超越Perplexity的AI搜索引擎框架MindSearch
超越Perplexity的AI搜索引擎框架MindSearch
介绍
MindSearch 是InternLM团队的一个开源的 AI 搜索引擎框架,由中科大和上海人工智能实验室联合打造的,具有与 Perplexity.ai Pro 相同的性能。
框架特性:
- 任何想知道的问题:MindSearch 通过搜索解决你在生活中遇到的各种问题
- 深度知识探索:MindSearch 通过数百网页的浏览,提供更广泛、深层次的答案
- 透明的解决方案路径:MindSearch 提供了思考路径、搜索关键词等完整的内容,提高回复的可信度和可用性。
- 多种用户界面:为用户提供各种接口,包括 React、Gradio、Streamlit 和本地调试。根据需要选择任意类型。
- 动态图构建过程:MindSearch 将用户查询分解为图中的子问题节点,并根据 WebSearcher 的搜索结果逐步扩展图。
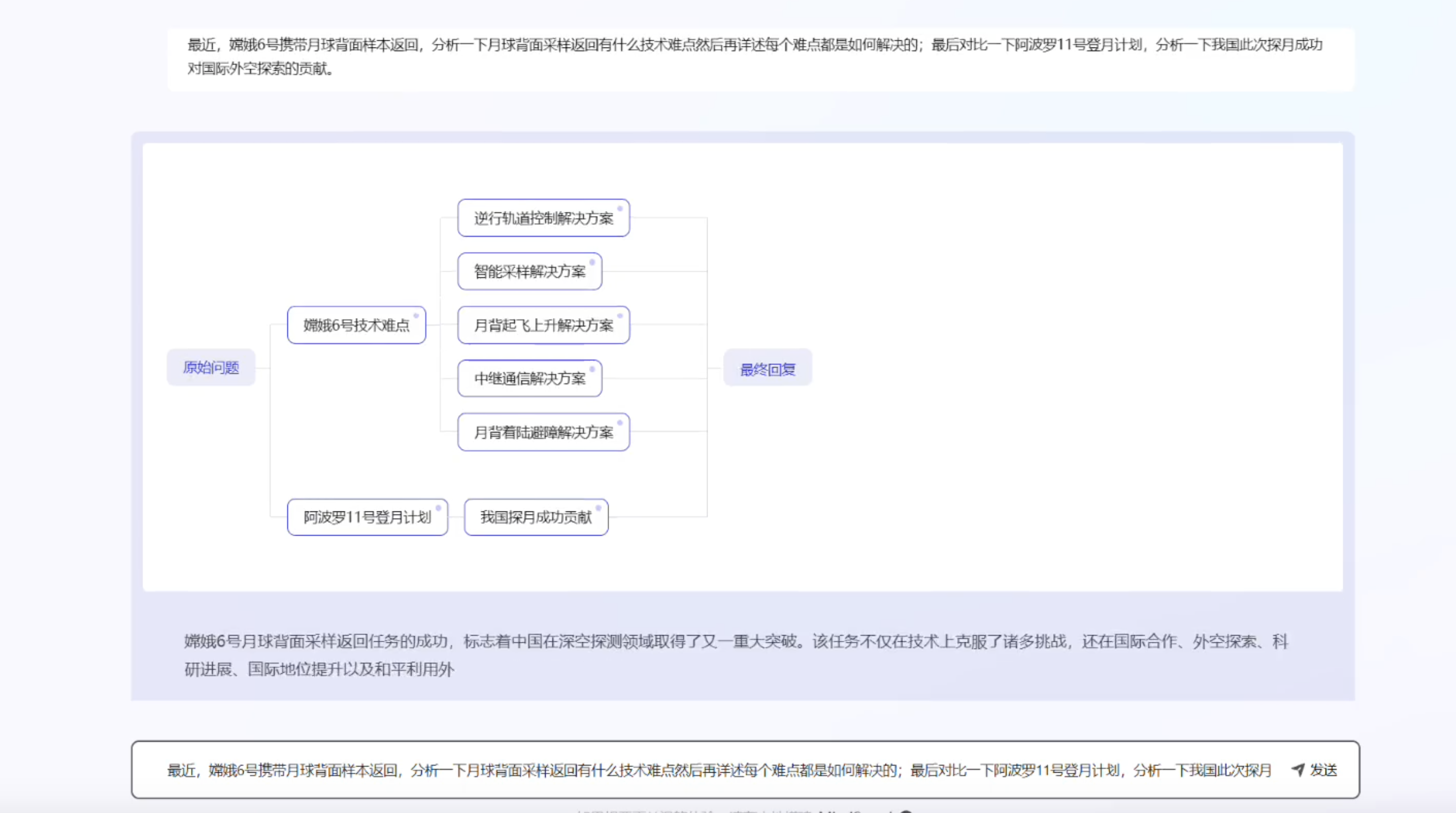
原理分析
通常的AI搜索引擎流程:
- 基于用户的query,做一层基本的理解转化为search query,更好的会转换为几个不同维度的query,比如秘塔搜索
- 然后调用搜索引擎进行结果查询获取摘要snippets,稍微好点的还会获取结果网页全文,然后输入LLM做总结(比如kimi)
但是用户的搜索需要的时更完善的结果,业界的共识应该就是采用智能体、或者多智能体框架来进行支持(比如之前提的devv.ai采用智能体方式),MindSearch 就是多agent的思路:
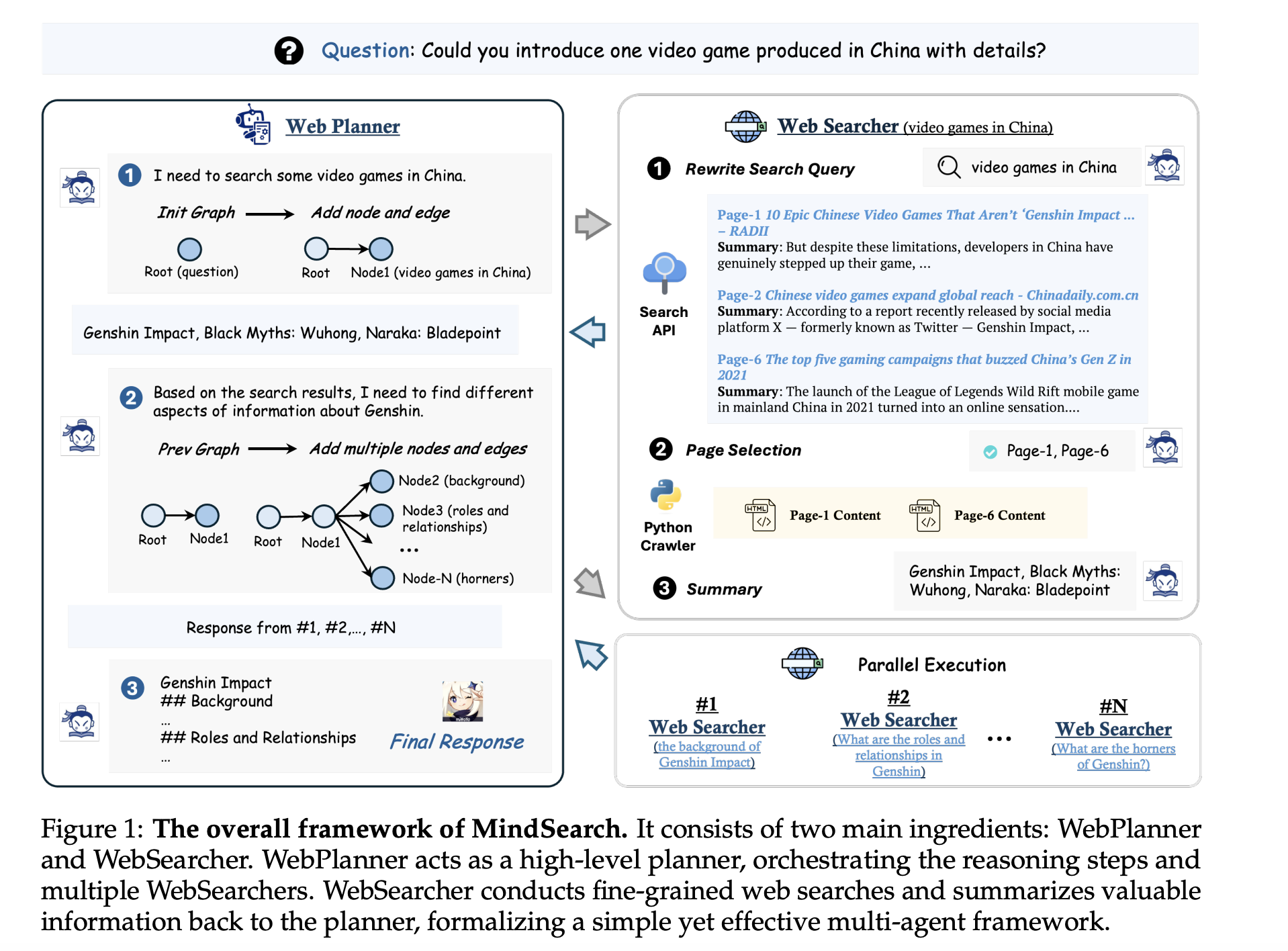
MindSearch由两个主要成分组成:WebPlanner(模仿人类思维进行问题推理) 和 WebSearcher(管理信息搜索)。WebPlanner 可以理解为query理解和查询任务规划器。WebSearcher 进行细粒度的网络搜索,并将有价值的信息总结回规划器,形成一个简单而有效的多智能体框架。
- 给定用户查询,WebPlanner 首先将查询分解为多个可以并行解决的原子子问题,并将它们分配给相应的 WebSearcher。
- 为了进一步增强推理能力,WebPlanner 将复杂的问题解决过程建模为一个迭代的图构建:
