MindSpore中使用model.train,在每一步训练结束后自动进行调用自定义函数 —— from mindspore.train.callback import Callback
在MindSpore中使用model.train训练网络时我们难以处理间断性的任务,为此我们可以考虑使用MindSpore中的Callback机制。
Callback 函数可以在 model.train 的每一步(step)训练结束后进行自定义的操作。
Callback 函数:
from mindspore.train.callback import Callback
在官方文档中一般使用 Callback 函数来记录每一步的loss 或 在一定训练步数后进行算法评估:
官网地址:
https://www.mindspore.cn/tutorial/training/zh-CN/r1.2/quick_start/quick_start.html
具体使用的代码:
参考:https://www.cnblogs.com/devilmaycry812839668/p/14971668.html


import matplotlib.pyplot as plt
import matplotlib
import numpy as np
import os import mindspore.nn as nn
from mindspore.nn import Accuracy
from mindspore.nn import SoftmaxCrossEntropyWithLogits
from mindspore import dtype as mstype
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as CV
import mindspore.dataset.transforms.c_transforms as C
from mindspore.dataset.vision import Inter
from mindspore.common.initializer import Normal
from mindspore import Tensor, Model
from mindspore.train.callback import Callback
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor def create_dataset(data_path, batch_size=32, repeat_size=1,
num_parallel_workers=1):
"""
create dataset for train or test Args:
data_path (str): Data path
batch_size (int): The number of data records in each group
repeat_size (int): The number of replicated data records
num_parallel_workers (int): The number of parallel workers
"""
# define dataset
mnist_ds = ds.MnistDataset(data_path) # define some parameters needed for data enhancement and rough justification
resize_height, resize_width = 32, 32
rescale = 1.0 / 255.0
shift = 0.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081 # according to the parameters, generate the corresponding data enhancement method
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)
rescale_nml_op = CV.Rescale(rescale_nml, shift_nml)
rescale_op = CV.Rescale(rescale, shift)
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.int32) # using map to apply operations to a dataset
mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers) # process the generated dataset
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
mnist_ds = mnist_ds.repeat(repeat_size) return mnist_ds class LeNet5(nn.Cell):
"""Lenet network structure."""
# define the operator required
def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02))
self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02))
self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02))
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten() # use the preceding operators to construct networks
def construct(self, x):
x = self.max_pool2d(self.relu(self.conv1(x)))
x = self.max_pool2d(self.relu(self.conv2(x)))
x = self.flatten(x)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x # custom callback function
class StepLossAccInfo(Callback):
def __init__(self, model, eval_dataset, steps_loss, steps_eval):
self.model = model
self.eval_dataset = eval_dataset
self.steps_loss = steps_loss
self.steps_eval = steps_eval
self.steps = 0 def step_end(self, run_context):
cb_params = run_context.original_args()
cur_epoch = cb_params.cur_epoch_num
#cur_step = (cur_epoch-1)*1875 + cb_params.cur_step_num
self.steps = self.steps+1
cur_step = self.steps self.steps_loss["loss_value"].append(str(cb_params.net_outputs))
self.steps_loss["step"].append(str(cur_step))
if cur_step % 125 == 0:
acc = self.model.eval(self.eval_dataset, dataset_sink_mode=False)
self.steps_eval["step"].append(cur_step)
self.steps_eval["acc"].append(acc["Accuracy"]) def train_model(_model, _epoch_size, _repeat_size, _mnist_path, _model_path):
ds_train = create_dataset(os.path.join(_mnist_path, "train"), 32, _repeat_size)
eval_dataset = create_dataset(os.path.join(_mnist_path, "test"), 32) # save the network model and parameters for subsequence fine-tuning
config_ck = CheckpointConfig(save_checkpoint_steps=375, keep_checkpoint_max=16)
# group layers into an object with training and evaluation features
ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", directory=_model_path, config=config_ck) steps_loss = {"step": [], "loss_value": []}
