[转帖]计算机体系结构-cache高速缓存
https://zhuanlan.zhihu.com/p/482651908
本文主要介绍了cache的基本常识、基本组成方式、写入方法和替换策略,在基本组成方式和替换策略两节给出了较为详细的硬件实现方法,并不流于空泛,并且补充了SRAM和三态门等与硬件实现息息相关的知识。更高阶的cache优化方法和cache设计实例会在将来更新。
1、Cache概论
1.1、cache与多层次存储结构
理想情况下,我们肯定希望拥有无限大的内存容量,这样就可以立刻访问任何一个特定的机器字,但我们不得不认识到有可能需要构建分层结构的存储器,每一层次容量都要大于前一层次,但其访问速度也要更慢一些。
一些计算机先驱准确地预测到程序员肯定会希望拥有无限数量的快速存储器。
影响现代处理器性能的两个至关重要的部件是分支预测器和cache(快速缓存),cache参与构成现代处理器的多层次存储结构(参考下图,CPU寄存器--L1 cache--L2--L3--主存--磁盘等大容量存储器),是除寄存器外最靠近CPU核的存储单元,通常由SRAM组成(SRAM的补充知识见2.4节)。
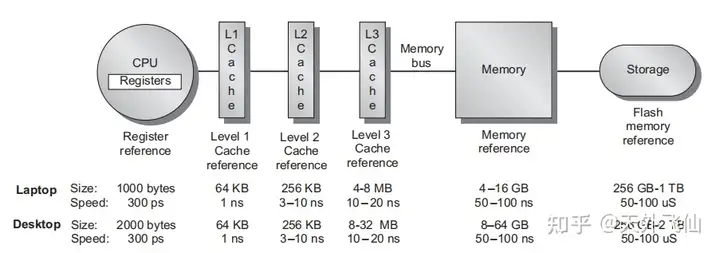
存储器层次结构和容量、读写速度
1.2、引入cache的目的
计算机在运行程序时首先将程序从磁盘读取到主存,然后CPU按规则从主存中取出指令、数据并执行指令,但是直接从主存(一般用DRAM制成)中读写是很慢的,所以我们引入了cache。
在执行程序前,首先会试图把要用到的指令、数据从主存移到cache中,然后在执行程序时直接访问cache。如果指令、数据在cache中,那么我们能很快地读取出来,这称为“命中(hit)”;如果指令、数据不在cache中,我们仍旧要从主存中拿指令、数据,这称为“不命中(miss)”。命中率对于cache而言是很重要的。
现代处理器一般有三层cache,分别称为L1 cache、L2 cache、L3 cache。L1 cache离CPU核最近,存储信息的读取速度接近CPU核的工作速度,容量较小,一般分成I-cache和D-cache两块,分别存储指令和数据;L2 cache比L1更远,速度慢一些,但是容量更大,不分I-cache和D-cache;L3更慢、更大,现在流行多核处理器,L3一般由多个处理器核共享,而L1、L2是单核私有的。
实际上cache是一个广义的概念,可以认为主存是磁盘的cache,而CPU内cache又是主存的cache,使用cache的目的就是伪造出一个容量有低层次存储器(如磁盘)那么大,而速度又有寄存器(如通用寄存器)那么快的存储器,简单来说就要让存储单元看起来又大又快。
1.3、cache的理论基础
cache之所以能work,主要基于两个认识,即程序运行时数据具有时间局部性和空间局部性。
时间局部性是指一个数据如果当前被使用到,那么接下去一段时间它很可能被再次用到;空间局部性是指一个数据如果当前被使用到,那么接下去一段时间它周围的数据很可能也会被用到,比如数组。
2、Cache的组成方式
