Python爬虫实战系列2:虎嗅网24小时热门新闻采集
一、分析页面
打开虎嗅网,点击【24小时】
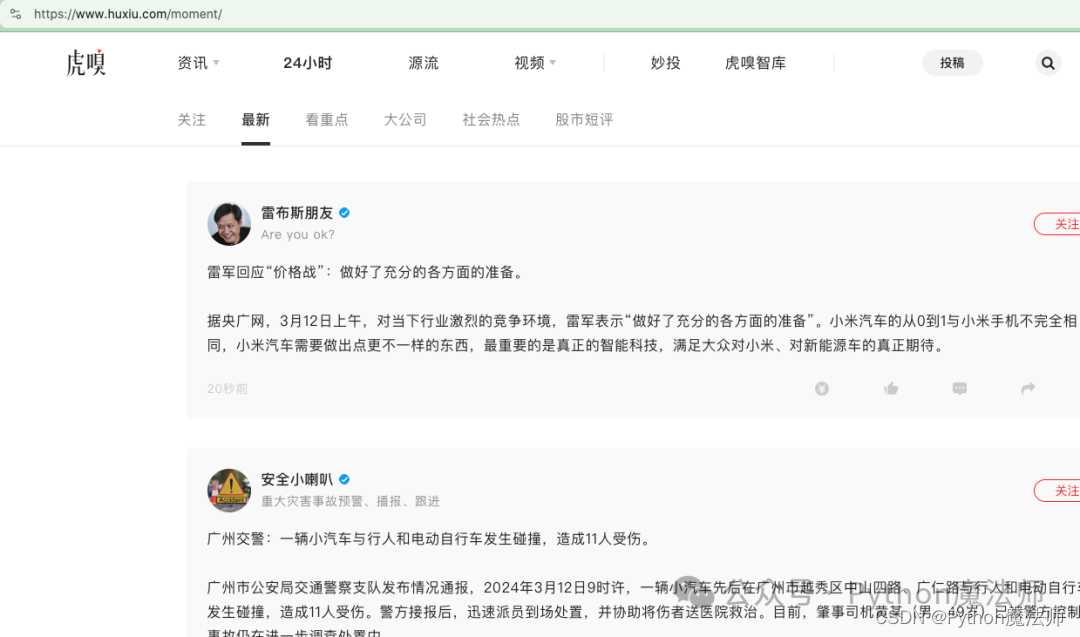
本次采集,我们以这24小时的热门新闻为案例。
1.1、分析请求
F12打开开发者模式,然后点击Network后点击任意一个请求,Ctrl+F开启搜索,输入标题雷军回应 ,开始搜索
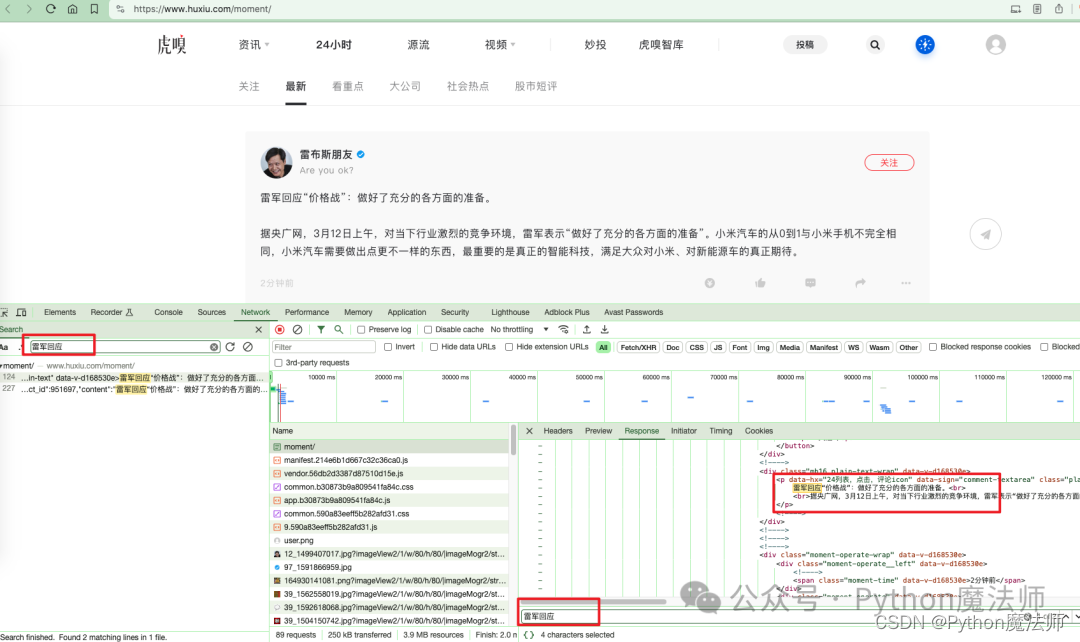
可以看到请求地址为https://www.huxiu.com/moment/ 但是返回的内容不是json格式,而是html源码,结合上次博客园采集经验我们需要解析html源码来获取数据,但是如果我们再细心一点,进一步搜索就会有惊喜。
通过直接在返回内容里搜索关键字,发现有一个js变量window.__INITIAL_STATE__; 存储了页面所需数据。
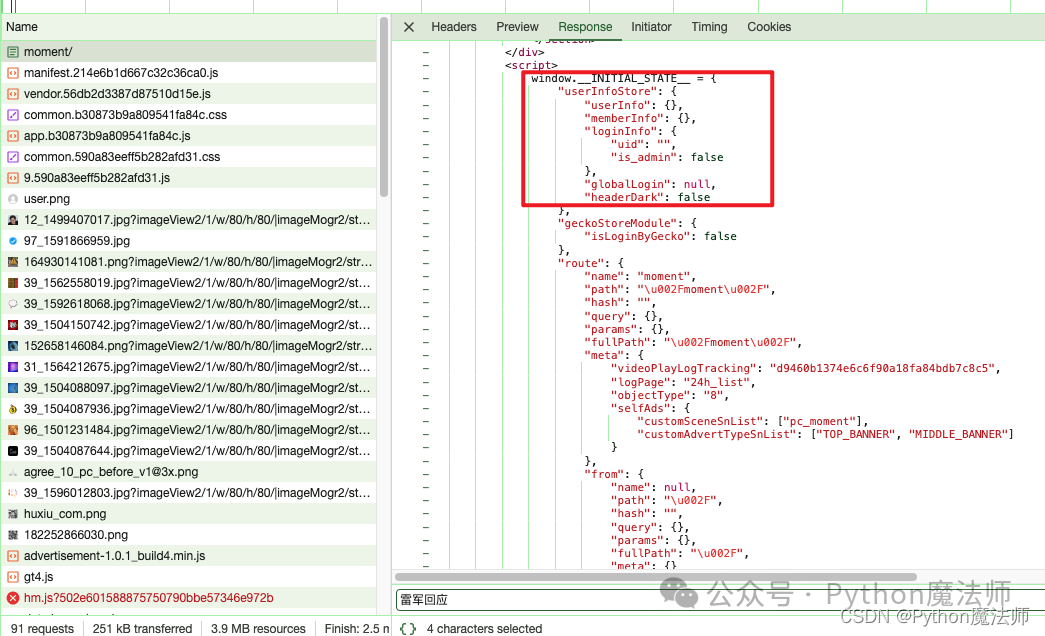
而这个变量里的['moment']['momentList']['moment_list']['datalist'][0]['datalist']内容则就是新闻具体数据
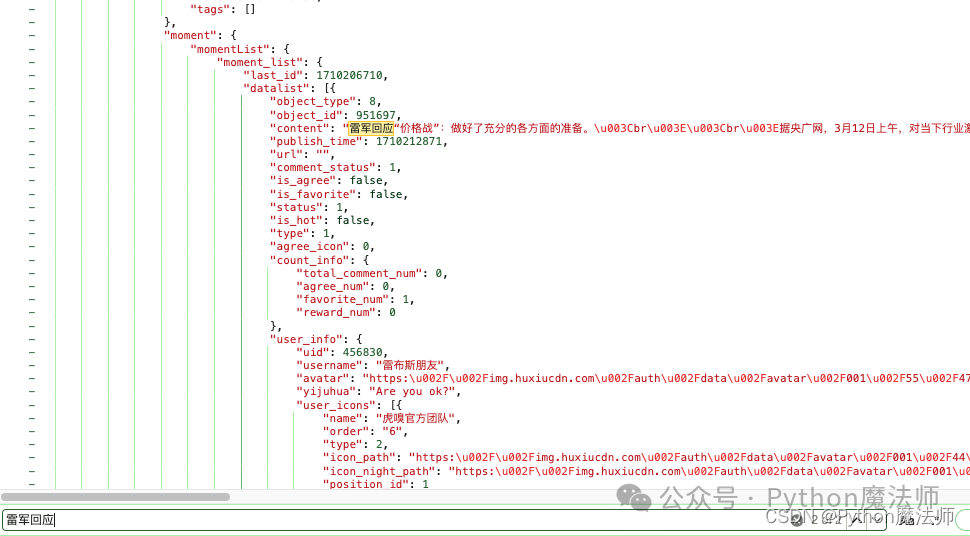
接下来就简单了,同样的套路,分析请求必需参数和cookie反爬策略,然后我们通过请求后获取js变量结果方式来进行爬取。
二、代码实现
本次技术实现使用如下库:
1.playwright:用来打开URL,执行JavaScript代码,获取js变量值
源码如下
# -*- coding: utf-8 -*-
import os
import sys
import time
from playwright.sync_api import sync_playwright
opd = os.path.dirname
curr_path = opd(os.path.realpath(__file__))
proj_path = opd(opd(opd(curr_path)))
sys.path.insert(0, proj_path)
# http请求默认agent
USERAGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
spider_config = {
"name_en": "https://www.huxiu.com/moment/",
"name_cn": "虎嗅"
}
def extract_title(text):
if text:
first_sentence = str(text).split('。')[0]
return first_sentence
else:
return text
class Huxiu:
def __init__(self):
self.headers = {
'authority': 'www.huxiu.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'user-agent': USERAGENT
}
def get_news(self):
results = []
with sync_playwright() as playwright:
browser = playwright.chromium.launch(
headless=True,
slow_mo=1000,
args=['--start-maximized']
)
context = browser.new_context(
no_viewport=True,
accept_downloads=True
)
page = context.new_page()
page.set_default_timeout(200000)
page.goto('https://www.huxiu.com/moment/')
page.wait_for_load_state('load')
# 获取动态JavaScript内容
initial_state = page.evaluate('(function() { return window.__INITIAL_STATE__; })()')
datalist = initial_state['moment']['momentList']['moment_list']['datalist'][0]['datalist']
for data in datalist:
results.append(
{
"news_title": extract_title(data['content']) + "。",
"news_date": data['format_time'],
"source_en": spider_config['name_en'],
"source_cn": spider_config['name_cn'],
}
)
browser.close()
return results
def main():
huxiu = Huxiu()
results = huxiu.get_news()
print(results)
if __name__ == '__main__':
main()
源码中核心内容:获取动态JavaScript内容
initial_state = page.evaluate('(function() { return window.__INITIAL_STATE__; })()')
总结
1.分析页面,有些页面请求返回的是html,但是也有可能会将数据拼接在js里来渲染页面
2.Python中执行JavaScript代码一种推荐的方式是使用playwright这种库,内置浏览器引擎,且很少被认为是暴力请求,并且自带等待机制
本文章代码只做学习交流使用,作者不负责任何由此引起的法律责任。
各位看官,如对你有帮助欢迎点赞,收藏,转发
关注公众号【Python魔法师】带你了解更多Python魔法

Python爬虫实战系列2:虎嗅网24小时热门新闻采集的更多相关文章
- Python爬虫实战(三):爬网易新闻
代码: # _*_ coding:utf-8 _*_ import urllib2 import re #import sys #reload(sys) #sys.setdefaultencoding ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- Python爬虫实战七之计算大学本学期绩点
大家好,本次为大家带来的项目是计算大学本学期绩点.首先说明的是,博主来自山东大学,有属于个人的学生成绩管理系统,需要学号密码才可以登录,不过可能广大读者没有这个学号密码,不能实际进行操作,所以最主要的 ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python爬虫实战三之实现山东大学无线网络掉线自动重连
综述 最近山大软件园校区QLSC_STU无线网掉线掉的厉害,连上之后平均十分钟左右掉线一次,很是让人心烦,还能不能愉快地上自习了?能忍吗?反正我是不能忍了,嗯,自己动手,丰衣足食!写个程序解决掉它! ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
随机推荐
- STM32 HAL库 USART DMA驱动
前言 本文是在使用 STM32L4 的串口 DMA 功能时,使用 HAL 库出现的一些问题,通过以下方式解决了 HAL 库中存在 DMA 发送和接收的一些问题. STM32L4 的 DMA 简介 DM ...
- Delphi Vista,Win7,Win8 的 Uac,管理员身份运行
要用就用下面我自己总结的官方的做法: 1.首先搜到delphi 自带的manifest,然后在其基础上改一个单词 2.将里面的asInvoker改为requireAdministrator 3.修改为 ...