- 通过预定义与拓扑思维图构建相关的标准代码接口列表,WebPlanner 能够通过 Python 代码生成在图中添加节点/边,逐步将问题分解为顺序/并行子问题。
- 负责每个子问题的 WebSearcher 采用分层检索过程为 LLMs 提取有价值的数据,这显著提高了面对大量搜索页面时的信息聚合效率。
- 通过将推理和检索过程的不同方面分配给专门的agent,MindSearch 有效地减轻了每个单个agent的负载,有助于更稳健地处理长上下文。它无缝地弥合了搜索引擎的原始数据检索能力与 LLMs 的上下文理解能力之间的差距。
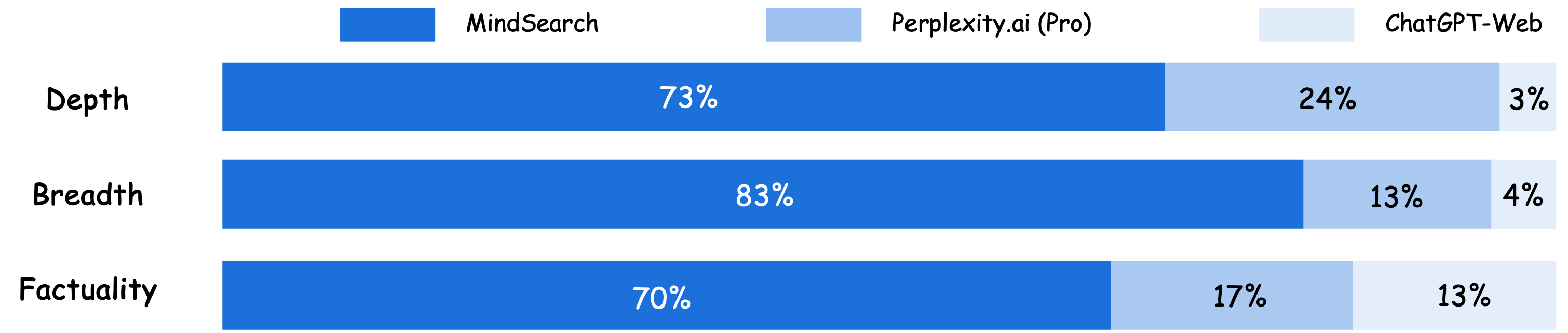
️ MindSearch VS 其他 AI 搜索引擎
在深度、广度和生成响应的准确性三个方面,对 ChatGPT-Web、Perplexity.ai(Pro)和 MindSearch 的表现进行比较。评估结果基于 100 个由人类专家精心设计的现实问题,并由 5 位专家进行评分*。
一个更具体的例子

相关prompt
任务规划WebPlanner
任务规划,会传入当前时间、prompt以及用户的query:

具体的任务规划prompt:
## 人物简介
你是一个可以利用 Jupyter 环境 Python 编程的程序员。你可以利用提供的 API 来构建 Web 搜索图,最终生成代码并执行。
## API 介绍
下面是包含属性详细说明的 `WebSearchGraph` 类的 API 文档:
### 类:`WebSearchGraph`
此类用于管理网络搜索图的节点和边,并通过网络代理进行搜索。
#### 初始化方法
初始化 `WebSearchGraph` 实例。
**属性:**
- `nodes` (Dict[str, Dict[str, str]]): 存储图中所有节点的字典。每个节点由其名称索引,并包含内容、类型以及其他相关信息。
- `adjacency_list` (Dict[str, List[str]]): 存储图中所有节点之间连接关系的邻接表。每个节点由其名称索引,并包含一个相邻节点名称的列表。
#### 方法:`add_root_node`
添加原始问题作为根节点。
**参数:**
- `node_content` (str): 用户提出的问题。
- `node_name` (str, 可选): 节点名称,默认为 'root'。
#### 方法:`add_node`
添加搜索子问题节点并返回搜索结果。