cache容量较小,所以数据需要按照一定的规则从主存映射到cache。一般把主存和cache分割成一定大小的块,这个块在主存中称为data block,在cache中称为cache line。举个例子,块大小为1024个字节,那么data block和cache line都是1024个字节。当把主存和cache分割好之后,我们就可以把data block放到cache line中,而这个“放”的规则一般有三种,分别是“直接映射”、“组相联”和“全相联”。
2.1、直接映射
直接映射采用“取模”的方式进行一对一映射。举个例子,如果cache中共有8个cache line,那么0、8、16、24...号data block会被映射到0号cache line中,同理1、9、17....号data block会被映射到1号cache line中,具体可以参考下面的关系图。

直接映射中的主存-cache对应关系
注意到上图中的cache除了数据之外还有“标记”位,“标记”可以显示出当前的cache line对应的是主存中的哪一组data block。举个例子,0、8、16.....号data block都可能存入0号cache line,此时标记位可以显示0号cache line到底是哪个data block。
再具体一点,直接映射中cache line一般有三个组成部分,分别是有效位V,标志位Tag,和数据位Data block。实现的电路结构如下。

直接映射电路实现
CPU送来的地址按高低位被分成三部分,tag、index和offset。index用来指定选中哪一个cache line,tag用来与cache line的tag作比较以生成hit信号,而offset则从选择的cache line中选中部分数据进行输出。
要注意的是,index会首先经过一个译码器,译码器生成一段独热码,独热码只会选中SRAM中的某一行,所以在读取data的时候只有对应的cache line会被读出,其他cache不会被读出。
2.2、组相联
直接映射中主存中的每一个data block都有一个确定的cache line进行映射,这是有缺陷的。当程序连续读取0、8、0、8号data block的数据时,因为只有一个cache line供映射,所以当第二次读取0号block时,第一次读到cache中的0号block早被顶替出去了,这时候又会产生miss,miss会极大地影响执行效率。
为了解决上面的问题,提出使用“组相联”的方式。组相联的主存-cache对应关系见下图。

组相联中的主存-cache对应关系
根据上图我们很容易发现比起直接映射,组相联翻倍了block可以映射的cache line的数量,图上数量为2,我们称每两个cache line为一个cache set。组相联的实现电路如下。
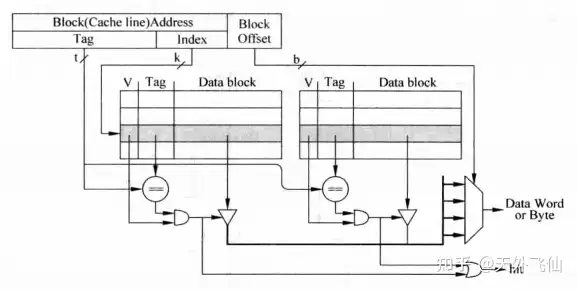
组相联电路实现
实现电路和直接映射很相似,不同的地方在于直接映射中index只选出一个cache line,而这里选出了两个cache line。两组data根据tag的比较结果来输入到选择器,实现方式是令两组data直接通过三态门连到一组数据线上。不熟悉这个操作的朋友可以先查阅2.5节内容。
在真实场景中组相联cache的tag和data往往被分开存储,因为分开存储,组相联实现电路分化成了并行和串行实现方式。
