vivo 应用商店推荐系统探索与实践
介绍 vivo 应用商店推荐系统如何高效支撑个性化的推荐需求。
一、前言
商店的应用数据主要来源于运营排期、CPD、游戏、算法等渠道,成立推荐项目之后也没有变化,发生变化的是由推荐系统负责和数据源进行对接,商店服务端只需要和应用推荐系统进行对接即可。
如果读者以为我们单纯是把商店服务端代码给照搬到推荐系统这边来了那就真的是too young too simple 了,不做优化或者升级直接copy一个系统是不可能的,这辈子都不可能。以下我将介绍我们如何去设计和规划应用推荐系统的。
二、面临的挑战
在笔者眼中,商店应用推荐系统除了要具备高性能、高可用性及核心指标的监控能力之外,还有一个核心的能力就是高效支撑商店流量场景接入个性化推荐。
如何定义高效支撑?
- 最起码能支撑三四个并行的需求同时进行吧。
- 一个需求开发周期最起码不能超过2天吧。
- bug少一点吧,平均下来每个场景不应该超过2个吧。
- 产品同学的常态性的需求基本都能快速支持吧。
分享我们一个应用推荐的策划case看看:
在xx场景下,
如果主应用A属于应用类,
- 则首先从从x1数据源去取Q1队列。
- 然后从x2数据源去取Q2队列。
- 然后用Q2队列去截断Q1队列,交集之后进行同开发者过滤和一级分类过滤。
- 如果交集为空则用Q2去兜底,然后取交集队列的n1和n2 位置上的元素作为返回队列。
- 如果前面都没有取到数据的话从大数据xxx表中按照主应用下应用点击的概率取点击率最高的分类下的n个,同时需要对这些数据进行队列内的同开发者过滤。
如果主应用A属于游戏类,
- 则xxxx
- 进行二级分类过滤
- 如果量不足的话,则从x(n)取数据然后进行处理,
- 如果数据不足3个的话,需要从周榜单中取同一级分类下的应用按照下载排行进行兜底。
没错,读者朋友不要怀疑自己,为了不把各位读者大大绕晕,我们这里只是挑选了一个简单的需求。实现这么一个功能也没有什么大不了的,但是当这种个性化推荐需求有几十个,后面还可能一致扩展下去的时候会不会心里发慌?来,简单看下我们现在个性化推荐的一部分需求,如图(一)所示:
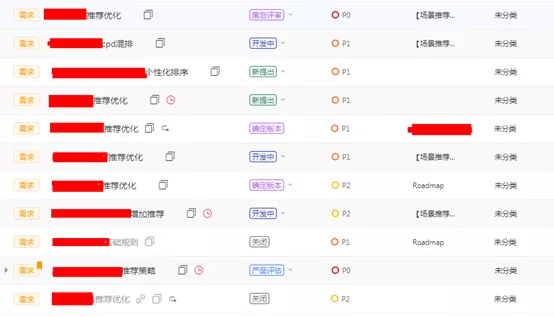
图(一)
使用商店服务端之前的case by case的开发方案,无论如何都无法实现上文中描述的要支撑商店高效接入推荐场景了,接着就是我们如何去实现优化的过程了。
三、如何解决
为了更好的说明解决思路,我们从实际思考过程出发,一步步讲解问题的解决过程。
3.1 业务流程抽象
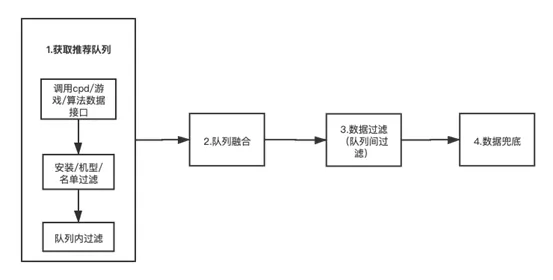
单纯从策划上面来说,我们每个场景都需要至少做如图(二)中的几件事情:

图(二)
- 获取推荐列表:调用各个数据源获取的推荐队列(需要注意的是不同场景下调用的接口并不一致,此外接口返回的字段和结构可能也不一样)。
- 队列融合:将1中提到的进行交集或者并集并等操作。
