'name', COMPRESSION => 'NONE', BLOOMFILTER => 'ROW', DATA_BLOCK_ENCODING => 'PREFIX_TREE'}
后面将对照实际数据来专门讲解这四张表分别存储的内容。
五、 OpenTSDB是如何把一个数据点保存到HBase中的呢?
1、首先检查一下四个表里面的数据
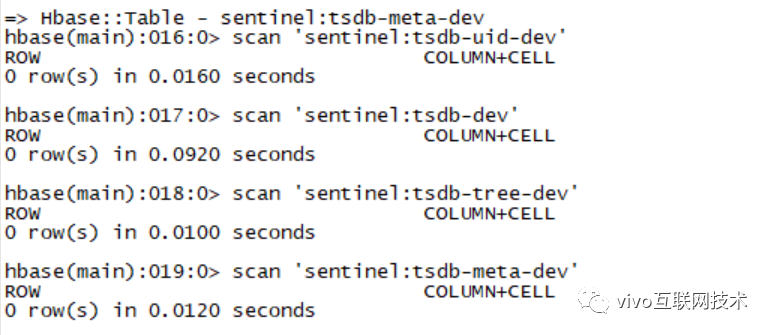
从上面看,四个表里面的数据都是空的
2、然后我们往OpenTSDB写一个数据点
@Test
public void addData() {
String metricName = "metric";
long value = 1;
Map<String, String> tags = new HashMap<String, String>();
tags.put("tagk", "tagv");
long timestamp = System.currentTimeMillis();
tsdb.addPoint(metricName, timestamp, value, tags);
System.out.println("------------");
}
3、插入数据之后我们再来查看一下四个表数据
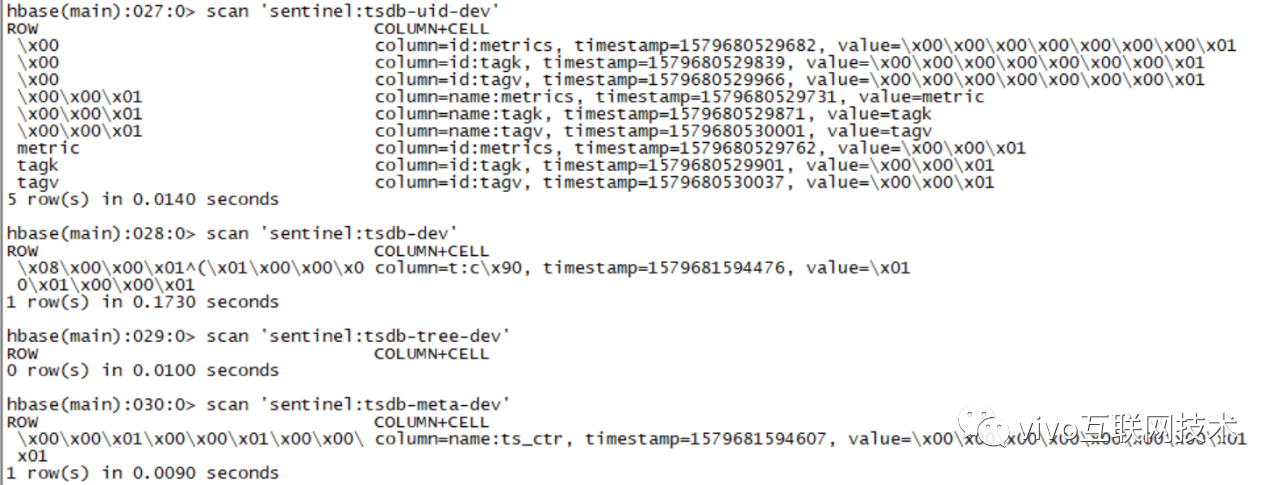
发现HBase里面有数据,在tsdb-uid、tsdb、和 tsdb-meta 表里面有数据,而tsdb-tree 表里面没任何数据,下面我们针对这些数据做一下具体分析。
4、tsdb-tree表
它是一张索引表,用于展示树状结构的,类似于文件系统,以方便其他系统使用,这里我们不做深入的分析。
通过配置项tsd.core.tree.enable_processing来打开是否需要往此表里面写入数据。
5、tsdb-meta表
这个表是OpenTSDB中不同时间序列的一个索引,可以用来存储一些额外的信息,该表只有一个列族name,两个列,分别为ts_meta、ts_ctr。这个表里面的数据是可以根据配置项配置来控制是否生成与否,生成几个列,具体的配置项有:
tsd.core.meta.enable_realtime_ts
tsd.core.meta.enable_tsuid_incrementing
tsd.core.meta.enable_tsuid_tracking

Row Key 和tsdb表一样,其中不包含时间戳,<metric_uid><tagk1><tagv1>[...<tagkN><tagvN>]
ts_meta Column 和UIDMeta相似,其为UTF-8编码的JSON格式字符串
ts_ctr Column 计数器,用来记录一个时间序列中存储的数据个数,其列名为ts_ctr,为8位有符号的整数。
6、tsdb-uid表数据分析