下图是并行实现方式。index同时送到tag ram和data ram,同时译码,同时读取tag和data,并根据tag比较的结果来选择一组data进行输出,aligner是字节选择器。这里关键的地方在于我们看起来就像把cache set中的两路cache line横向拼接起来,然后根据index的译码结果选中某一行,这一行包含两个cache line中data。
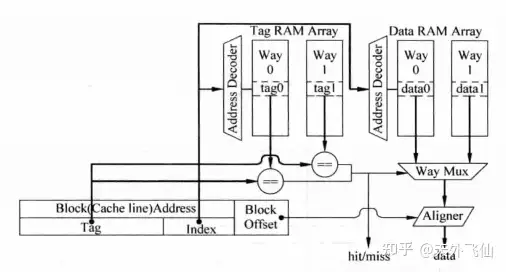
并行实现组相联
下图是串行实现方式。相比于并行,这里的关键地方是我们把两路cache line纵向拼接了,这样cache line的数量翻倍,通过tag比较和index译码的综合结果,我们最终只会选中一个cache line,选中的cache line中的数据直接送往aligner。这样的工作过程有明显的串行特征,即首先tag比较,然后才选中某一cache line。
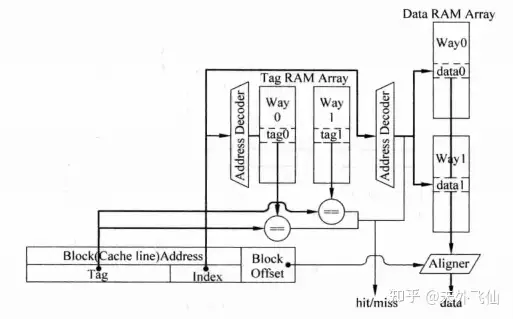
串行实现组相联
比较串行和并行实现,并行实现因为比串行多一个多路选择器,工作时间会变长,对应的时钟频率会下降,而且每次同时选中多个cache line,功耗较大;而串行实现在用流水线来实现cache时会明显增加所需时钟周期数(多一个时钟周期)。
2.3、全相联
全相联是极端的组相联,即cache只有一个cache set。每一个data block都可以存进任何一个cache line。下图是对应关系。
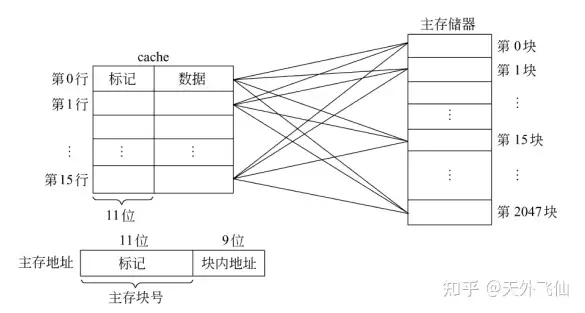
全相联下主存-cache对应关系
容易想到,全相联不需要index了,下图是实现电路。我们直接对照每一个cache line的tag并由此控制data的三态门输出。这个实现方法是很简单的,但是这里因为需要做大量的比较电路,所以工作延时也是巨大的。(why?因为CPU给出的地址的tag部分需要支持所有的比较电路,负载很大,负载可以简单化成一堆电容,负载很大相当于电容很大,电容很大,充电时间就长,相应的工作时间就长)
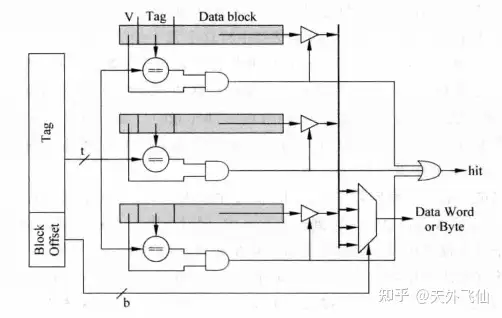
全相联电路实现
2.4、补充-SRAM
SRAM由于其读写速度快的特性,常常被拿来制作CPU内的cache。
下图是SRAM的电路结构,其中T1、T2用于保持A、B点状态,T5、T6构成T1、T2的负载管,T3、T4是选通管。
信息保持 当字选择线W没有被选中时,选通管关断,内部电路与外界隔绝,内部状态得以保持。值得注意的是在保持过程中内部电路一直有电流,这会产生功耗。
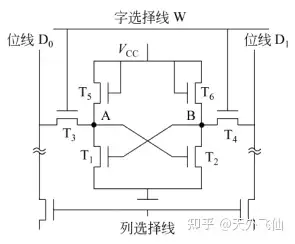
六管SRAM
读出 当字选择线W为高电平,T3、T4同时开启,A、B点是两个反馈点,简单地说A、B点电平是相反的,所以当T3、T4同时开启,因为A、B点的电平状态不同,位线D0、D1上产生的电流会有差异,根据电流的产生情况我们就能知道这一个六管SRAM存储的信息。再具体地说,如果A点是高电平,即六管SRAM存储“1”,则B点是低电平,位线D0会产生电流,位线D1不会产生电流。
写入 若要写入一位信息,首先选中字选择线W,然后选择性选通位线D0、D1,如果要写入信息“1”,则令位线D0为高电平,令位线D1为低电平,反之则写入信息“0”.
