CDP技术系列(一):使用bitmap存储数十亿用户ID的标签或群体
一、背景介绍
CDP系统中目前存在大量由用户ID集合组成的标签和群体,截止当前已有几千+标签,群体2W+。
大量的标签都是亿级别数据量以上,例如性别、职业、学历等均,甚至有群体中的ID数量达到了数十亿+。
并且随着用户ID池的不断增加,标签和群体本身包含的ID数量也随之增加,如何存储如此多的数据,标签与群体之间的组合计算,是我们面临的挑战。
二、问题描述
如此大量的用户ID集合,虽然标签和群体的ID集合本质类似,但是都需要存储亿级别的ID数据,这就对存储结构提出较高的要求。
这里拿群体举例,如果某群体包含1000W个用户ID,通过文本文件存储,大概需要150M,40亿的群体就达到了惊人的150*40*10=60000M,大约60G,而我们的群体数量已经达到了几W+,再加上标签数据,所需要的存储空间将不可接受。
并且,数据的存储只是其中一个方面,后续针对标签和群体的组合计算,创建出更细粒度的ID包也是一个挑战。
三、解决方案
面对以上问题,CDP采用了Bitmap的思路来解决,不但解决了存储空间问题,而且Bitmap本身的交并差运算,能够很好的支持用户对不同标签和群体的组合计算,详细方案如下。
1)Bitmap简介
为了便于理解,首先介绍一下什么是bitmap。
它的基本思想是用bit位来唯一标记某个数值,这样可以用它来记录一个数值没有重复的数据元组。并且每一条数据只使用一个bit来标识,能够大大的节省存储空间。
比如,我想存储一个数值数组[2,4,6,8]。
Java中如果用byte类型来存储,不考虑其他开销,需要4个字节的空间,一个字节8位,也就是4*8=32bit。
倘若使用更大的数据类型,存储空间也会相应增大,如使用Integer(4字节),则需要4*4*8=128bit。
而如果采用bitmap的思想,只需要构建一个8bit空间,也就是一个字节的空间来存储,如下图。
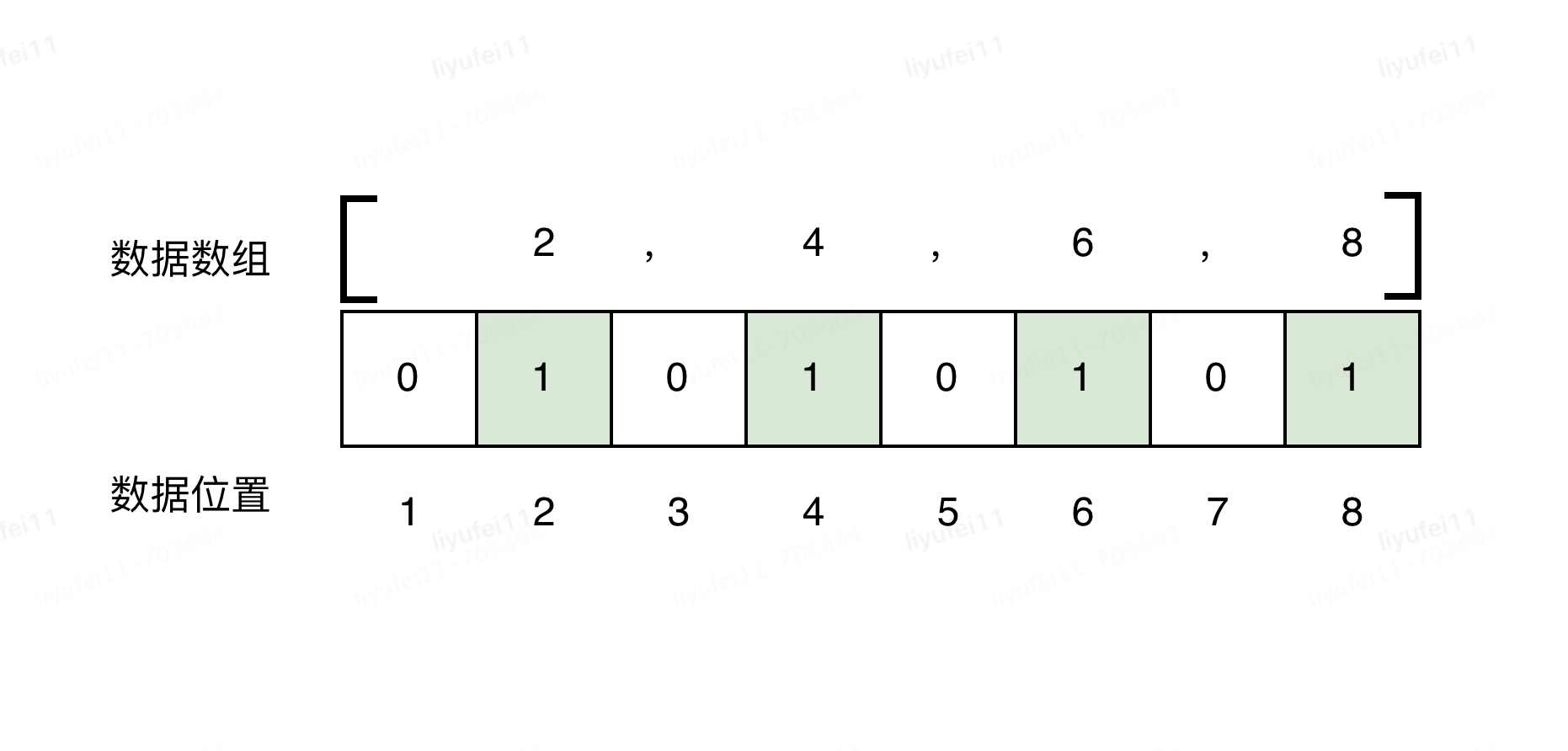
2)用户ID池编码