tsdb-uid用来存储UID映射,包括正向的和反向的。存在两列族,一列族叫做name用来将一个UID映射到一个字符串,另一个列族叫做id,用来将字符串映射到UID。列族的每一行都至少有以下三列中的一个:
- metrics 将metric的名称映射到UID
- tagk 将tag名称映射到UID
- tagv 将tag的值映射到UID
如果配置了metadata,则name列族还可以包括额外的metatata列。

6.1、id 列族
- Row Key:实际的指标名称或者tagK或者tagV
- Column Qualifiers:metrics、tagk、tagv三种列类型中一种
- Column Value : 一个无符号的整数,默认是被编码为3个byte,自增的数字,其值为UID
6.2、name 列族
- Row Key :UID,就是ID列簇的值
- Column Qualifiers:metrics、tagk、tagv、metrics_meta、tagk_meta、tagv_meta六种列类型中一种,*_meta是需要开启tsd.core.meta.enable_realtime_uid才会生成
- Column Value:与UID对应的字符串,对于一个*_meta列,其值将会是一个UTF-8编码的JSON格式字符串。不要在OpenTSDB外部去修改该值,其中的字段顺序会影响CAS调用。
7、tsdb表:
时间点数据就保存在此表中,只有一个列簇t:


7.1、RowKey格式
- UID:默认编码为3 Bytes,而时间戳会编码为4 Bytes
- salt:打散同一metric不同时间线的热点
- metric, tagK, tagV:实际存储的是字符串对应的UID(在tsdb-uid表中)
- timestamp:每小时数据存在一行,记录的是每小时整点秒级时间戳

7.2、Column格式
column qualifier 占用2 Bytes或者4 Bytes,
占用2 Bytes时表示以秒为单位的偏移,格式为:
- 12 bits:相对row表示的小时的delta, 最多2^ 12 = 4096 > 3600因此没有问题
- 1 bit: an integer or floating point
- 3 bits: 标明数据的长度,其长度必须是1、2、4、8。000表示1个byte,010表示2byte,011表示4byte,100表示8byte
占用4 Bytes时表示以毫秒为单位的偏移,格式为:
- 4 bits:十六进制的1或者F
- 22 bits:毫秒偏移
- 2 bit:保留
- 1 bit: an integer or floating point,0表示整数,1表示浮点数
- 3 bits: 标明数据的长度,其长度必须是1、2、4、8。000表示1个byte,010表示2byte,011表示4byte,100表示8byte
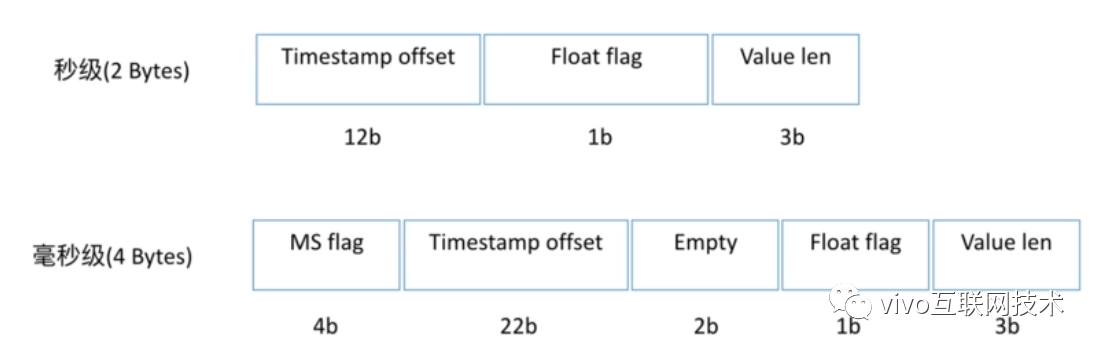
7.3、value
value 使用8 Bytes存储,既可以存储long,也可以存储double。