- 数据过滤(队列内/队列间):在队列中进行各项过滤,过滤操作主要是为了提升相关性。
- 数据兜底:指在队列数据不够的时候,用榜单兜底,可能取周榜单数据的同一级分类数据,同二级分类数据。
笔者从开发便捷性出发,对模型进行了进一步的调整,调整后为图(三)
图(三)
获取队列后对队列进行安装过滤和队列内过滤(如主应用同开发者过滤等)可以进行流程合并,主要有如下的原因
- 方便定义每一个数据源的过滤策略,实际需求中不同的队列也会使用不同的过滤策略。
- 这种方式非常匹配模板设计模式,能确保我们获取推荐列表过程是一致和稳定的。
3.2 抽象流程延伸
到图(三)这里,读者会发现我们依然没有能够解决我们前面提到的各种推荐场景里面的差异化过程。
其实在接触几个需求以后,我们会发现,想要在一套代码里面去解决这么大的差异性,几乎不可能,或者即使实现了,那么也会让代码变得无比复杂。与其这样子,我们还不如正视这种差异性,让差异在场景插件里面去实现,我们花更多的精力去打理主干。
那么为了支持让场景能够具备灵活的扩展能力,笔者在基于图(三)的基础上增加了四个环节:
- 队列结果线程内共享:使用ThreadLocal来实现。存储各推荐队列的结果主要是为了便于后续使用某推荐队列做填充的需求,另外就是避免需要再重复请求三方数据接口,减少接口重复调用。
- 插件队列兜底:主要目的是在过滤后在数量不足需求的情况下,使用指定的队列完成填充,场景插件亦可按需填写实现填充逻辑,实现队列内容的补充。
- 插件接口回调:该环节主要是对前面的队列做个性化的处理,如对队列进行干预等,没有将插件接口回调和插件队列兜底融合在一起主要原因是插件队列融合可以实现可配置化的设置。
- 周榜单兜底:提供通用的周榜单数据查询能力,支持按照各种维度进行查询,此部分数据作为队列的最后兜底。
拓展后的流程图如图(四)所示
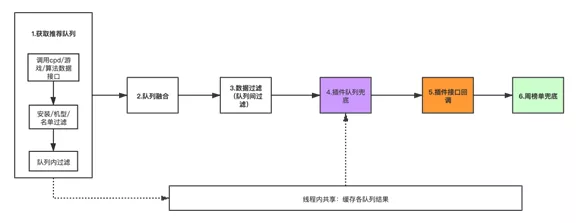
图(四)
3.3 整体逻辑框图
经过上述的分析可知,我们可以尽可能的把个性化的场景内容放在插件层实现,框架层负责加载按场景加载场景插件的具体个性化推荐逻辑。
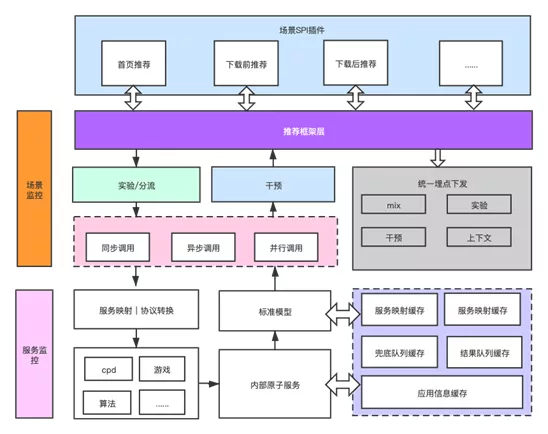
系统从分层思路上讲从上至下共分为:插件层,框架层,协议适配层,数据源服务层,原子服务层,基础服务层,上层通过 SDK 依赖下层的服务(接口),各层次职责为:
- 插件层:各个场景对应的插件,框架层对插件回调或者扩展接口提供默认实现,插件层按需实现具体的逻辑。
- 框架层:定义推荐数据的核心流程和执行逻辑,回调插件层的实现的扩展和回调接口。
- 协议适配层:负责按照场景找到场景对应的数据源服务,并封装转换协议和进行数据转换。
- 数据源服务层:与各个队列提供方提供的RPC服务封装层。
- 原子服务层:过滤类型的相关服务,主要是依赖于商店的 RPC 服务,使用组合的设计模式,服务可以进行组合。