通过上文的例子,可以看到,使用Bitmap思想来存储,实际上每一个数据是一个bit,而且不能重复,这一点用户ID是符合的,没有重复的用户ID。
由于bitmap里只能存0或者1来标识当前位是否有值,而用户ID确是一个字符串,这就需要将数十亿的用户ID进行唯一性编码,这个编码也就是我们常说的offset偏移量。
每一个用户ID对应一个唯一的offset,目前已到数十亿,也就是说当前最大的偏移量是数十亿+,这部分由数据同学帮我们加工一张ID池表,其中包含了ID和offset的对应关系。这样,新注册的id,只要顺序增加offset值即可。
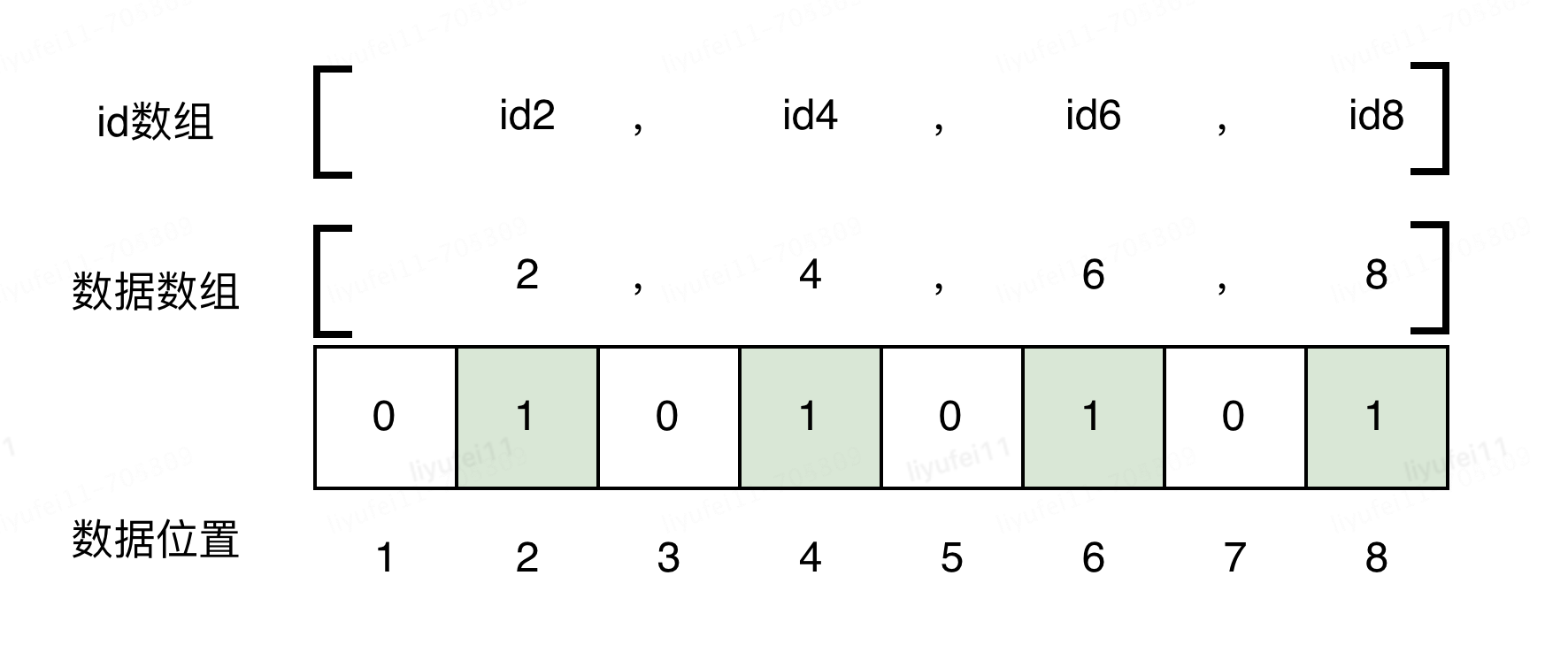
下边是一个简单示意图,假设我有8个id,id1~id8,对应的offset编号为1~8。
我要建一个只包含双数id的标签或群体,则我只需要将offset为2,4,6,8的位设为1即可。
3)遇到问题
有了存储的数据结构,还有id池,接下来就是具体实现了。
提到Bitmap,首先想到的是Java中的一种实现方案BitSet,不过它存在两个问题。
一是我们的id池已经到达几十亿+,已经超出了BitSet所能处理的范围,当前超出了2^32=4294967296。
另一个问题是,倘若我建一个包含两个id的群体,第一个offset是1,第二个offset是10000000,这种情况还是要创建一个1000wbit的空间来存储,并且只有两个bit位是1,其他的全为0,这显然造成了很大的空间浪费。
也就是说,数据越稀疏,空间浪费越严重

下方位BitSet扩容时的代码,由代码中也可以看到,默认扩容2倍,当需要的大小超过2倍时,则按照需要扩容。
public void set(int bitIndex) {
if (bitIndex 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
int wordIndex = wordIndex(bitIndex);
expandTo(wordIndex);