7.4、tsdb表设计的特点:

- metric和tag映射成UID,不存储实际字符串,以节约空间。
- 每条时间线每小时的数据点归在一行,每列是一个数据点,这样每列只需要记录与这行起始时间偏移,以节省空间。
- 每列就是一个KeyValue。
六、 写在最后
1、应用场景
- 作为时序数据库,OpenTSDB 不仅仅可以提供原始数据的查询,并且还支持对原始数据的聚合能力,支持过滤、过滤之后的聚合计算。
- 支持降采样查询,比如原始数据是1分钟一个数据点,如果我想1个小时一个数据点进行展示,也能支持。
- 支持根据维度分组查询,比如我有一个中国地市的数据,现在我想根据省份进行分组之后查询,也能支持。
2、使用注意事项
- OpenTSDB 默认情况下的字符集是ISO-8859-1,为什么会使用这个字符集呢,是因为它的编码是单字节编码,编码后的长度是固定的,如果要支持中文,需要对源码进行编译,修改为UTF-8即可。
- 默认提供的HBase建表语句是没有预分区的,这样会导致大批量数据写入的时候有热点问题,建议进行预分区。
- OpenTSDB不适合超大数据量,在千万级、亿级中提取几万条数据,比如某个指标半年内的5分钟级别的数据,还是很快响应的。但如果再提取多点数据,几十万,百万这样的量级,又或者提取后再做个聚合运算,OpenTSDB 就勉为其难,实际使用的时候用作服务端机器的监控无任何问题,如果作为客户端APP监控,响应就比较迟缓。
- OpenTSDB 只有4 张HBase 表,所有的数据都存放在一张表,这就意味在OpenTSDB 这个层级上是无法更小的粒度来区别对待不同业务,比如不同的业务建不同的表存储数据。
- OpenTSDB 支持实时聚合计算功能,但是基于单点,所以运算能力有限。
3、展望
如果需要支持特大批量时序数据,建议使用Druid或InfluxDB,其中InfluxDB是最易用的时序数据库。
更多内容敬请关注vivo 互联网技术微信公众号
注:转载文章请先与微信号:Labs2020联系。
OpenTSDB 数据存储详解的更多相关文章
- ContentProvider数据访问详解
ContentProvider数据访问详解 Android官方指出的数据存储方式总共有五种:Shared Preferences.网络存储.文件存储.外储存储.SQLite,这些存储方式一般都只是在一 ...
- 【HANA系列】SAP HANA XS使用JavaScript数据交互详解
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA XS使用Jav ...
- JVM 运行时数据区详解
一.运行时数据区 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同数据区域. 1.有一些是随虚拟机的启动而创建,随虚拟机的退出而销毁,所有的线程共享这些数据区. 2.第二种则 ...