- 基础服务层:支持从开发者、一级分类、二级分类、应用类型等纬度进行相关性的判断或者过滤,同原子服务层一样,此层服务也是原子粒度,支持进行组合控制。
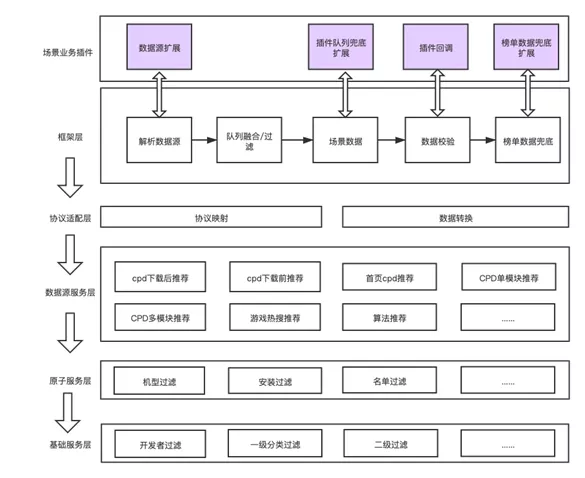
至此,相信大家都知晓了,针对于个性化的推荐,我们的开发工作最终将聚焦于开发场景插件,不需要再额外开发每一个业务流程了。
应用推荐系统架构
3.4 关键实现
在完成第三步整体逻辑框图设计之后,我们从场景参数定义,服务设计原则,设计模式使用,场景热插拔等方面进行了相关的方案研究并最终实现了方案的落地。
3.4.1 场景服务参数定义
为实现推荐场景足够通用,我们将数据源层,原子服务层,基础服务层的内容进行了服务配置的映射,通过在配置中定义对应的配置项来实现服务的映射和组合,针对于差异性的内容在插件层进行实现。以如下的配置项示意图来说明:
- sourceMap:场景服务定义为map用于支持场景下多个模块或者实验组的情形,其中key为模块ID,商店服务端请求推荐的时候,需要携带此参数。
- cpdRequest 、algorithmRequest 、gameRequest:用于定义对应的RPC调用的请求参数。
- filterRequest:用于定义队列内的过滤请求,如主应用同开发者过滤等。
- unionStrategy:定义队列合并和融合及队列间的合并规则。
- supplement:兜底策略;
- sourceList:使用的数据源,如上图中定义了两个数据源,则表示在此场景下需要从两个数据源获取数据,然后进行队列合并及后处理。

3.4.2 服务原子化与唯一化
实现服务原子化与服务唯一化对本系统至关重要,在实现过程中是严格遵照如下两点来:
应用推荐依赖的三方RPC服务及内部的一些过滤逻辑都封装成了细粒度的原子服务(方法)的SDK。SDK中的内容不包含个性化推荐场景的具体业务性的能力,体现的重点是基础功能项,业务内容需要在场景插件中进行实现,统一类型的服务尽可能支持组合。
服务唯一化在对于实现系统的收敛和代码规模可控至关重要,我们也是不断的在朝着这个努力。各服务层都是以SDK的形式对外提供相关的功能,在SDK中实现服务调用入口的唯一性。
3.4.3 合理使用设计模式
系统中使用了较多的设计模式来优化整体架构,如下重点来介绍使用的模板设计模式、策略模式及组合模式:
在获取推荐原始队列中使用了模板设计模式和策略模式来实现此过程。
使用模板设计模式的好处显而易见,能够容易促进此部分处理逻辑流程化。
针对不同的数据源,需要使用不同的数据源服务和方法,使用策略模式的好处是便于定义在不同场景下对不同的接口的调用。
同类型的原子服务或者方法尽可能支持组合模式,这种会为后续的扩展提供很大的便利性。
以实际的实现方法来说明,在我们定义过滤类型的时候,支持传入多个过滤类型,上层业务在使用的时候按需传入即可。使用组合的设计模式在提升扩展性方面起到了巨大的作用。
3.4.4 场景的热插拔