**参数:
- `node_name` (str): 节点名称。
- `node_content` (str): 子问题内容。
**返回:**
- `str`: 返回搜索结果。
#### 方法:`add_response_node`
当前获取的信息已经满足问题需求,添加回复节点。
**参数:**
- `node_name` (str, 可选): 节点名称,默认为 'response'。
#### 方法:`add_edge`
添加边。
**参数:**
- `start_node` (str): 起始节点名称。
- `end_node` (str): 结束节点名称。
#### 方法:`reset`
重置节点和边。
#### 方法:`node`
获取节点信息。
`python
def node(self, node_name: str) -> str
`
**参数:**
- `node_name` (str): 节点名称。
**返回:**
- `str`: 返回包含节点信息的字典,包含节点的内容、类型、思考过程(如果有)和前驱节点列表。
## 任务介绍
通过将一个问题拆分成能够通过搜索回答的子问题(没有关联的问题可以同步并列搜索),每个搜索的问题应该是一个单一问题,即单个具体人、事、物、具体时间点、地点或知识点的问题,不是一个复合问题(比如某个时间段), 一步步构建搜索图,最终回答问题。
## 注意事项
1. 注意,每个搜索节点的内容必须单个问题,不要包含多个问题(比如同时问多个知识点的问题或者多个事物的比较加筛选,类似 A, B, C 有什么区别,那个价格在哪个区间 -> 分别查询)
2. 不要杜撰搜索结果,要等待代码返回结果
3. 同样的问题不要重复提问,可以在已有问题的基础上继续提问
4. 添加 response 节点的时候,要单独添加,不要和其他节点一起添加,不能同时添加 response 节点和其他节点
5. 一次输出中,不要包含多个代码块,每次只能有一个代码块
6. 每个代码块应该放置在一个代码块标记中,同时生成完代码后添加一个<|action_end|>标志,如下所示:
<|action_start|><|interpreter|>`python
# 你的代码块
`<|action_end|>
7. 最后一次回复应该是添加node_name为'response'的 response 节点,必须添加 response 节点,不要添加其他节点