2.5、补充-三态门
ceche中每一cache set都包含多个cache line,当index确定之后,对应cache set中的每一个cache line内的数据都可能被取出,这时候我们有两种方法把正确的数据送到字节选择器中,一个方法是用多路选择器,多路选择器的复杂程度取决于我们设计的cache是几路cache,另一种方法是使用三态门。
三态门通常是用来驱动总线的,它允许我们把多个三态门的输出直接连到一根信号线上,条件是连到信号线上的多个输出在同一时刻只能有一个是有效值,其余的输出都应该是高阻态(z),高阻态可以阻断输出线与信号线的联系。
下图图(a)是三态门的逻辑门表达,E是使能信号,当E有效,三态门根据输入进行输出;当E无效,三态门输出高阻态。图(b)是三态门的电路结构,当E有效时,这是一个正常的输出缓冲门;当E无效时,两个MOS管(M表示)都是断开的,于是输出高阻态,输出阻抗极大。

三态门电路结构
3、Cache的写入
第二节主要介绍了cache的基本组成方式,电路实现也主要关注数据的读出,除此之外,cache还需要关注“写数据”的问题。
“写数据”关乎到两种情况:1、将被改写的数据在cache中;2、将被改写的数据不在cache中。
针对情况1,我们又有两种策略来写数据:1、只改写cache中对应的cache line,这被称为“写回”;2、改写cache line和主存,这被称为“写穿”。
第一种策略的优点是速度快,因为不用访问速度较慢的主存,缺点是只改写cache的话,cache line和主存中的数据不再一致,这会产生“一致性”问题,如果有别的核来访问主存中对应的block,那么它将会读到错误的数据。另外,在cache line被替换出去的时候,数据应该被写进主存,这就要求我们能够辨别哪些cache line是被改写过的,反映在电路上就需要增加一个“脏”位,当一个被标记为脏的cache line被替换出去,其内容需要被写入对应的主存。
第二种策略的优点是时刻保持存储器数据一致,缺点是每次store指令都需要往主存写入数据,这个延时代价是高昂的。
针对情况2,我们也有两种策略:1、直接把数据写入主存,此被称为“写不分配”;2、先把data block放进cache line,然后“写回”或是“写穿”,此被称为“写分配”。
一般情况下,“写回”和“写分配”组合,“写穿”和“写不分配组合”。下面两幅图是本节的重点!重点!重点!两幅图依次展示了“写穿”“写不分配”组合的工作流程、“写回”“写分配”组合的工作流程。

“写穿”“写不分配”组合的工作流程

“写回”“写分配”组合的工作流程
4、Cache的替换策略
不论是读数还是写数,一旦碰及miss,就可能需要做替换。读miss时需要从主存调入data block,而这个block可能需要顶替某个cache line,这时候需要替换算法来决定顶替谁。写的时候如果使用“写分配”,那也需要从主存调入data block。cache有很多替换策略,包括FIFO(先进先出)、LRU(近期最少使用)和随机替换等等,本节介绍LRU和随机替换这两种常用的替换方法。
4.1、近期最少使用
LRU的基本思想是选择最近一段时间使用次数最少的cache line进行替换,因此我们需要对一个cache set中的每一个cache line的使用情况进行跟踪,实现方法可以是为每一个cache line都设置一个“年龄位”。
如果是2路cache(即每一个cache set只有两个cache line),那么只需要一位“年龄位”。当一个cache line被使用,那么它的年龄为1,另一个line年龄为0。如果是多路cache,那么就需要多位“年龄位”,当一个cache line被使用,那么它对应的年龄就应该被设置为最大,其他cache line的年龄按照之前的顺序排在它之后,这个过程就好像是把单向链表中的某一节点拿出来放到链表的头,其余节点按照之前的顺序连接在头节点之后。替换的时候总是替换年龄最小的那个cache line,在链表中也就是把表尾去掉,然后把新的块放到表头。