系统中为实现场景之间的隔离和互不干扰,笔者使用了Java SPI的方式,在框架层定义了场景接口,接口实现类则在各个场景在独自的Jar中实现。这种方式有助于插件程序对框架层和基础服务层的侵入性降到最低。
四、带来的改变
以前商店服务端在各个接口的service层写完整的推荐队列获取、融合、组装、过滤逻辑,有大量的重复内容,且随着版本的不断迭代,有很多版本不同的处理逻辑夹杂在一起,导致改造难升级难,牵一发动全身。目前应用推荐系统在两个方向带来较大改善:
- 流程框架的逻辑完全抽象并独立,各个业务场景只需要按需写很少的插件回调逻辑即可,(不涉及十分特殊的场景可完全不用写插件回调扩展,通过配置对应的场景规则配置即可,可完全实现免开发,目前有30%左右的场景免开发)。
- 场景之间完全隔离和独立, 涉及复杂的功能升级可通过升级对应的场景id或者模块id来做增量实现,不影响现有逻辑。
五、写在最后
通过上述相关的方案落地,针对于各个推荐场景,我们大概减少了75%的开发工作量,同时bug率也得到大幅度的降低。
作者:vivo-Huang Xiaoqun
vivo 应用商店推荐系统探索与实践的更多相关文章
- vivo 故障定位平台的探索与实践
作者:vivo 互联网服务器团队- Liu Xin.Yu Dan 本文基于故障定位项目的实践,围绕根因定位算法的原理进行展开介绍.鉴于算法有一定的复杂度,本文通过图文的方式进行说明,希望即使是不懂技术 ...
- FFM及DeepFFM模型在推荐系统的探索及实践
12月20日至23日,全球人工智能与机器学习技术大会 AiCon 2018 在北京国际会议中心盛大举行,新浪微博AI Lab 的资深算法专家 张俊林@张俊林say 主持了大会的 搜索推荐与算法专题,并 ...
- vivo 云原生容器探索和落地实践
作者:vivo 互联网容器团队- Pan Liangbiao 本文根据潘良彪老师在"2022 vivo开发者大会"现场演讲内容整理而成.公众号回复[2022 VDC]获取互联网技术 ...
- 分支路径图调度框架在 vivo 效果广告业务的落地实践
作者:vivo 互联网AI团队- Liu Zuocheng.Zhou Baojian 本文根据周保建老师在"2022 vivo开发者大会"现场演讲内容整理而成.公众号回复[2022 ...
- NSIS:应用软件自动升级功能的探索与实践
原文 NSIS:应用软件自动升级功能的探索与实践 记得以前轻狂曾分享过使用第三方软件实现应用软件自动升级功能 (详细http://www.flighty.cn/html/soft/20110106_1 ...
- FPGA加速:面向数据中心和云服务的探索和实践
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由columneditor 发表于云+社区专栏 作者介绍:章恒--腾讯云FPGA专家,目前在腾讯架构平台部负责FPGA云的研发工作,探索 ...