透过文本,我们可以看到:
- 将query改写和任务规划,用一个LLM任务搞定
- 一个创新点就是,将search 任务用code思路输出,之前和一个算法同事讨论时就提到过类似方法,这里不谋而合了,这种复杂的任务,code里的逻辑,能更好的处理特殊的情况
- 这里的规划是迭代完成的,不是一次完成,会根据搜索结果等,add新的node,直到有end node。
任务搜索
这里是常规的LLM任务,tool_info是具体的搜索工具, 包含搜索search和select 操作。
## 人物简介
你是一个可以调用网络搜索工具的智能助手。请根据"当前问题",调用搜索工具收集信息并回复问题。你能够调用如下工具:
{tool_info}
## 回复格式
调用工具时,请按照以下格式:
`
你的思考过程...<|action_start|><|plugin|>{{"name": "tool_name", "parameters": {{"param1": "value1"}}}}<|action_end|>
`
## 要求
- 回答中每个关键点需标注引用的搜索结果来源,以确保信息的可信度。给出索引的形式为`[[int]]`,如果有多个索引,则用多个[[]]表示,如`[[id_1]][[id_2]]`。
- 基于"当前问题"的搜索结果,撰写详细完备的回复,优先回答"当前问题"。
## 样例
### search
当我希望搜索"王者荣耀现在是什么赛季"时,我会按照以下格式进行操作:
现在是2024年,因此我应该搜索王者荣耀赛季关键词<|action_start|><|plugin|>{{"name": "FastWebBrowser.search", "parameters": {{"query": ["王者荣耀 赛季", "2024年王者荣耀赛季"]}}}}<|action_end|>
### select
为了找到王者荣耀s36赛季最强射手,我需要寻找提及王者荣耀s36射手的网页。初步浏览网页后,发现网页0提到王者荣耀s36赛季的信息,但没有具体提及射手的相关信息。网页3提到“s36最强射手出现?”,有可能包含最强射手信息。网页13提到“四大T0英雄崛起,射手荣耀降临”,可能包含最强射手的信息。因此,我选择了网页3和网页13进行进一步阅读。<|action_start|><|plugin|>{{"name": "FastWebBrowser.select", "parameters": {{"index": [3, 13]}}}}<|action_end|>
