Elastic学习之旅 (2) 快速安装ELK
大家好,我是Edison。
上一篇:初识ElasticSearch
ElasticSearch的安装方式
ElasticSearch可以有多种安装方式,比如直接下载安装到宿主机进行运行,也可以通过docker的方式运行,完全取决我们的用途。这里,我们只是为了学习和练习,通过docker方式运行即可。
Docker安装的前置条件
这里为了成功通过docker安装ElasticSearch+Kibana,我们需要准备一下docker和docker-compose(如果你的实验机器没有安装的话):
安装docker:
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O
/etc/yum.repos.d/docker-ce.repo
yum -y install docker
systemctl enable docker && systemctl start docker
docker --version
安装docker-compose:
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O
/etc/yum.repos.d/docker-ce.repo
yum -y install docker
systemctl enable docker && systemctl start docker
docker --version
这里我们通过直接运行的方式(非Docker)运行Logstash,因此这里我们安装一下JDK:
yum install java-1.8.0-openjdk
java -version
修改系统参数(如果你的机器配置较低的话,比如只有2个G内存):
# 修改配置
sudo vim /etc/sysctl.conf
vm.max_map_count = 655360
# 让配置生效
sudo sysctl -p
Docker安装ElasticSearch+Kibana
这里我们以ES 7.1.0版本为例,虽然它是几年前的版本了,但这里我们只是学习完全够用了。
下面是我们准备好的docker-compose.yml文件:
version: '2.2'
services:
kibana:
image: docker.elastic.co/kibana/kibana:7.1.0
container_name: kibana7
environment:
- I18N_LOCALE=en-US
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED="true"
ports:
- "5601:5601"
networks:
- es7net elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_01
environment:
- cluster.name=edisontalk
- node.name=es7_01
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01,es7_02
- cluster.initial_master_nodes=es7_01,es7_02
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data1:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- es7net elasticsearch2:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_02