- 移位寄存器的设计(VHDL)及testbench的编写
移位寄存器是一种常用的存储元件,此处由D触发器构成,如下图所示. 当时钟边沿到来时,存储在移位寄存器的数据朝一个方向移动一个BIT位. 移位寄存器的功能主要为:串并转换,并串转换和同步延迟. vhdl ...
- 一文看懂"async"和“await”关键词是如何简化了C#中多线程的开发过程
一文看懂"async"和"await"关键词是如何简化了C#中多线程的开发过程 当我们使用需要长时间运行的方法(即,用于读取大文件或从网络下载大量资源)时,在同 ...
- JS LeetCode 1423. 可获得的最大点数简单题解
壹 ❀ 引 最近也是浮躁的很,一篇redux的文章写了三千多字才算写了一半...写的泪目了.还是刷刷算法静下心,顺带记录下算法做题过程吧.今天的题来自LeetCode每日打卡,题目出自LeetCode ...
- NC20667 数学题
题目链接 题目 题目描述 最近,华东交通大学ACM训练基地的老阿姨被一个数学问题困扰了很久,她希望你能够帮她解决这个问题. 这个数学问题是这样的,给你一个N,要求你计算 gcd(a,b)表示a和b的最 ...
- RestTemplate的一些坑和改造点
一.RestTemplate怎么引入和使用 在pom.xml文件中加入如下dependency: <dependency> <groupId>org.springframewo ...
- win32 - 使用Desktop Duplication API复制桌面图像
该代码来源于codeproject,经过测试发现,在屏幕处于旋转的情况下捕获的图像是黑色的.暂时没有找到原因. 代码开箱即用, #define WIN32_LEAN_AND_MEAN #include ...
- win32--GetFileAttributes
DWORD d = GetFileAttributes(path.c_str()); 根据返回的十进制,对比文件属性,来检索指定文件或目录的文件系统属性. 也可以使用 if ((d & FIL ...
- 硬件开发笔记(十): 硬件开发基本流程,制作一个USB转RS232的模块(九):创建CH340G/MAX232封装库sop-16并关联原理图元器件
前言 有了原理图,可以设计硬件PCB,在设计PCB之间还有一个协同优先动作,就是映射封装,原理图库的元器件我们是自己设计的.为了更好的表述封装设计过程,本文描述了CH340G和MAX232芯片封装 ...