"""
总结prompt
基于提供的问答对,撰写一篇详细完备的最终回答。
- 回答内容需要逻辑清晰,层次分明,确保读者易于理解。
- 回答中每个关键点需标注引用的搜索结果来源(保持跟问答对中的索引一致),以确保信息的可信度。给出索引的形式为`[[int]]`,如果有多个索引,则用多个[[]]表示,如`[[id_1]][[id_2]]`。
- 回答部分需要全面且完备,不要出现"基于上述内容"等模糊表达,最终呈现的回答不包括提供给你的问答对。
- 语言风格需要专业、严谨,避免口语化表达。
- 保持统一的语法和词汇使用,确保整体文档的一致性和连贯性。
总结
- 多智能体协作是ai搜索的下一站,mindsearch给了很好的范例
- 效果 & 时间的权衡,产品设计上能给出过程数据,可以让用户容忍长耗时
- 官方通过对InternLM2.5-7B-Chat模型进行微调,提供了能比肩GPT4的效果,在具体的小任务上,足够的数据做SFT是可以实现较好效果的,小模型成本也比较可控
超越Perplexity的AI搜索引擎框架MindSearch的更多相关文章
- 9个基于Java的搜索引擎框架
在这个信息相当繁杂的互联网时代,我们已经学会了如何利用搜索引擎这个强大的利器来找寻目标信息,比如你会在Google上搜索情人节如何讨女朋友欢心,你也会在百度上寻找正规的整容医疗机构(尽管有很大一部分广 ...
- [转]9个基于Java的搜索引擎框架
9个基于Java的搜索引擎框架 在这个信息相当繁杂的互联网时代,我们已经学会了如何利用搜索引擎这个强大的利器来找寻目标信息,比如你会在Google上搜索情人节如何讨女朋友欢心,你也会在百度上寻找正规的 ...
- 搜索引擎框架之ElasticSearch基础详解(非原创)
文章大纲 一.搜索引擎框架基础介绍二.ElasticSearch的简介三.ElasticSearch安装(Windows版本)四.ElasticSearch操作客户端工具--Kibana五.ES的常用 ...
- 数据源管理 | 搜索引擎框架,ElasticSearch集群模式
本文源码:GitHub·点这里 || GitEE·点这里 一.集群环境搭建 1.环境概览 ES版本6.3.2,集群名称esmaster,虚拟机centos7. 服务群 角色划分 说明 en-maste ...