- 从C10K到C10M高性能网络的探索与实践
在高性能网络的场景下,C10K是一个具有里程碑意义的场景,15年前它给互联网领域带来了非常大的挑战.发展至今,我们已经进入C10M的场景进行网络性能优化. 这期间有怎样的发展和趋势?环绕着各类指标分别 ...
- zz深度学习在美团配送 ETA 预估中的探索与实践
深度学习在美团配送 ETA 预估中的探索与实践 比前一版本有改进: 基泽 周越 显杰 阅读数:32952019 年 4 月 20 日 1. 背景 ETA(Estimated Time of A ...
- 深度学习在高德ETA应用的探索与实践
1.导读 驾车导航是数字地图的核心用户场景,用户在进行导航规划时,高德地图会提供给用户3条路线选择,由用户根据自身情况来决定按照哪条路线行驶. 同时各路线的ETA(estimated time of ...
- 国产开源数据库:腾讯云TBase在分布式HTAP领域的探索与实践
导语 | TBase 是腾讯TEG数据平台团队在开源 PostgreSQL 的基础上研发的企业级分布式 HTAP 数据库系统,可在同一数据库集群中同时为客户提供强一致高并发的分布式在线事务能力以及高 ...
随机推荐
- PX4环境安装
1.安装ROS 利用鱼香ros一键安装: wget http://fishros.com/install -O fishros && . fishros 调用的命令为: roscore ...
- SpringBoot进阶教程(七十八)邮件服务
Sun公司提供了JavaMail用来实现邮件发送,但是配置烦琐,Spring中提供了JavaMailSender用来简化邮件配置,Spring Boot则提供了MailSenderAutoConfig ...
- VM离线安装Centos 8以及配置
一.安装 1.预装准备 1.1. 硬件准备 物理内存:2G以上(这里指系统搭建所需占用空间) 物理外存:20G(这里指系统搭建所需占用空间) 1.2. 环境搭建准备 Window10系统电脑一台.Vm ...
- Vue项目的创建、运行与端口号修改
前言:Vue-cli是Vue官方提供的一个脚手架,用于快速生成一个Vue的项目模板,依赖于NodeJS环境 NodeJS下载:NodeJS安装下载 Vue-cli下载:Vue-cli下载 一.Vue图 ...
- Redis入门实践
安装Redis 下载:官网:https://redis.io/download/,选择稳定版下载. 上传至linux 解压Redis:tar -zxvf redis-6.2.7.tar.gz,得到: ...
- 数据库系列:业内主流MySQL数据中间件梳理
数据库系列:MySQL慢查询分析和性能优化 数据库系列:MySQL索引优化总结(综合版) 数据库系列:高并发下的数据字段变更 数据库系列:覆盖索引和规避回表 数据库系列:数据库高可用及无损扩容 数据库 ...
- Roaring bitmaps
Roaring bitmaps 最近看一篇文章,里面涉及到使用roaring bitmaps来推送用户广告并通过计算交集来降低用户广告推送次数.本文给出roaring bitmaps的原理和基本用法, ...
- 深度解析 PyTorch Autograd:从原理到实践
本文深入探讨了 PyTorch 中 Autograd 的核心原理和功能.从基本概念.Tensor 与 Autograd 的交互,到计算图的构建和管理,再到反向传播和梯度计算的细节,最后涵盖了 Auto ...
- 想了解Python中的super 函数么
摘要:经常有朋友问,学 Python 面向对象时,翻阅别人代码,会发现一个 super() 函数,那这个函数的作用到底是什么? 本文分享自华为云社区<Python 中的 super 函数怎么学, ...
- Solon 拉取 maven 包很慢或拉不了,怎么办?
注意:如果在 IDEA 设置里指定了 settings.xml,下面两个方案可能会失效.(或者直接拿"腾讯" 的镜像仓库地址,按自己的习惯配置) 1.可以在项目的 pom.xml ...