words[wordIndex] ); // Restores invariants
checkInvariants();
}
private void expandTo(int wordIndex) {
int wordsRequired = wordIndex+1;
if (wordsInUse ) {
ensureCapacity(wordsRequired);
wordsInUse = wordsRequired;
}
}
private void ensureCapacity(int wordsRequired) {
if (words.length ) {
// Allocate larger of doubled size or required size
int request = Math.max(2 * words.length, wordsRequired);
words = Arrays.copyOf(words, request);
sizeIsSticky = false;
}
}
当用户圈的群体特别稀疏时,有可能会造成很大的空间浪费,所以,我们需要使用一种能够压缩的高效的位图实现。
4)RoaringBitmap压缩
我们最终使用的是RoaringBitmap,一种高效的压缩位图实现,简称RBM。于2016年由S. Chambi、D. Lemire、O. Kaser等人在论文《Better bitmap performance with Roaring bitmaps》 《Consistently faster and smaller compressed bitmaps with Roaring》中提出。
基本实现思路如下:
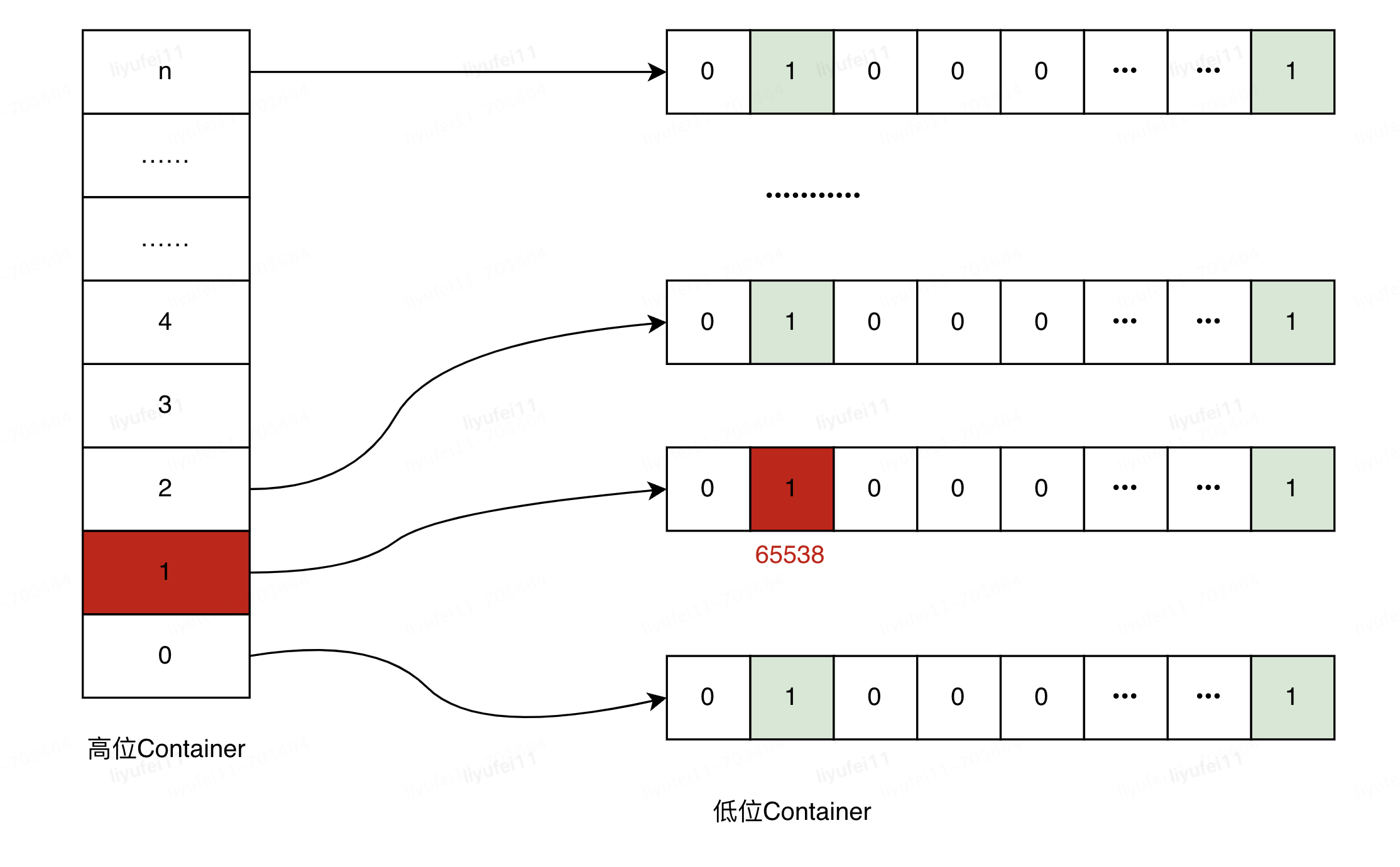
以整型int(32位)为例,将数据分成高16位和低16位两部分,低16位不变,作为数据位Container,高16位作为桶的编号Container,可以理解为高位的Container中,存放了很多个低位Container。
高低位计算示例:
protected static char highbits(int x) {
return (char) (x 16);
}
protected static char lowbits(int x) {
return (char) x;
}
比如,我要存放65538这个值,则高位为65538>>>16=1,低位为65538-65536*1=2,即存储在1号桶的2号位置,存储位置如下图:
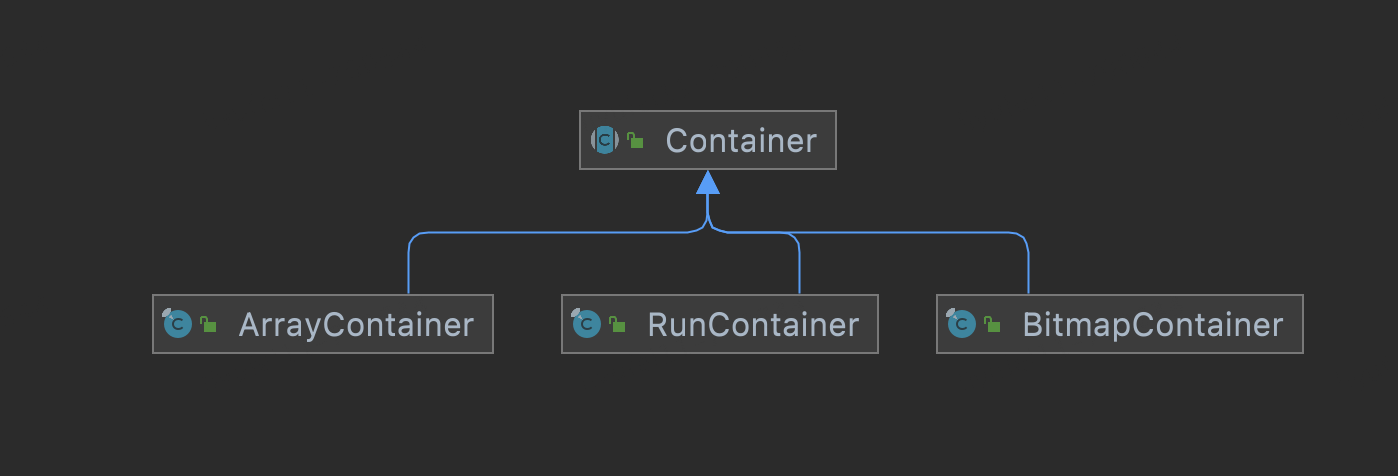
我们当前使用的RoaringBitmap版本为0.8.13,Container包含了三种实现:ArrayContainer(数组容器),BitmapContainer(位图容器),RunContainer(行程步长容器)
不过,上文中提到当前id池已经超过了整型所能标识的最大范围(2^32=4294967296),所以需要一个能够处理64位的实现,我们使用了RoaringBitmap包中支持64位的Roaring64NavigableMap。
它的实现思路和32位的基本一致,分成了高32位和低32位两部分
jar包引入方式:
<dependency>
<groupId>org.roaringbitmap/groupId>
<artifactId>RoaringBitmap/artifactId>
<version>0.8.13/version>
/dependency>
public void add(long... dat) {
for (long oneLong : dat) {
addLong(oneLong);
}
}
public void addLong(long x) {
int high = high(x);
int low = low(x);
…………
}
public static int high(long id) {
return (int) (id 32);
}
public static int low(long id) {
return (int) id;
}
bitmap位图操作方法:
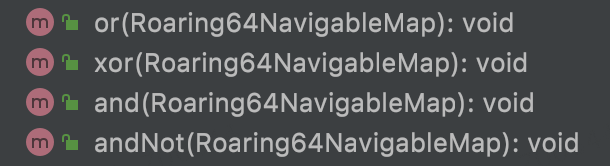
四、现状及展望
目前,CDP画像的标签和群体均采用了RoaringBitmap的存储方式。人群和标签的交并差计算,生成更加精细化的人群就可以通过bitmap的操作来实现。
有了良好的存储方式,下一步就是如何将存储在数据仓库的明细数据,加工成原始的标签或者群体,具体实现方案会在下一篇分享。
CDP技术系列(一):使用bitmap存储数十亿用户ID的标签或群体的更多相关文章
- Google将数十亿行代码储存在单一的源码库
过去16年,Google使用一个中心化源码控制系统去管理一个日益庞大的单一共享源码库.它的代码库包含了约10亿个文件(有重复文件和分支)和 3500万行注解,86TB数据,900万唯一源文件中含有大约 ...
- 替代或者与 Redis 配合存储十亿级别列表的数据.
http://ssdb.io/docs/zh_cn/index.html 用户案例 如果你在生产环境中使用 SSDB, 欢迎你给我发邮件(ssdb#udpwork.com), 我很愿意把你加入到下面的 ...
- Redis如何存储和计算一亿用户的活跃度
1 前段时间,在网上看到一道面试题: 如何用redis存储统计1亿用户一年的登陆情况,并快速检索任意时间窗口内的活跃用户数量. 觉得很有意思,就仔细想了下 .并做了一系列实验,自己模拟了下 .还是有点 ...
- ☕【难点攻克技术系列】「海量数据计算系列」如何使用BitMap在海量数据中对相应的进行去重、查找和排序
BitMap(位图)的介绍 BitMap从字面的意思,很多人认为是位图,其实准确的来说,翻译成基于位的映射,其中数据库中有一种索引就叫做位图索引. 在具有性能优化的数据结构中,大家使用最多的就是has ...
- 11.Java 加解密技术系列之 总结
Java 加解密技术系列之 总结 序 背景 分类 常用算法 原理 关于代码 结束语 序 上一篇文章中简单的介绍了第二种非对称加密算法 — — DH,这种算法也经常被叫做密钥交换协议,它主要是针对密钥的 ...