steps_eval = {"step": [], "acc": []}
# collect the steps,loss and accuracy information
step_loss_acc_info = StepLossAccInfo(_model, eval_dataset, steps_loss, steps_eval) model.train(_epoch_size, ds_train, callbacks=[ckpoint_cb, LossMonitor(125), step_loss_acc_info], dataset_sink_mode=False) return steps_loss, steps_eval epoch_size = 1
repeat_size = 1
mnist_path = "./datasets/MNIST_Data"
model_path = "./models/ckpt/mindspore_quick_start/" # clean up old run files before in Linux
os.system('rm -f {0}*.ckpt {0}*.meta {0}*.pb'.format(model_path)) lr = 0.01
momentum = 0.9 # create the network
network = LeNet5() # define the optimizer
net_opt = nn.Momentum(network.trainable_params(), lr, momentum) # define the loss function
net_loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean') # define the model
model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()}) steps_loss, steps_eval = train_model(model, epoch_size, repeat_size, mnist_path, model_path) print(steps_loss, steps_eval)
运行结果:
核心代码:
from mindspore.train.callback import Callback # custom callback function
class StepLossAccInfo(Callback):
def __init__(self, model, eval_dataset, steps_loss, steps_eval):
self.model = model
self.eval_dataset = eval_dataset
self.steps_loss = steps_loss
self.steps_eval = steps_eval
self.steps = 0 def step_end(self, run_context):
cb_params = run_context.original_args()
cur_epoch = cb_params.cur_epoch_num
#cur_step = (cur_epoch-1)*1875 + cb_params.cur_step_num
self.steps = self.steps+1
cur_step = self.steps self.steps_loss["loss_value"].append(str(cb_params.net_outputs))
self.steps_loss["step"].append(str(cur_step))
if cur_step % 125 == 0:
acc = self.model.eval(self.eval_dataset, dataset_sink_mode=False)
self.steps_eval["step"].append(cur_step)
self.steps_eval["acc"].append(acc["Accuracy"])
可以看到,继承 Callback 类后我们可以自己定义新的功能类,只要我们实现 step_end 方法即可。
默认传入给 step_end 方法的参数 run_context 可以通过以下方法获得当前刚结束的step数和当前的epoch数:
cb_params = run_context.original_args()
cur_epoch = cb_params.cur_epoch_num
cur_step = (cur_epoch-1)*1875 + cb_params.cur_step_num
其中,cb_params.cur_epoch_num 为当前的epoch数,
cb_params.cur_step_num 为在当前epoch中的当前步数,
需要注意的是,cb_params.cur_step_num 步数不是总共的计算步数,而是在当前epoch中的计算步数。
当前step训练中的损失值也是可以获得的,具体如下:
cb_params.net_outputs 代表当前step的损失值
=========================================================
上述代码,引入绘图功能的代码:
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
import os import mindspore.nn as nn
from mindspore.nn import Accuracy
from mindspore.nn import SoftmaxCrossEntropyWithLogits
from mindspore import dtype as mstype
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as CV
import mindspore.dataset.transforms.c_transforms as C
from mindspore.dataset.vision import Inter
from mindspore.common.initializer import Normal
from mindspore import Tensor, Model
from mindspore.train.callback import Callback
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor def create_dataset(data_path, batch_size=32, repeat_size=1,
num_parallel_workers=1):
"""
create dataset for train or test Args:
data_path (str): Data path
batch_size (int): The number of data records in each group
repeat_size (int): The number of replicated data records
num_parallel_workers (int): The number of parallel workers
"""
# define dataset
mnist_ds = ds.MnistDataset(data_path) # define some parameters needed for data enhancement and rough justification
resize_height, resize_width = 32, 32
rescale = 1.0 / 255.0
shift = 0.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081 # according to the parameters, generate the corresponding data enhancement method
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)
rescale_nml_op = CV.Rescale(rescale_nml, shift_nml)
rescale_op = CV.Rescale(rescale, shift)
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.int32) # using map to apply operations to a dataset
mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers) # process the generated dataset
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
mnist_ds = mnist_ds.repeat(repeat_size) return mnist_ds class LeNet5(nn.Cell):
"""Lenet network structure."""
