SCA 技术进阶系列(二):代码同源检测技术在供应链安全治理中的应用
直击痛点:为什么需要同源检测
随着 “数字中国” 建设的不断提速,企业在数字化转型的创新实践中不断加大对开源技术的应用,引入开源组件完成应用需求开发已经成为了大多数研发工程师开发软件代码的主要手段。随之而来的一个痛点问题是:绝大多数的应用程序都包含开源组件风险。因而,能够帮助管理和降低开源组件风险的 SCA 技术应运而生。
常规的 SCA 软件成分分析工具可以通过分析组件版本及依赖,完成对引用的三方开源组件的检查,从而识别已知的组件漏洞以及授权许可风险。但是,组件漏洞来源于代码编写存在的安全缺陷,对于引用开源组件源码的部分代码片段,从而导致引入存在安全缺陷代码的场景,则需要使用代码同源检测技术进行检查。代码同源检测是基于源代码文件的维度面向源代码进行成分分析,主要用于代码溯源分析、代码已知漏洞分析、恶意代码文件等,可以准确地分析出引用的开源软件及其关联信息。本文将从代码同源检测技术原理、核心技术和常见应用场景三大方面对该技术进行解析。
原理浅析:同源检测技术原理介绍
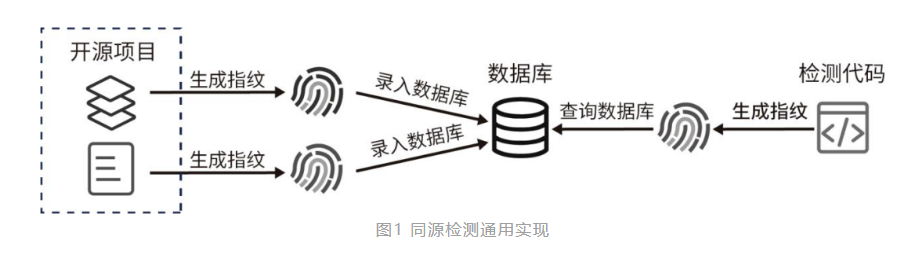
同源检测即同源性分析,指对应用程序或软件中的组成成分进行同源性分析,按照分析的精度划分,精度由低到高可将同源检测分为文件级、函数级和片段级。代码同源检测技术主要用于检测应用源代码中某个片段代码与项目中其他片段代码或开源代码存在的相同代码成分,因此也被称为代码克隆检测。
代码克隆(Code Clone),是指本地代码库或开源代码库中存在多个以上相同或者相似的源代码片段。使用克隆代码在代码开发过程中也是提高开发效率的一种方式,一定程度上帮助了软件系统的开发,但这种方式也可能意外引入代码片段本身存在的安全风险或授权许可风险等负面影响。随着软件在敏捷开发的模式下不断迭代,代码克隆造成代码库的不断膨胀,在未有良好的克隆管理的情况下,从而增加维护成本。软件缺陷也会因为代码克隆而在系统中被传播,,降低了软件系统的可靠性。因此,运用代码克隆检测技术可实现满足 SCA 能够检测分析应用程序中引入的开源组件、分析开源组件是否有已知的安全漏洞、分析应用程序或开源组件声明的开源许可证、对源代码进行溯源分析等核心功能。
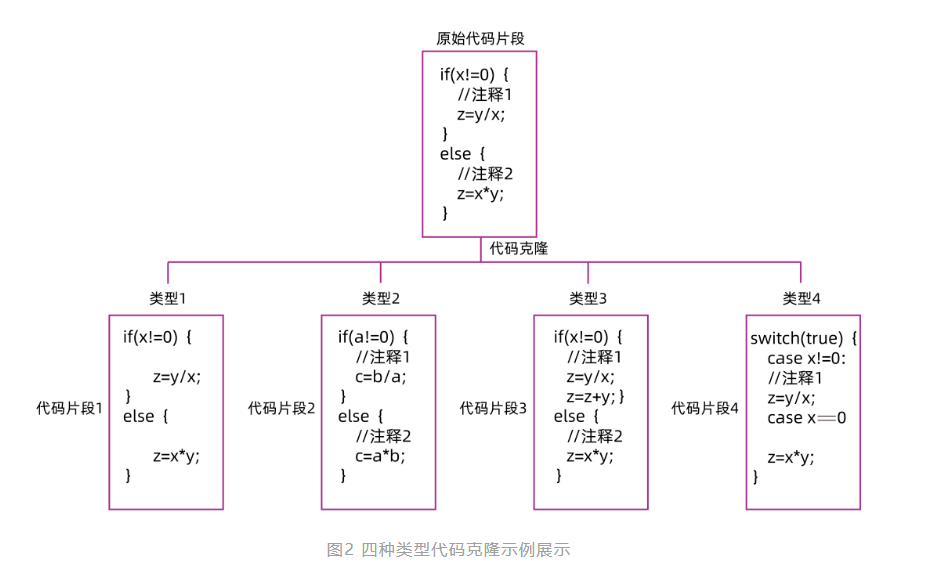
1. 代码克隆四种类型
严格意义上的代码克隆则是指对原始代码片段或代码文件的整体克隆,代码开发者直接使用原始代码片段或文件,两者内容完全一致,未进行任何修改。但从实际应用需求看,通常将代码克隆的类型分为 4 类:
类型 1,完全克隆:除注释与空白符外,两个代码片段完全相同。
类型 2,重命名克隆:对代码的变量、类型、文字和函数名进行修改,两个代码片段逻辑内容一致。
类型 3,增删改克隆:在类型 2 的基础上,对一些代码语句进行添加、删除或修改,以及修改源代码内容布局,两个代码片段内容相似。
类型 4,自实现克隆:两个代码片段的逻辑功能相同,但是具体的编码实现方式不同,例如通过替换同类型函数或表达式实现,其时间复杂度和输入输出一致。
对于检测方法而言,其中类型 1、类型 2、类型 3 主要通过文本相似性检测技术实现,类型 4 则需要通过功能相似性进行检测。类型越靠后,其检测难度越高。
2. 常规代码克隆检测流程
为有效实现对代码克隆的检测,主要技术包含了代码格式转换和相似度确定。针对不同的代码克隆检测工具,实现的技术原理具有一定的差异性,但其主要的执行流程大致相同,可以总结为以下流程:
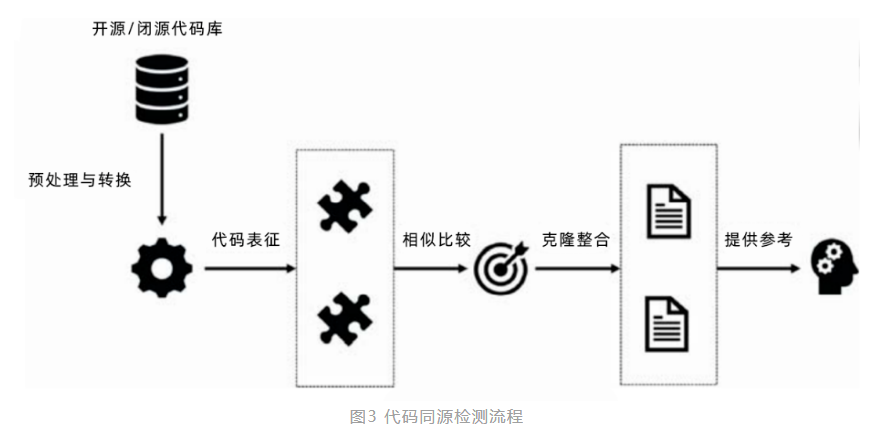
1)开源 / 闭源代码库:当作为代码克隆检测的主要知识库依据时,提前收集足够完整的开源 / 闭源代码项目,利用特定算法形成知识库特征表集合;当作为检测目标时,通过预处理移除无意义的代码片段并进行转换,执行特定的相似性比较方法,获得克隆检测结果。
2)预处理与转换:针对软件供应链安全检测场景,需要对缺陷代码、主干核心代码进行预处理,去除无意义源代码部分,将代码进行标准化,可通过将源代码分为不同的片段,转换为可比较的单元。比较单元的转换方法包含多种,视其具体检测原理不同而定。
3)源代码表征:在这一步骤中,可以将源代码表征为文本,或者进一步利用符号进行表征,用于方便存储记录或后续进行比较验证,更深入的表征方式还包括将源代码转换成抽象语法树(AST,Abstract Syntax Tree)等。
4)代码相似度比较:在这一步骤中,每一个代码片段都会与其他代码片段进行对比来找到代码的克隆,比对的结果将以克隆对列表的方式呈现。其中,相似比较的算法很大程度上由源代码表征方式决定。如,将 AST 作为一种源代码表征方式,则这类源代码表征方式将决定选用何种适合的相似度算法。
5)代码克隆结果整合:这一个步骤主要是将前几个步骤获得的代码克隆和原始的源代码关联起来并以适当的方式呈现。将检测结果提交给需求方,且提供给源代码所有者参考,要求去除或整改。
3. 核心检测算法
01 基于文本的代码克隆检测方法