environment:
- cluster.name=edisontalk
- node.name=es7_02
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01,es7_02
- cluster.initial_master_nodes=es7_01,es7_02
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data2:/usr/share/elasticsearch/data
networks:
- es7net volumes:
es7data1:
driver: local
es7data2:
driver: local networks:
es7net:
driver: bridge
在这个文件中,定义了两个ES实例 和 一个Kibana实例,两个ES实例组成了一个小集群,Kibana则是可视化查询工具。
这里需要注意的是参数是“ES_JAVA_OPTS”,建议将Xmx 和 Xms 设置成一样的,如这里的512M。当然,如果你的机器配置较低,建议将这两个值调的低一些,比如256M。但是,Xmx的值不要超过机器内存的50%!
运行docker-compose文件执行运行安装:
docker-compose up -d
运行后等待1分钟,通过浏览器URL访问ES实例:
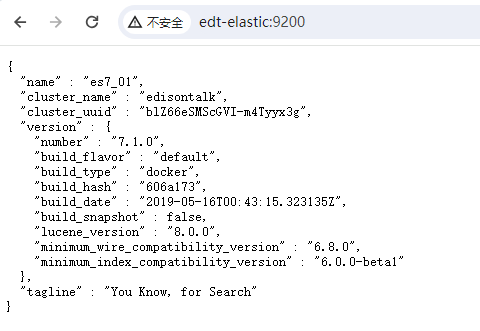
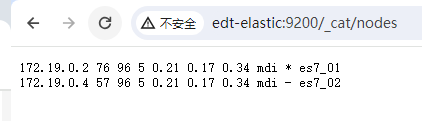
然后通过浏览器URL访问Kibana实例:
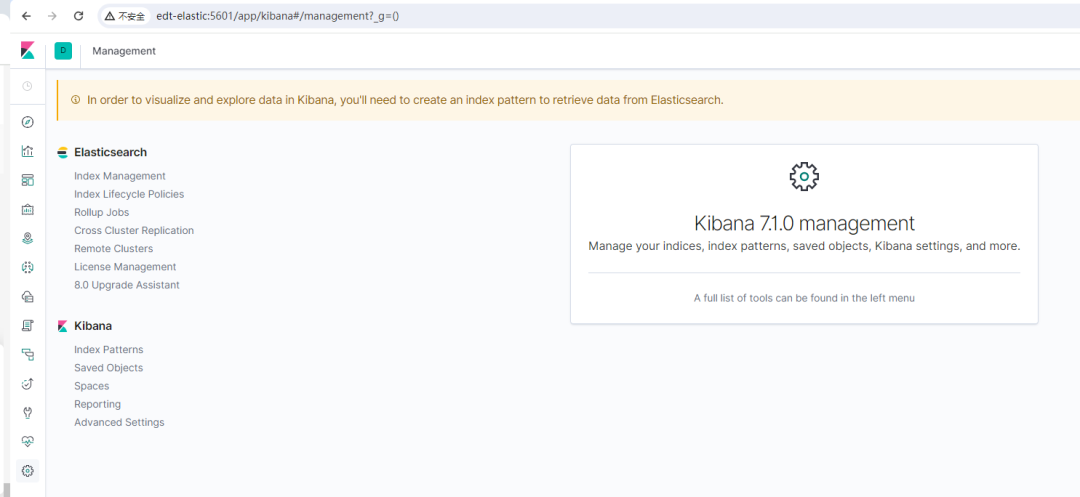
至此,你的ES+Kibana初步安装好了。
安装Logstash并导入测试数据集
这里我们再安装一个logstash,选择下载一个logstash-7.1.0安装到宿主机上的/usr/local/elastic/elk7目录下。
从这里下载logstash 7.1.0,与我们刚刚安装的ES实例保持一致:https://www.elastic.co/cn/downloads/past-releases/logstash-7-1-0
然后将其copy到你的服务器上,并进行解压:
然后准备一个logstash.conf配置文件,并copy到logstash-7.1.0/bin目录下:
input {
file {
path => "/usr/local/elastic/elk7/logstash-7.1.0/bin/movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{id}"
}
stdout {}
}
这个配置文件定义了我们需要采集的数据的路径,为了实现测试数据集的导入,我们也需要下载一个测试数据集,这里选择的是MovieLens的开放数据集,选择其small类型的movies测试数据,将这个movices.csv数据copy到logstash-7.1.0/bin目录下即可。
数据集地址:http://files.grouplens.org/datasets/movielens/ml-latest-small.zip
这个movie.csv中包含了一些电影的id和标题,以及该电影的类别,数据格式如下:
movieId, title, genres
最后,开始运行logstash:
sudo ./logstash -f logstash.conf
稍后,我们就可以看到一条条数据被传到了ElasticSearch中:
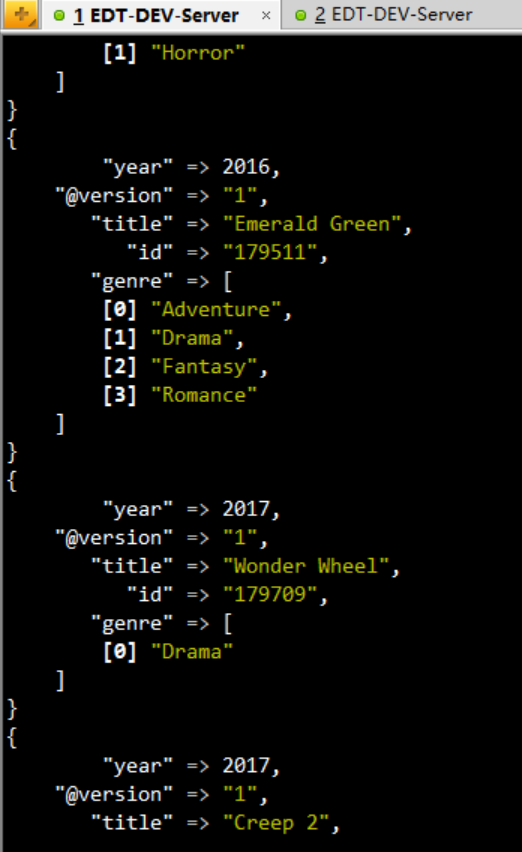
NOTE:logstash的执行比较慢,需要耐心等待一下,取决于你的测试服务器的配置了。
数据插入完成后,我们可以到Kibana的Dev Tools中验证一下:
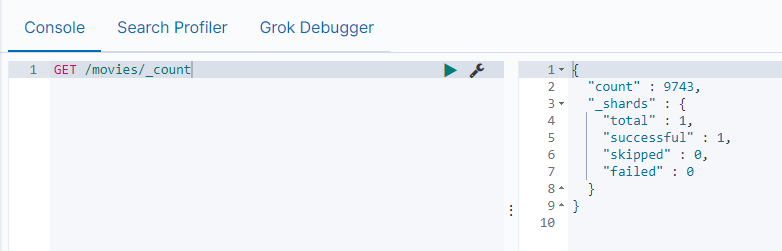
可以看到,共计9743个movie数据被传到了ElasticSearch中。
安装Cerebro可视化管理界面
Cerebro是一个常用的开源可视化管理工具,它可以对ElasticSearch进行集群监控和管理、集群配置修改、索引分片管理。
要安装Cerebro,只需要修改一下我们的docker-compose.yml,添加一个service即可:
version: '2.2'
services:
cerebro:
image: lmenezes/cerebro:0.8.3
container_name: cerebro
ports:
- "9000:9000"
command:
- -Dhosts.0.host=http://elasticsearch:9200
networks:
- es7net ......
然后重新执行以下命令即可安装:
docker-compose up -d
安装好后访问9000端口即可看到:
小结
本篇,我们了解了ElasticSearch的安装方式,并通过docker-compose的方式快速搭建了一个两个ES节点的ElasitcSearch + Kibana服务。然后,通过手动安装Logstash并导入测试数据集,为后续学习ElasticSearch基本概念和查询练习奠定了基础。
下一篇,我们就正式开始ElasticSearch的入门,先从一些常见的基本概念走起!
参考资料
极客时间,阮一鸣,《ElasticSearch核心技术与实战》

Elastic学习之旅 (2) 快速安装ELK的更多相关文章
- 谷歌Cartographer学习(1)-快速安装测试(转载)
转载自谷歌Cartographer学习(1)-快速安装测试 代码放到个人github上,https://github.com/hitcm/ 如下,需要安装3个软件包,ceres solver.cart ...
- 谷歌Cartographer学习(1)-快速安装测试
谷歌自己提供了安装方法,但是安装比较繁琐,我做了一定的修改,代码放到个人github上,https://github.com/hitcm/. ros下面的安装非常快捷,只需要catkin_make即可 ...
- Docker 快速安装&搭建 Ngnix 环境,并配置反向代理
欢迎关注个人微信公众号: 小哈学Java, 文末分享阿里 P8 高级架构师吐血总结的 <Java 核心知识整理&面试.pdf>资源链接!! 个人网站: https://www.ex ...
- Docker 快速安装&搭建 Mysql 环境
欢迎关注个人微信公众号: 小哈学Java, 文末分享阿里 P8 高级架构师吐血总结的 <Java 核心知识整理&面试.pdf>资源链接!! 个人网站: https://www.ex ...
- Docker 快速安装&搭建 MongDB 环境
欢迎关注个人微信公众号: 小哈学Java, 文末分享阿里 P8 高级架构师吐血总结的 <Java 核心知识整理&面试.pdf>资源链接!! 个人网站: https://www.ex ...
- 虚拟机创建及安装ELK
虚拟机创建及安装ELK 作者:高波 归档:学习笔记 2018年5月31日 13:57:02 快捷键: Ctrl + 1 标题1 Ctrl + 2 标题2 Ctrl + 3 标题3 C ...