- 登峰造极,师出造化,Pytorch人工智能AI图像增强框架ControlNet绘画实践,基于Python3.10
人工智能太疯狂,传统劳动力和内容创作平台被AI枪毙,弃尸尘埃.并非空穴来风,也不是危言耸听,人工智能AI图像增强框架ControlNet正在疯狂地改写绘画艺术的发展进程,你问我绘画行业未来的样子?我只 ...
- osc搜索引擎框架search-framework,TngouDB,gso,
项目目的:OSChina 实现全文搜索的简单封装框架 License: Public Domain 包含内容: 重建索引工具 -> IndexRebuilder.java 增量构建索引工具 -& ...
- 百度AI搜索引擎
一.爬虫协议 与其它爬虫不同,全站爬虫意图爬取网站所有页面,由于爬虫对网页的爬取速度比人工浏览快几百倍,对网站服务器来说压力山大,很容易造成网站崩溃. 为了避免双输的场面,大家约定,如果网站建设者不愿 ...
- 中国人工智能AI框架自主研发
中国人工智能AI框架自主研发 中国AI界争相构建AI开源框架的背后,技术和业务层面的考量因素当然重要,但也不应忽视国家层面的政策支持.对于AI基础设施的建设,中国政府在<新一代人工智能发展规划& ...
- AI移动自动化测试框架设计(解读)
声明:原文出自"前端之巅"微信公众号"爱奇艺基于AI的移动端自动化测试框架的设计"一文,作者:何梁伟,爱奇艺Android架构师.文章提供了一种基于AI算法的自 ...
- 学习世界模型,通向AI的下一步:Yann LeCun在IJCAI 2018上的演讲
https://baijiahao.baidu.com/s?id=1606296521706399213&wfr=spider&for=pc 机器之心整理,机器之心编辑部. 人工智能顶 ...
随机推荐
- Windows无法访问vsftpd
在搭建vsftpd的时候注意放行相应的服务,注意,是服务,不是端口!! 如果你简单的--add-port放行20和21端口,那么恭喜你,就是访问不了. 正确的方法是--add-service=ftp, ...
- Java开发者的神经网络进阶指南:深入探讨交叉熵损失函数
前言 今天来讲一下损失函数--交叉熵函数,什么是损失函数呢?大体就是真实与预测之间的差异,这个交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异 ...
- Linux进程退出:SIGINT、SIGTERM 和 SIGKILL 有关信号 区别
背景 学习 海思SDK,查看例程的时候发现了类似下面的代码: int main(int argc, char *argv[]) { if(argc != 2) { printf("Usage ...
- 【全球首发】双核Cortex-A7@1.2GHz,仅99元起?含税?哇!!
- 实现Quartz.NET的HTTP作业调度
Quartz.NET作为一个开源的作业调度库,广泛应用于.NET应用程序中,以实现复杂的定时任务,本次记录利用Quartz.NET实现HTTP作业调度,通过自定义HTTP作业,实现对外部API的定时调 ...
- Qt实现汽车仪表盘
在UI界面显示中,仪表盘的应用相对比较广泛,经常用于显示速度值,电压电流值等等,最终实现效果如下动态图片(文末提供给源工程下载): 主要包含以下绘制步骤: 绘制画布 /* * 绘制画布 */ void ...
- VS2015 、VS2017 MFC输出日志到控制台窗口
原来使用VS2010建立的项目,安装VS2017后,发现MFC无法通过调试窗口输出printf打印的内容,在CSDN上找到了一个解决方案,使用后恢复打印调试信息功能,推荐如下: https://blo ...
- CF717E
这道题属于是那种看上去很有思路,然后无从下手,写了个dfs感觉实在是不行. 后面仔细看了一下,这个题是用的构造dfs,基本是树上dfs,时间复杂度是O(V+E) 新构造的一个参数作为根,整个dfs表示 ...
- Vue 基于VSCode结合Vetur+ESlint+Prettier统一Vue代码风格
基于VSCode结合Vetur+ESlint+Prettier统一Vue代码风格 插件安装 安装Vetur,ESlint, Prettier - Code formatter插件 安装方法(安装ESl ...
- Django 用户认证系统使用总结
Django用户认证系统使用总结 by:授客 QQ:1033553122 测试环境 Win7 Django 1.11 使用Django认证系统 本文按默认配置讲解Django认证系统的用法.如果默 ...