年龄位是通俗易懂的,但是当cache set越来越大,如八路,那么年龄位的实现会变得很复杂,这时候我们有一个简单的方式来实现,首先来大略看看下面一幅图,重点看文字部分。

LRU算法工作流程
这个实现方法把八路cache进行分组,第一年龄位把cache set分成两组,一组四个cache line;第二年龄位把四个cache line又分成两组,以此类推。
图上的七个年龄位显示了访问cache line结束后的年龄情况,随着访存的变多,年龄位会慢慢地被填满,然后图中的箭头就会从第一级一路指向某一个way,这个cache line就是最近最少使用的cache line。图中的箭头还没有连完,因为图中只访存了way1和way5。
4.2、随机替换
在处理器中替换算法都是用硬件直接实现的,硬件复杂度可能会很高,有些情况下我们需要简单地实现替换功能,这时候随机替换就派上用场了。
随机替换不需要记录年龄,它只需要一个内置的时钟计数器,每当要替换cache line,就根据计数器的当前计数结果来替换cache line。
这样的方法优点是实现起来很简单,缺点是它不能体现出数据的使用的规律,因为它可能把最近最新使用的数据给替换出去,不过随着cache的容量越来越大,这个缺点所带来的性能损失也越来越小。总的来说,这是一个折中的办法。
小结
本文主要介绍了cache的基本常识、基本组成方式、写入方式和替换策略,在基本组成方式和替换策略两节给出了较为详细的硬件实现方法,并不流于空泛,并且补充了SRAM和三态门等与硬件实现息息相关的知识。更高阶的cache优化方法和cache设计实例会在将来更新。
参考资料
本文重点参考了几本计算机体系结构的相关书籍,详情可见下文:
[转帖]计算机体系结构-cache高速缓存的更多相关文章
- 计算机组成原理——cache高速缓存存储器
转载自https://blog.csdn.net/chen1083376511/article/details/8187481 cache-高速缓存存储器 在主存与CPU之间插入一级或多级SRAM组成 ...
- 计算机体系结构——CH3存储系统
计算机体系结构--CH3存储系统 右键点击查看图像,查看清晰图像 X-mind 计算机体系结构--CH3存储系统 存储系统原理 主要性能 速度 容量 价格 两种存储系统 Cache与主存储器 虚拟存储 ...
- 计算机体系结构的铁律(iron law)
计算机体系结构的铁律可由下面公式来描写叙述: 从Programmer的角度来看,处理器的性能就是运行程序的耗费的时间.所以用Time/Program来刻画处理器性能.而这个简单的公式背后是有很丰富的内 ...
- 计算机体系结构总结_Pipeline
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR 在前面一节里我们有了一块简单的RISC CPU,包括 ...
- 计算机体系结构——CH5 标量处理机
计算机体系结构--CH5 标量处理机 右键点击查看图像,查看清晰图像 X-mind 计算机体系结构--CH5 标量处理机 先行控制技术 指令得重叠执行方式 顺序执行方式 一次重叠执行方式 二次重叠技术 ...
- 计算机体系结构——CH4 输入输出系统
计算机体系结构--CH4 输入输出系统 右键点击查看图像,查看清晰图像 X-mind 计算机体系结构--CH4 输入输出系统 输入输出原理 特点 实时性 与设备无关性 异步性 输入输出系统的组织方式 ...