基于预处理的源代码(删除空格、注释等),使用文本相似度检测算法直接检测代码克隆。当文本相似度检测基于源码比较时,基于文本的检测方法能够覆盖类型 1 完全克隆和类型 2 重命名克隆的代码克隆检测。然而文本相似度检测并不局限于纯源码的比较。由于源代码本身有意义,直接作为文本处理会丢失大量信息,因此将源码提取特征指纹以后,也是两个字符串文本的比较。再利用特殊的算法,能够实现对类型 3 增删改的覆盖。后期如果能够实现基于自然语言处理的相似度算法,理论上来讲类型 4 自实现克隆也是可以覆盖的,不过这一步可能需要较长的时间。
02 基于令牌的代码克隆检测方法
使用词法分析器将源代码划分为令牌序列,然后在令牌序列中找到相似的子序列。基于令牌的检测方法对源代码进行词法分析,符号序列更符合编译原则,源代码信息得到了更充分的利用。但它缺乏对代码语法和语义的分析,对类型 3 和类型 4 代码克隆的检测效果并不理想。
03 基于树的代码克隆检测方法
是将源代码表示为抽象语法树或代码解析树,然后使用树匹配算法找到相似或相同的子树,从而检测克隆代码。该方法对源代码进行语法分析,进一步提高了对源代码信息的利用,可以更好地检测类型 3 代码克隆,提高检测精度。
04 基于度量的代码克隆检测方法
提取源代码特定索引指标(如代码的数量、变量的数量、循环的数量),将它们抽象到特征向量,然后确定克隆基于特征向量之间的距离,这种方法在速度上有很大的优势。
05 基于图的代码克隆检测方法
将源代码转换为由数据流图和控制流图组成的程序依赖图(PDG,Program Dependence Graph),并通过寻找齐次子图来实现克隆检测。基于图的克隆代码检测方法不仅利用了源代码的语法结构,而且在一定程度上考虑了源代码的语义信息,因此该方法可以检测类型 4 代码克隆。然而,由于程序依赖图生成算法和同构程序依赖图子图匹配方法的时空复杂度较高,因此基于图的代码克隆检测方法不能应用于大型软件系统的代码克隆检测。
4. 代码克隆检测能力评估
不同的代码克隆检测方法适用于不同规模、编程语言和结构的软件系统。为了评价检测方法能力,一般采用以下评价指标:
召回率:所有被检测到的代码克隆数量与代码克隆总数的比值。
召回率 = TP /(TP + FN)
检测精度:指克隆检测算法所检测到的代码克隆为真实代码克隆的比值。
检测精度 = TP /(TP + FP)
表达式说明:TP 表示某种代码克隆检测方法检测到的克隆片段与真实代码克隆片段的交集,FP 表示代码克隆的集合,FN 表示该检测方法未检测到的真实代码克隆片段的集合。