# define the operator required
def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02))
self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02))
self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02))
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten() # use the preceding operators to construct networks
def construct(self, x):
x = self.max_pool2d(self.relu(self.conv1(x)))
x = self.max_pool2d(self.relu(self.conv2(x)))
x = self.flatten(x)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x # custom callback function
class StepLossAccInfo(Callback):
def __init__(self, model, eval_dataset, steps_loss, steps_eval):
self.model = model
self.eval_dataset = eval_dataset
self.steps_loss = steps_loss
self.steps_eval = steps_eval
self.steps = 0 def step_end(self, run_context):
cb_params = run_context.original_args()
cur_epoch = cb_params.cur_epoch_num
#cur_step = (cur_epoch-1)*1875 + cb_params.cur_step_num
self.steps = self.steps+1
cur_step = self.steps self.steps_loss["loss_value"].append(str(cb_params.net_outputs))
self.steps_loss["step"].append(str(cur_step))
if cur_step % 125 == 0:
acc = self.model.eval(self.eval_dataset, dataset_sink_mode=False)
self.steps_eval["step"].append(cur_step)
self.steps_eval["acc"].append(acc["Accuracy"]) def train_model(_model, _epoch_size, _repeat_size, _mnist_path, _model_path):
ds_train = create_dataset(os.path.join(_mnist_path, "train"), 32, _repeat_size)
eval_dataset = create_dataset(os.path.join(_mnist_path, "test"), 32) # save the network model and parameters for subsequence fine-tuning
config_ck = CheckpointConfig(save_checkpoint_steps=375, keep_checkpoint_max=16)
# group layers into an object with training and evaluation features
ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", directory=_model_path, config=config_ck) steps_loss = {"step": [], "loss_value": []}
steps_eval = {"step": [], "acc": []}
# collect the steps,loss and accuracy information
step_loss_acc_info = StepLossAccInfo(_model, eval_dataset, steps_loss, steps_eval) model.train(_epoch_size, ds_train, callbacks=[ckpoint_cb, LossMonitor(125), step_loss_acc_info], dataset_sink_mode=True) return steps_loss, steps_eval epoch_size = 1
repeat_size = 1
mnist_path = "./datasets/MNIST_Data"
model_path = "./models/ckpt/mindspore_quick_start/" # clean up old run files before in Linux
os.system('rm -f {0}*.ckpt {0}*.meta {0}*.pb'.format(model_path)) lr = 0.01
momentum = 0.9 # create the network
network = LeNet5() # define the optimizer
net_opt = nn.Momentum(network.trainable_params(), lr, momentum) # define the loss function
net_loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean') # define the model
model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()}) steps_loss, steps_eval = train_model(model, epoch_size, repeat_size, mnist_path, model_path) steps = steps_loss["step"]
loss_value = steps_loss["loss_value"]
steps = list(map(int, steps))
loss_value = list(map(float, loss_value))
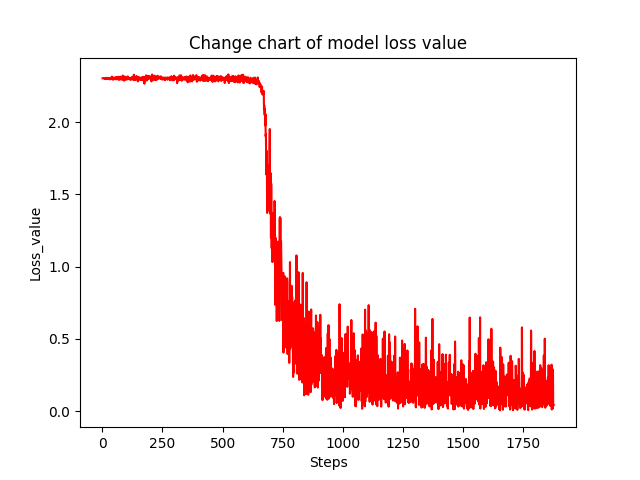
plt.plot(steps, loss_value, color="red")
plt.xlabel("Steps")
plt.ylabel("Loss_value")
plt.title("Change chart of model loss value")
plt.show() def eval_show(steps_eval):
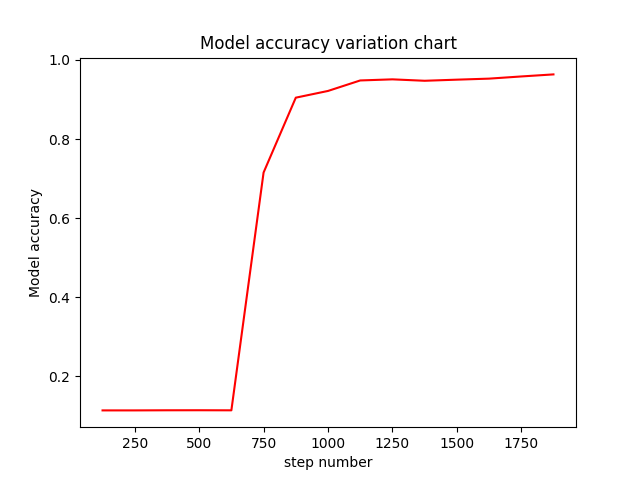
plt.xlabel("step number")
plt.ylabel("Model accuracy")
plt.title("Model accuracy variation chart")
plt.plot(steps_eval["step"], steps_eval["acc"], "red")
plt.show() eval_show(steps_eval)
MindSpore中使用model.train,在每一步训练结束后自动进行调用自定义函数 —— from mindspore.train.callback import Callback的更多相关文章
- 如何在sqlite3连接中创建并调用自定义函数
#!/user/bin/env python # @Time :2018/6/8 14:44 # @Author :PGIDYSQ #@File :CreateFunTest.py '''如何在sql ...
- PHP中call user func()和call_user_func_array()调用自定义函数小结
call_user_func() 和 call_user_func_array(),通过传入字符串函数,可以调用自定义函数,并且支持引用,都允许用户调用自定义函数并传入一定的参数: 1.mixed c ...