- 计算机的Cache和Memory访问时Write-back,Write-through及write allocate的区别
计算机的存储系统采用Register,Cache,Memory和I/O的方式来构成存储系统,无疑是一个性能和经济性的妥协的产物.Cache和Memory机制是计算机硬件的基础内容,这里就不再啰嗦.下面 ...
- [转帖]关于CPU Cache -- 程序猿需要知道的那些事
关于CPU Cache -- 程序猿需要知道的那些事 很早之前读过作者的blog 记得作者在facebook 工作.. 还写过mysql相关的内容 大拿 本文将介绍一些作为程序猿或者IT从业者应该知道 ...
- 计算机体系结构——流水线技术(Pipelining)
本文导读: 一.并行技术 .并行技术分类 .新技术的设计与实现 .指令周期 二.流水线技术 .什么是流水线 .指令重叠方式 .流水工作设计 .流水线的描述方法(时空图) .流水线特点 三.流水线的分类 ...
- 计算机体系结构——CH1基本概念
CH1基本概念 右键点击查看图像,查看清晰图像 CH1基本概念 目的与内容 了解计算机系统的完整概念 学习计算机系统的分析方法与设计方法 编写程序所必需了解的计算机属性 计算机系统结构简介 为什么要研 ...
随机推荐
- MongoDB经典故障系列六:CPU利用率太高怎么办?
每逢电商大促,全民狂欢,但热闹是属于疯狂剁手的人们.而开发者们有的缺是"高流量.高访问.高并发"三高下带来的种种问题.为了应对大促期间的高I/O情况,企业会选择MongoDB云数据 ...
- 跨越全场景统一架构三大挑战,MindSpore亮出“四招”
摘要:本文重点剖析全场景统一的AI框架的挑战和MindSpore的解决思路. 2020年的最后一天,MindSpore发布了1.1版本,1.1中很重要的特性是构建了端边云全场景统一的基础架构: htt ...
- 互斥锁Mutex:鸿蒙轻内核中处理临界资源独占的“法官”
摘要:本文带领大家一起剖析鸿蒙轻内核的互斥锁模块的源代码,包含互斥锁的结构体.互斥锁池初始化.互斥锁创建删除.申请释放等. 本文分享自华为云社区<鸿蒙轻内核M核源码分析系列十 互斥锁Mutex& ...
- 火山引擎DataTester:跨境电商网站,如何快速实施AB测试 ?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 如今中企出海的形态愈加多样,很多企业都建有独立站可直接触达海外客户,但获取优质流量的成本会更加高昂.当优质流量 ...
- 差点错过!火山引擎VeDI帮这家企业成功挖掘200余条商机
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 与个体消费市场临时性需求大.决策参与人少等情况不同,企业消费市场往往因为长线需求复杂.商品/服务的价格高.参与决策 ...
- 火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 近日,<火山引擎云原生数据仓库 ByteHouse 技术白皮书>正式发布.白皮书简述了 ByteHou ...
- Docker 安装 ELK,EFK代替
ELK 版本因为 前面 Elasticsearch 用的 7.9.3 版本,所以 kibana-7.9.3.logstash-7.9.3 都用 7.9.3 版本 安装配置 Elasticsearch ...
- 初始环境(centos7)
#!/bin/bash yum -y install wget #更换阿里源 下载epel源 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d ...
- vue.js 本地调用远程接口进行开发,如何进行跨域及cookie传递
在前后端分离vue作为前端框架,在使用服务器接口时面临的第一个问题就是跨域.本文涉及内容仅保证在vue-cli3.0脚手架创建的项目中.及本地调试中有效(使用之前版本脚手架创建的项目请自行转换),本文 ...
- 与奥运同行:打造智慧体育馆 3D 可视化
祝贺中国队在东京奥运会夺得金牌 38 枚.银牌 32 枚.铜牌 18 枚.中国健儿在奥运舞台上交出了一份璀璨的成绩单.用一场场精彩绝伦的比赛,演绎"更快.更高.更强.更团结"的奥林 ...