类似于常规的漏洞检测工具,OWASP Benchmark 作为漏洞扫描工具检测基准能力评估的靶场项目。关于代码克隆检测工具领域,也具有对应的代码克隆检测有效性评估的靶场项目。比如:
1)发布于 2007 年的 Bellon’s benchmark:针对两个小型 C 程序和两个小型 Java 程序,运行六个不同的代码克隆工具,并对这些结果与真实代码克隆的主体进行比较,以创建代码克隆的数据集。
2)发布于 2015 年的 BigCloneBench:是 IJaDataset-2.0(包含 25000 个开源 Java 系统的大数据软件存储库)中的 800 万个经过验证的代码克隆的集合。其项目内和项目间,包含了四种主要的代码克隆类型。
深度解析:同源检测核心技术
结合行业企业用户的痛点及需求,基于代码克隆检测底层技术实现的同源检测技术可分为代码溯源分析、代码已知漏洞分析、恶意代码文件分析三大类别。
1. 代码溯源分析
在 SCA 中代码溯源分析技术旨在通过检测目标代码,溯源目标代码引用的第三方开源项目的详细信息,包括匹配项目的文件及代码行,结合第三方开源项目声明的许可证,分析开源代码的引入是否会有兼容性和合规性等知识产权风险。
该技术基于相似哈希精准匹配等代码特征提取方法,对代码特征进行整合、计算后生成代码指纹信息,结合代码级大数据指纹库进行关联、匹配、分析。
2. 代码已知漏洞分析
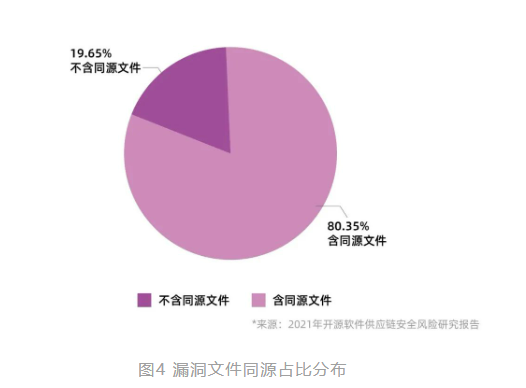
开发者在开发过程中引入的第三方开源代码,可能存在可被攻击者利用的已知漏洞。据调查显示,超 80% 的漏洞文件在开源项目内有同源文件,漏洞文件影响的范围在开源项目的传播下扩大了 54 倍,如图 4 所示。
通过同源检测技术识别出与当前代码同源的开源项目,结合漏洞库信息,可以检测当前代码是否来自有漏洞开源项目、当前代码是否来自开源项目有漏洞的版本、当前代码是否涉及漏洞相关的代码。
3. 恶意代码文件分析
目前,越来越多的安全事件是由于攻击者有意在开源社区提交恶意代码并发布更新,或在开源项目中添加恶意依赖,或滥用软件包管理器来分发恶意软件等新型攻击方式导致的。如 NPM 包中,eslint-scope 因黑客盗用开发者账号而发布包含恶意代码的版本、event-stream 因黑客混入项目维护者中然后在项目中添加恶意依赖等事件。因此,检测并识别源码中的恶意代码是满足 SCA 的一个必要功能。
SCA 是通过从源代码中提取敏感行为函数的特征数据,与提前收集的恶意代码特征数据进行比对来识别源代码中的恶意代码。