- 180分钟的python学习之旅
最近在很多地方都可以看到Python的身影,尤其在人工智能等科学领域,其丰富的科学计算等方面类库无比强大.很多身边的哥们也提到Python非常的简洁方便,比如用Django搭建一个见得网站只需要半天时 ...
- 快速认识ELK中的L - Logstash
快速认识ELK中的L - Logstash 原创 2016-12-07 杜亦舒 简介 Logstash 是一个开源的数据采集引擎. Logstash 就像是一个管子,左面接数据源接收数据,右面接存储目 ...
- CentOS 7.x安装ELK(Elasticsearch+Logstash+Kibana)
第一次听到ELK,是新浪的@ARGV 介绍内部使用ELK的情况和场景,当时触动很大,原来有那么方便的方式来收集日志和展现,有了这样的工具,你干完坏事,删除日志,就已经没啥作用了. 很多企业都表示出他们 ...
- ELK技术实战-安装Elk 5.x平台
ELK技术实战–了解Elk各组件 转载 http://www.ywnds.com/?p=9776 ELK技术实战-部署Elk 2.x平台 ELK Stack是软件集合Elasticsearch. ...
随机推荐
- 组合式api的使用方式
方式一:通过setup选项 <script> export default { setup(){ // 提供数据 // 提供函数 // 提供计算属性等等..... } } </scr ...
- Javascript Ajax总结——其他跨域技术之Comet
Comet指一种更高级的Ajax技术( 也称 "服务器推送" ),一种服务器向页面推送数据的技术.Comet能够让信息近乎实时地被推送到页面上,非常适合体育比赛的分数和股票报价.有 ...
- 在Windows操作系统中,使用powershell脚本批量删除、批量替换文件名
比如我们下载的mp3文件或者小说.评书里都带很多作者.网站等信息,如何批量一键删除掉多余的字段呢? 下面举例:批量删除文件名称 可以看到原文中,所有文件名中均包含"小番茄与火龙果-" ...
- JVM优化:如何进行JVM调优,JVM调优参数有哪些
Java虚拟机(JVM)是Java应用运行的核心环境.JVM的性能优化对于提高应用性能.减少资源消耗和提升系统稳定性至关重要.本文将深入探讨JVM的调优方法和相关参数,以帮助开发者和系统管理员有效地优 ...
- VSCode 终端选择文本自动复制
Ctrl + , 打开设置 搜索 copyOnSelection,勾选即可 对应的 settings.json 如下 "terminal.integrated.copyOnSelection ...
- 浅学GoF23种设计模式
long long ago 买了设计模式的书,一直没看,平常工作虽然涉及到,但是不够系统,工作之余抽空学习一下. 一.创建型模式 01.单例(Singleton) 02.工厂方法(Factory Me ...
- 案例展示自定义C函数的实现过程
摘要:用户在使用数据库过程中,受限于内置函数的功能,部分业务不易实现时,可以使用自定义C函数实现特殊功能.本文通过两个示例展示自定义C函数的实现过程. 前言 用户在使用数据库过程中,常常受限于内置函数 ...
- 看MindSpore加持下,如何「炼出」首个千亿参数中文预训练语言模型?
摘要:千亿参数量的中文大规模预训练语言模型时代到来. 本文分享自华为云社区< MindSpore开源框架加持,如何「炼出」首个千亿参数.TB级内存的中文预训练语言模型?>,原文作者:che ...
- 【“互联网+”大赛华为云赛道】API命题攻略:厘清三步解题思路,用好开发工具
摘要:结合华为云API开放平台API Exploer实现照片分类系统. API能为我们带来什么? 有了 API,可以创建管理云服务器.云容器.云硬盘,提高工作效率:可以接入图像识别.情感分析.内容审核 ...
- XEngine:深度学习模型推理优化
摘要:从显存优化,计算优化两个方面来分析一下如何进行深度学习模型推理优化. 本文分享自华为云社区<XEngine-深度学习推理优化>,作者: ross.xw. 前言 深度学习模型的开发周期 ...