- Hbase存储详解
转自:http://my.oschina.net/mkh/blog/349866 Hbase存储详解 started by chad walters and jim 2006.11 G release ...
- 【HANA系列】【第一篇】SAP HANA XS使用JavaScript数据交互详解
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列][第一篇]SAP HANA XS ...
- 3dTiles 数据规范详解[1] 介绍
版权:转载请带原地址.https://www.cnblogs.com/onsummer/p/12799366.html @秋意正寒 Web中的三维 html5和webgl技术使得浏览器三维变成了可能. ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- html5的web存储详解
以前我们在本地存储数据都是用document.cookie来存储的,但是由于其的存储大小只有4K左右,解析也很复杂,给开发带来了诸多的不便.不过现在html5出了web的存储,弥补了cookie的不足 ...
- [jvm]运行时数据区域详解
了解虚拟机是怎么使用内存的,有助于我们解决和排查内存泄漏和溢出方面的问题.详解java虚拟机内存的各个区域,分析这些区域的作用服务对象以及可能发生的问题. 一.运行时数据区域 java虚拟机在执行ja ...
- HTTP数据包详解
无论Web技术在未来如何发展,理解Web程序之间通信的基本协议相当重要, 因为它让我们理解了Web应用程序的内部工作. 本文将对HTTP协议进行详细的实例讲解,内容较多,希望大家耐心看. 阅读目录 ...
随机推荐
- 【GIT】学习day04 | 将本地代码推送到码云仓库中进行管理【外包杯】
仓库代码页 将本能仓库和码云仓库进行关联 代码组成 git remote add origin 加上下面的地址 将本地仓库的代码推送到码云仓库上 git push -u origin master 之 ...
- jmeter工具中vars与props命令的区别和使用
话不多说直接干活!!!!! vars 和 props命令存在于"jsr223 预处理器"."BeanShell 预处理程序"."JSR223 后置处理 ...
- OpenTiny Vue 3.12.0 发布:文档大优化!增加水印和二维码两个新组件🎈
你好,我是 Kagol. 非常高兴跟大家宣布,2023年11月30日,OpenTiny Vue 发布了 v3.12.0 . OpenTiny 每次大版本发布,都会给大家带来一些实用的新特性,10.24 ...
- Android 图表开源库调研及使用示例
原文地址: Android图表开源库调研及使用示例 - Stars-One的杂货小窝 之前做的几个项目都是需要实现图表统计展示,于是做之前调研了下,做下记录 概述 AAChartCore-Kotlin ...
- MongoDB是一个NoSQL数据库,有着多种不同的命令和操作。以下是一些常见的MongoDB命令:
show dbs:列出所有数据库 use db_name:切换到指定的数据库 db.dropDatabase():删除当前数据库 db.createCollection("collectio ...
- [ARC132E] Paw
题目链接 考虑最后形态,一定是有某一个区间 \([l,r]\) 保持初始的样子, \(l\) 前面都是 <,\(r\) 后面都是 >. 这个区间一定是某两个相邻圆点的位置.设 \(f_i\ ...
- 【笔记整理】使用Session会话保持
import requests if __name__ == '__main__': # Session对象实现了客户端和服务器端的每次会话保持功能. session = requests.Sessi ...
- Kernel Memory 入门系列:文档的管理
Kernel Memory 入门系列: 文档的管理 在Quick Start中我们了解到如何快速直接地上传文档.当时实际中,往往会面临更多的问题,例如文档如何更新,如何划定查询范围等等.这里我们将详细 ...
- 从零玩转Nginx
01[熟悉]实际开发中的问题? 现在我们一个项目跑在一个tomcat里面 当一个tomcat无法支持高的并发量时.可以使用多个tomcat 那么这多个tomcat如何云分配请求 |-nginx 02[ ...
- NoClassDefFoundError: javax/el/ELManager
Caused by: java.lang.NoClassDefFoundError: javax/el/ELManager at org.hibernate.validator.messageinte ...