同源检测技术是 SCA 技术的重要基础,源鉴 SCA 具有纵深代码同源检测核心能力,可以精准识别应用开发过程中引用的第三方开源组件,通过应用组成分析引警多维度提取开源组件特征,计算组件指纹信息,深度挖掘组件中潜藏的各类安全漏洞及开源协议风险,全覆供应链安全审查、软件合规性审查、第三方组件安全管控等行业应用场景。
业务重塑:应用场景的跟踪与定位
1. 冗余代码检测
敏捷模式开发的应用,由于不同研发人员负责不同微服务应用开发,往往不自觉存在相同功能代码的实现。通过代码同源检测技术识别同类型的冗余代码,不仅可以便于消除和管理代码复用,对于后续维护提供遍历,也能够在出现代码缺陷时,方便进行统一修复,进一步确保代码质量。
例如,当不同的研发人员在开发各自应用程序时,涉及到对同样的功能进行反复编码实现。通过对代码进行相似性检测,可以把相似代码整合成为一个 SDK 包,除了可以统一维护,也可供给其他研发人员使用。
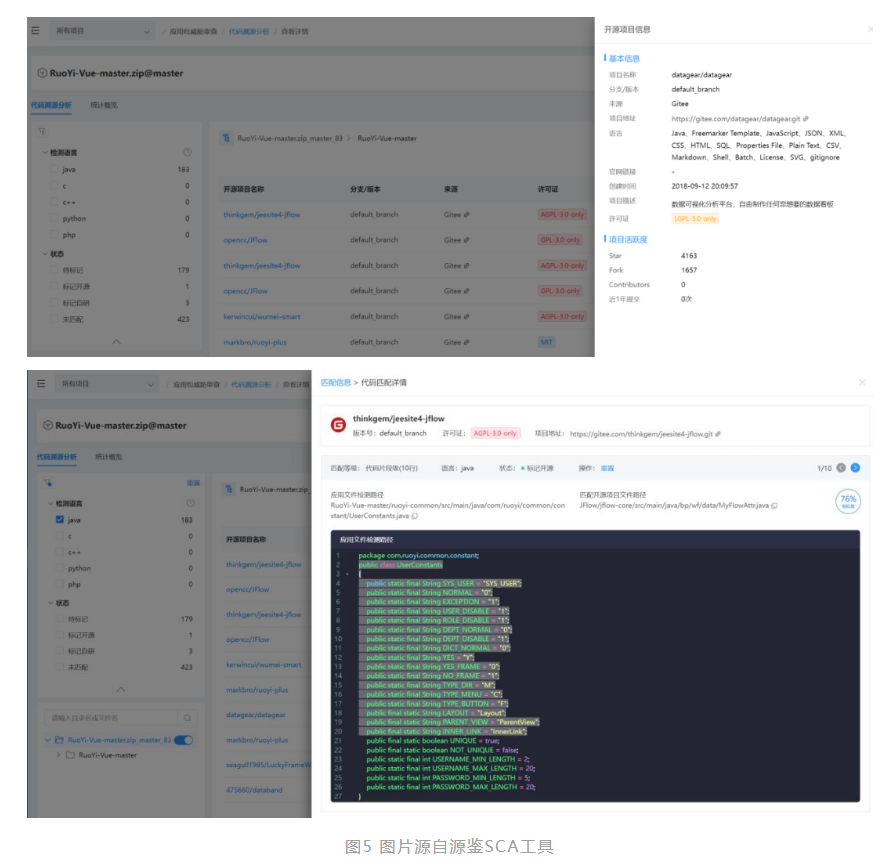
2. 片段代码风险检测
代码同源检测技术可以用于片段代码风险检测。片段代码风险检测主要是指在一个代码库或项目中,识别出具有潜在安全风险或漏洞的代码片段,以便进行修复或加强安全性。企业使用三方开源组件开发关键功能,往往不会直接使用,需根据业务需要对开源组件源代码进行二次开发。针对二次开发后的开源组件,常规的 SCA 工具难以识别其存在的风险,而代码同源检测技术可通过缺陷代码片段表征,对二次开发后的开源组件以及缺少版本特征的脚本型代码进行组件漏洞关联。
例如,常规的 SCA 技术对 jar 扩展名开源组件进行组件漏洞关联时,主要通过其版本号和组件指纹标识进行判断,二次开发后的开源组件,破坏了一部分指纹,可能导致无法识别。代码同源检测技术,可根据组件漏洞相关的风险代码片段,识别该类型组件是否存在对应组件漏洞风险。
通过代码同源检测技术进行片段代码风险检测,可以快速发现和修复潜在的安全问题,提高代码的安全性和可靠性。
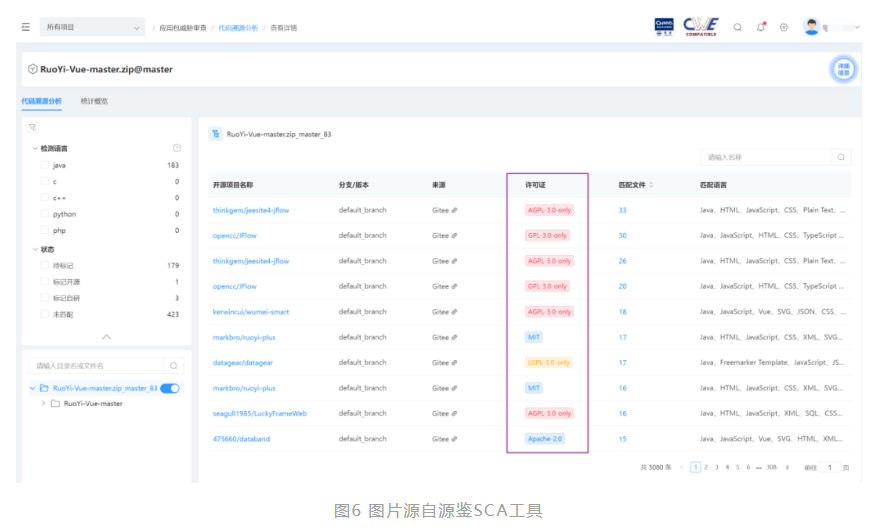
3. 代码知识侵权审核
开源组件并非自由组件,开源组件的使用需要严格遵守开源许可协议,在违背开源项目作者授权意愿的情况下使用其克隆代码,仍然会收到开源项目许可协议的约束。代码知识侵权指的是在编写软件时,抄袭或复制了其他人的代码或算法,侵犯了他人的知识产权。常见的代码知识侵权形式包括抄袭开源软件、复制其他人的代码、盗用算法等。企业对于自身商用软件,需要通过代码同源检测技术定期梳理检查开源组件代码使用情况,尤其是针对脚本型语言的使用,确保自身软件不存在开源许可协议风险。