- 微信小程序wxml文件中调用自定义函数
想在微信小程序的wxml文件里自如的像vue那样调用自定义的方法,发现并不成功,得利用WXS脚本语言. WXS脚本语言是 WeiXin Script 脚本语言的简称,是JavaScript.JSON. ...
- C#中WebService 的 Timer定时器过段时间后自动停止运行
我用.net做的一个Timer定时器,定时获取短信并给予回复,但大概过了十几个小时以后,Timer定时器会自动停止,再发送短信就不能收到回复,需要在服务器中重新运行定时器才可以,请教各位! 我是在.n ...
- ionic1项目中 ion-slide轮播用ng-repeat遍历数据后自动循环出问题
<ion-slide-box>属性中循环播放:dose-continue=‘true’,但是在项目遇到这样一个问题,从后台获取数据后将数据ng-repeat到<ion-slide&g ...
- Problem D: 调用自定义函数search(int list[], int n),在数组中查找某个数
AC代码#include <stdio.h> int find(int *a, int l, int x) { ; int i; ; i < l; i ++) if(a[i] == ...
- Mysql5.7创建存储过程中调用自定义函数报错Not allowed to return a result set from a function
因为很多存储过程都会共用一段sql语句,所以我把共用的sql封装成一个自定义函数 AddCapital(); 然后通过存储过程调用,创建存储过程会报错1415,Not allowed to retur ...
- Entity Framework 6 Recipes 2nd Edition(10-5)译 -> 在存储模型中使用自定义函数
10-5. 在存储模型中使用自定义函数 问题 想在模型中使用自定义函数,而不是存储过程. 解决方案 假设我们数据库里有成员(members)和他们已经发送的信息(messages) 关系数据表,如Fi ...
- 在SQL中使用自定义函数
由于数据库的一个表字段中多包含html标签,现在需要修改数据库的字段把html标签都替换掉.当然我可以通过写一个程序去修改,那毕竟有点麻烦.直接在查询分析器中执行,但是MS SQL Server并 ...
- 【转载】 Sqlserver中查看自定义函数被哪些对象引用
Sqlserver数据库中支持自定义函数,包含表值函数和标量值函数,表值函数一般返回多个数据行即数据集,而标量值函数一般返回一个值,在数据库的存储过程中可调用自定义函数,也可在该自定义函数中调用另一个 ...
随机推荐
- cerebro安装部署,es客户端优化界面
1.下载地址 https://github.com/lmenezes/cerebro/releases 2.下载cerebro-0.9.3.zip 运行bin/cerebro ,启动没有报错,并且命令 ...
- SQLBI_精通DAX课程笔记_01_DAX介绍
一:函数式语言 DAX是一个函数式语言,应用于Analysis Services , PowerPivot , 和Power Bi . 二:共同与不同 2.1 共同点 DAX与PowerPivot ...
- HTML元素如何按字符串原格式输出文本换行制表符信息
只需给相应HTML元素添加 style="white-space: pre"
- 超越datetime:Arrow,Python中的日期时间管理大师
介绍 Arrow是一个Python库,它提供了一种合理且对人类友好的方法来创建.操作.格式化和转换日期.时间和时间戳.它实现了对datetime类型的更新,填补了功能上的空白,提供了一个智能的模块AP ...
- 04-Python文件操作
打开文件 f=open("我的文件.txt","r",encoding="utf8") #打开一个文件(读模式) f.close() #关闭 ...
- LuBase 低代码开发框架介绍 - 可私有化部署
框架定位 面向开发人员,针对管理软件领域,对页面交互和通用功能进行高阶封装,逐步打造成平台型.生态型开发工具. 涓涓细流 ,汇聚成海,基于 PBC(组件式开发)开发理念,让功能模块的复用更简单. 让管 ...
- Tutorial: How to install GNU MCU Eclipse?
Overview For more flexibility and upgradeability, GNU MCU Eclipse is not packed as a all-inclusive s ...
- yb课堂 下单页面组件开发 《四十三》
Pay.vue <template> <!--视频信息--> <div> <div class="info"> <p clas ...
- Spring的IOC容器类别概述
Spring的IOC该如何理解呢? 平常在一个方法当中,若要用到外部另一个类里的非静态方法,首先,需要先通过new一个对象,再根据这个对象去调用其方法.若只需要一两个对象还好,一旦涉及的外部对象多了, ...
- yolov5+deepsort+slowfast复现
1.运行环境 ubuntu 18.04.1 Cuda 11.5 Python 3.8.15 torch 1.10.1+cu113 torchvision 0.11.2+cu113 2.安装PyTorc ...