- 2.Java 加解密技术系列之 MD5
Java 加解密技术系列之 MD5 序 背景 正文 结束语 序 上一篇文章中,介绍了最基础的编码方式 — — BASE64,也简单的提了一下编码的原理.这篇文章继续加解密的系列,当然也是介绍比较基础的 ...
- 1.Java 加解密技术系列之 BASE64
Java 加解密技术系列之 BASE64 序号 背景 正文 总结 序 这段时间,工作中 用到了 Java 的加解密技术,本着学习的态度,打算从这篇文章开始,详细的研究一番 Java 在加解密技术上有什 ...
- 【转】Entity Framework技术系列之7:LINQ to Entities
前言 LINQ(Language Integrated Query,语言集成查询)是一组用于C#和VB.NET语言的扩展,它允许编写C#或者VB.NET代码,以与查询数据库相同的方式操作内存数据. L ...
- Azure Messaging-ServiceBus Messaging消息队列技术系列4-复杂对象消息是否需要支持序列化和消息持久化
在上一篇中,我们介绍了消息的顺序收发保证: Azure Messaging-ServiceBus Messaging消息队列技术系列3-消息顺序保证 在本文中我们主要介绍下复杂对象消息是否需要支持序列 ...
- Azure Messaging-ServiceBus Messaging消息队列技术系列5-重复消息:at-least-once at-most-once
上篇博客中,我们用实际的业务场景和代码示例了Azure Messaging-ServiceBus Messaging对复杂对象消息的支持和消息的持久化: Azure Messaging-Service ...
随机推荐
- 使用 Python Poetry 进行依赖管理
摘要:在本教程中,您探索了如何创建新的 Python Poetry 项目以及如何将 Poetry 添加到现有项目中. 本文分享自华为云社区<使用 Python Poetry 进行依赖管理> ...
- Axure 二维码扫码
基础布局 1.一个300X395的黑底黑框矩形,不透明度为20%,命名为"背景框": 2.一个150X150的白底白框矩形,不透明度为70%,命名为"扫描框": ...
- C++11实用特性1
1 原始字面量 有时候在输出一个路径字符串时,编译器会将其中的部分内容识别成转义字符进行输出,可以用R "xxx(原始字符串)xxx"其中()两边的字符串可以省略.原始字面量R可以 ...
- CO40/CO41转生产订单下达时不能创建采购申请
一.配置 CO01创建生产订单,创建时生成采购申请,改为下达时创建采购申请.通过配置,将预留/采购申请 更改为2即可. 但是CO41和CO40通过配置,并不能达到更改预留/采购申请 为2. 二.调试源 ...
- 安装vue脚手架@vue/cli 4.5.13(稳定版)
若 NPM 下载过慢,请参考本处改换镜像源:Here 首先新建一个 vue 测试项目,还记得以前自己是用 vue-cli 2.0的版本 去构建的,毕竟里面有默认配置好的webpack配置,但现在很多小 ...
- SpringBoot 项目实战 | 瑞吉外卖 Day05
该系列将记录一份完整的实战项目的完成过程,该篇属于第五天 案例来自B站黑马程序员Java项目实战<瑞吉外卖>,请结合课程资料阅读以下内容 该篇我们将完成以下内容: 新增套餐 套餐信息分页查 ...
- 字符串匹配算法:Horspool算法
Horspool 字符串匹配算法对Boyer-Moore算法的简化算法. Horspool 算法是一种基于后缀匹配的方法,是一种"跳跃式"匹配算法,具有sub-linear亚线性时 ...
- 阿里云 Serverless 应用引擎(SAE)2
8月7日,阿里云 Serverless 应用引擎(SAE)2.0正式公测上线!全面升级后的SAE 2.0具备极简体验.标准开放.极致弹性三大优势,应用冷启动全面提效,秒级完成创建发布应用,应用成本下降 ...
- vue axiox网络请求
一.首先安装axios ,vue-axios 前提:搭建一个vue3的项目 项目搭建参考:https://www.cnblogs.com/yclh/p/15356171.html 使用npm安装axi ...
- 大数据(3)---HDFS客户端命令及java连接
一.参数设置 之前有说到HDFS的备份数量和切块大小都是可以配置的,默认是备份3,切块大小默认128M 文件的切块大小和存储的副本数量,都是由客户端决定! 所谓的由客户端决定,是通过客户端机器上面的配 ...