例如,当初级研发人员在意识不足的情况下,使用了某些限制商业用途的开源代码的部分片段,从而导致应用存在了授权限制的风险,代码同源检测技术可以帮助识别这类型风险。代码同源检测技术可以用于识别代码知识侵权审核,帮助开发人员维护自己的知识产权,同时也可以避免侵犯他人的知识产权,提高代码的合法性和可信度。
4. 安全编码执行溯源
安全开发体系建设过程中,安全编码规范是提升编码质量的重要环节。对于标准安全编码的使用可通过代码同源检测技术进行审核,检查标准安全编码的应用情况,确保研发团队开发的应用具备基础的安全健壮性。
例如,在企业编制了标准的安全代码后,希望研发人员尽可能在开发过程中使用。代码同源检测技术可以帮助统计这部分标准代码的使用覆盖率,帮助后续推广。
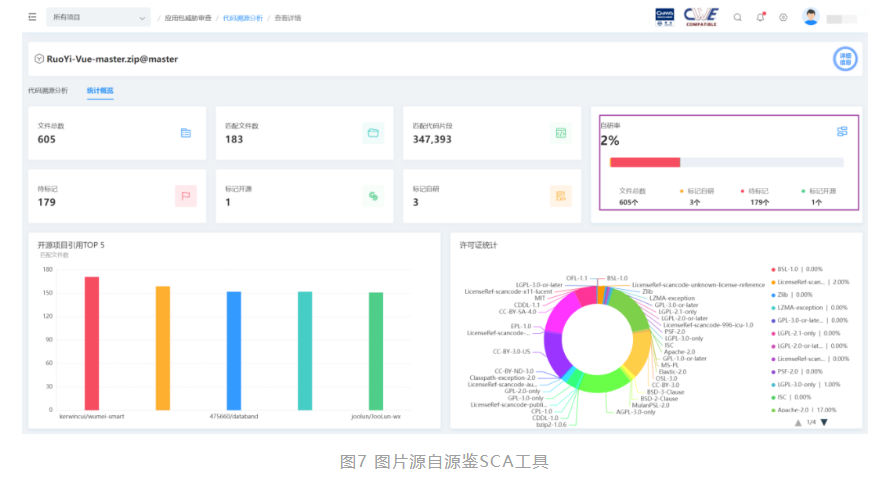
5. 代码自研率分析
在国家对企业软件自主可控的大环境要求下,软件源代码自研率分析将成为重要的参考指标,应用系统核心主干程序开发需要严格遵循自主可控原则。源代码同源检测,不仅能够展示代码片段是否可能存在安全风险,还能在企业接受外包或合作开发代码时,协助识别交付应用源码自研率,提高验收标准。
6.AI 生成代码检查
随着 ChatGPT 的应用,研发人员逐渐开始使用该技术自动生产可用代码。但由于 AI 本身收录样本学习的原因,其自动生产的代码可能存在部分代码克隆,并包含未遵守许可的风险。代码同源检测技术在代码生成时,能帮助增加安全风险审计能力。
实践应用:供应链安全治理
同源检测技术主要价值体现于帮助企业组织识别和清点开源软件的组件,并检测是否存在已知的代码漏洞或恶意代码,从文件级、代码片段级上帮助软件资产管理解决 “看不清” 和 “摸不透” 的主要痛点问题,帮助确保企业组织中供应链组件的安全性和可靠性。
源鉴 SCA 结合运用丰富的知识库样本、多种时间压缩的代码片段级检测算法等自身技术优势,最优化发挥同源检测技术特性,可做到以下功能特征:
1)基于丰富的知识库样本:知识库覆盖主流的代码托管平台 GitHub、GitLab、BitBucket、Gitee、Codeberg 等,覆盖的开源项目数超过 8KW+;
2)基于多种时间压缩的代码片段级检测算法:千万级的代码片段数据,只要秒级别,接近文件级的相似度检测时间;
3)精准定位:校验代码片段级算法的执行结果,能够清晰的定位到具体的开源项目地址、版本、文件路径名称和行号;
4)灵活的自适应:相似度阈值可调节,减少误报的概率。
源鉴 SCA 在满足实现源码级同源检测技术的基础上,结合二进制 SCA 技术、运行时 SCA 技术及组件漏洞热修复等技术,有效帮助开发人员更好地管理和维护软件成分,提高软件的安全性和可靠性,助力企业建立并有效落地数字供应链安全治理体系,保障数字供应链安全。
GitHub:
https://github.com/XmirrorSecurity/OpenSCA-cli/
Gitee:
https://gitee.com/XmirrorSecurity/OpenSCA-cli/
OpenSCA 官网:
https://opensca.xmirror.cn/
SCA 技术进阶系列(二):代码同源检测技术在供应链安全治理中的应用的更多相关文章
- Bing Maps进阶系列二:使用GeocodeService进行地理位置检索
Bing Maps进阶系列二:使用GeocodeService进行地理位置检索 在<Bing Maps进阶系列一:初识Bing Maps地图服务>里已经对GeocodeService的功能 ...
- Wireshark入门与进阶系列(二)
摘自http://blog.csdn.net/howeverpf/article/details/40743705 Wireshark入门与进阶系列(二) “君子生非异也,善假于物也”---荀子 本文 ...
- Spring Boot进阶系列二
上一篇文章,主要分析了怎么建立一个Restful web service,系列二主要创建一个H5静态页面使用ajax请求数据,功能主要有添加一本书,请求所有书并且按照Id降序排列,以及查看,删除一本书 ...
- 使用 PySide2 开发 Maya 插件系列二:继承 uic 转换出来的 py 文件中的类 Ui_Form
使用 PySide2 开发 Maya 插件系列二:继承 uic 转换出来的 py 文件中的类 Ui_Form 开发环境: Wing IDE 6.1 步骤1: 打开 Wing IDE,创建一个新的 pr ...
- 进阶系列二【绝对干货】---Quartz.Net的入门
一.Quartz.Net是什么? Quartz.Net是一个开源的作业调度框架,OpenSymphony的开源项目,是Quartz的C#移植项目.非常适合在平时的工作中,定时轮询数据库同步,定时邮件通 ...
- 前端进阶系列(二):css常见布局解决方案
水平居中布局 margin+定宽 <div class="parent"> <div class="child">Demo</di ...
- 深入探索Android热修复技术原理读书笔记 —— 代码热修复技术
在前一篇文章 深入探索Android热修复技术原理读书笔记 -- 热修复技术介绍中,对热修复技术进行了介绍,下面将详细介绍其中的代码修复技术. 1 底层热替换原理 在各种 Android 热修复方案中 ...
- Azure Event Hub 技术研究系列3-Event Hub接收事件
上篇博文中,我们通过编程的方式介绍了如何将事件消息发送到Azure Event Hub: Azure Event Hub 技术研究系列2-发送事件到Event Hub 本篇文章中,我们继续:从Even ...
- 服务端技术进阶(八)GitHub入门篇
服务端技术进阶(八)GitHub入门篇 前言 在投递简历的过程中,发现有的公司会要求填写自己的GitHub地址,而自己却还没有GitHub帐号,准确点说是自己还不太会使用GitHub.(貌似开源社区中 ...
- 学习ASP.NET Core Blazor编程系列二十一——数据刷新
学习ASP.NET Core Blazor编程系列文章之目录 学习ASP.NET Core Blazor编程系列一--综述 学习ASP.NET Core Blazor编程系列二--第一个Blazor应 ...
随机推荐
- 【译】拥抱 SQL Server 2022 与 SSDT 17.8:揭示关键更新
在数据库开发的动态场景中,SQL Server Data Tools(SSDT)是 Visual Studio 生态系统中数据库开发人员的强大工具.SSDT 17.8 包含在最新版本的 Visual ...
- jdk10的var局部变量类型推理
注:本人参考了openjdk官网,由于openjdk是开源的,所以不存在侵权行为,本章只为学习,我觉得没有什么比官网更具有话语权 1.jdk10的var的类型推测:就是这种处理将仅限于具有初始值设定项 ...
- Javascript Ajax总结——GET请求和POST请求
1.GET请求GET最常用于向服务器查询信息.可在URL末尾添加查询字符串参数.XHR中,传入open()方法的URL末尾的查询字符串必须经过正确的编码,使用encodeURIComponent()编 ...
- Ubuntu修改root可以远程ssh
默认情况下,Ubuntu系统不允许root远程登录,新建的系统root密码为随机密码,你不会知道首次ssh登录需要用自建用户远程登录,登录后提示如下: seafile@seafile:~$ 是以 ~ ...
- JPA复杂查询时间查询分页排序
JPA复杂查询时间查询分页排序 JPA复杂查询时间查询分页排序,工作上用到,因为项目是jpa,记录.代码囊括了:查询条件+时间范围+分页+排序 其实我也不太想用jpa,但是他也有优点,操作可以兼容多种 ...
- 使用NPOI导出Excel,并在Excel指定单元格插入图片
一.添加Nuget引用 二.弹框选择保存路径 string fileName = $"记录_{DateTime.Now.ToString("yyyyMMdd_HHmmss" ...
- JavaScript this 绑定详解
函数内 this 绑定 函数内this的绑定和函数定义的位置没有关系,和调用的方式和调用位置有关系,函数内的this是在被调用执行时被绑定的. this的具体绑定规则 this 绑定基本包含下面4种绑 ...
- react+echarts出现“There is a chart instance already initialized on the dom.”
写了一个关于echatrs组件,报错dom重复 配置信息从props拿 let chart; useEffect(() => { if (chart) { updateChartView(); ...
- 云小课|手把手教您在PyCharm中连接云端资源进行代码调试
摘要:让我们看看如何在PyCharm中连接云端资源进行代码调试吧! 本文分享自华为云社区<[云小课]EI第54课 手把手教您在PyCharm中连接云端资源进行代码调试>,作者:Hello ...
- 搞AI开发,你不得不会的PyCharm技术
摘要:PyCharm在AI项目开发提供了优秀的代码编辑.调试.远程连接和同步能力,在开发者中广受欢迎. 使用PyCharm插件配合ModelArts: 一键帮助用户配置远程ModelArts Note ...