图查询语言 nGQL 简明教程 vol.01 快速入门

本文旨在让新手快速了解 nGQL,掌握方向,之后可以脚踩在地上借助文档写出任何心中的 NebulaGraph 图查询。
视频
本教程的视频版在B站这里。
准备工作
在正式开始 nGQL 实操之前,记得先看过文档「快速入门流程」,部署、连接过 NebulaGraph,并且看过了「常用命令」。如果你还没看过这两个文档,为了跟上进度,记得先快速过一遍,上面两个文档链接可在文末「参考资料」中获取。
我们的目标是
本教程目的在于让大家大概知道了 NebulaGraph 的查询语句后,解决“不知道什么样的查询应该用什么语句”的问题。
nGQL 是什么
我们先强调一下概念:nGQL 是 NebulaGraph Query Language 的缩写,它表示 NebulaGraph 的查询语言,可以不严谨地分为这 5 部分:
- NebulaGraph 独有 DQL(Data Query Language)查询语句
- NebulaGraph openCypher DQL
- NebulaGraph DML(Data Mutation Language)写语句
- NebulaGraph DDL(Data Definition Language) Schema 语句
- NebulaGraph Admin Queries 管理语句
这里,作为简明教程一把梭,我们只关注前两个部分,后边的内容会在 Part 2 中介绍。
nGQL 速查表 cheatsheet
大家可以保存下这份单页速查表,一次了解所有 nGQL 的用法。
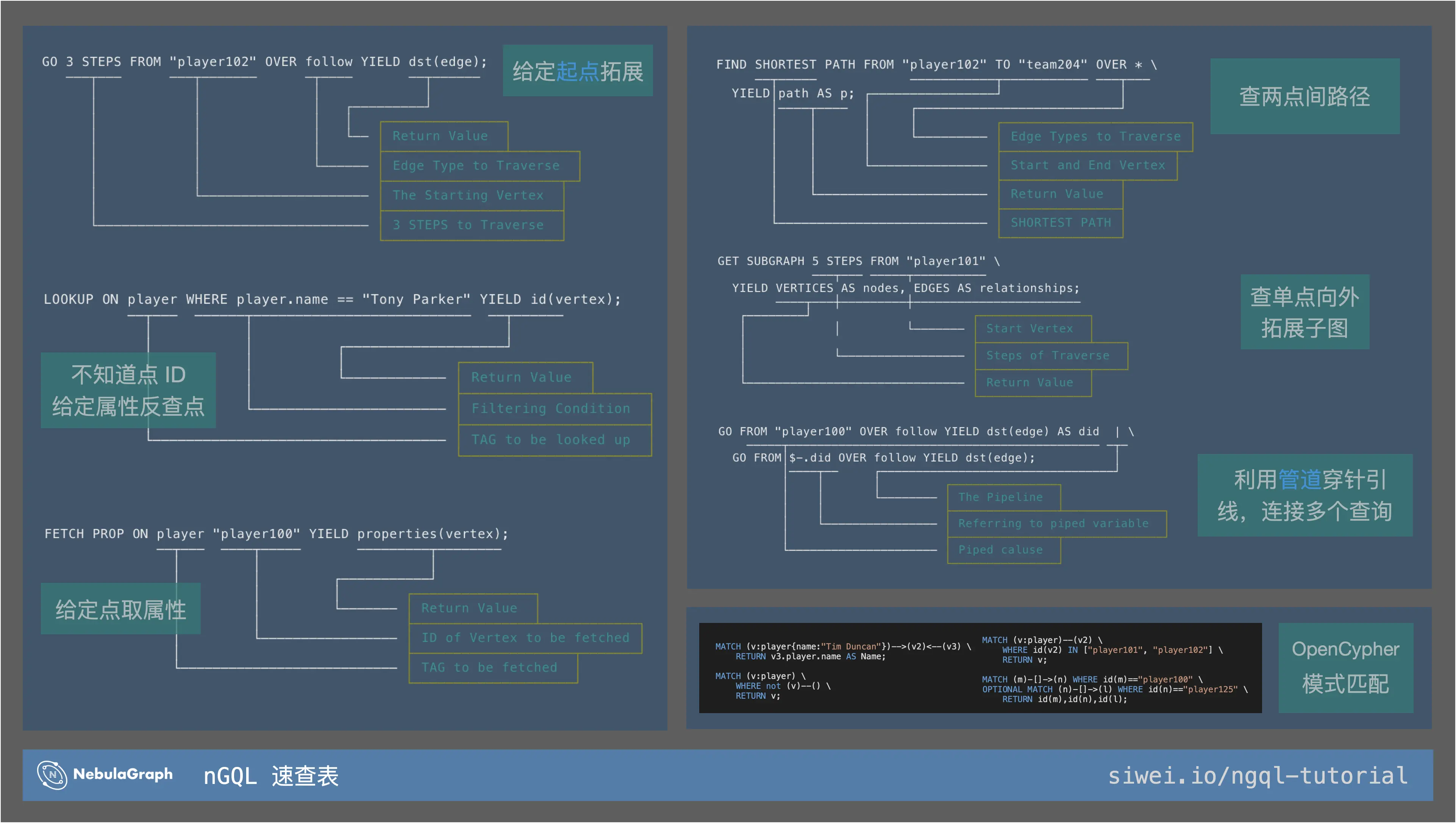
NebulaGraph 独有 DQL
NebulaGraph 的独有读查询语句的设计非常简洁,对初学者非常友好。它结合了管道的概念,做到了只涉及了几个关键词就可以描述出大多数的图查询模式。由于篇幅的问题,所有 DQL 查询语句的更多用法记得查阅本文的「参考资料」。
简单来说,nGQL 的独有 DQL 一共分成四类语句:
- 图拓展 / 遍历:
GO - 索引反查:
LOOKUP - 取属性:
FETCH - 路径与子图:
FIND PATH与GET SUBGRAPH
和两个特别的元素:
- 管道:
| - 引用属性:
$开头的几个符号,用来描述一些特定的上下文
用 GO 来图拓展 / 遍历
GO 的语义非常直观:从给定的起点,向外拓展,按需返回终点、起点的信息。
# 图拓展
GO 3 STEPS FROM "player102" OVER follow YIELD dst(edge);
───┬─── ───┬─────── ─┬──── ──┬──────
│ │ │ ┌─────────┘
│ │ │ │
│ │ │ └── 返回最后一跳边的终点
│ │ │
│ │ └────── 从 follow 这个边[出方向]探索
│ │
│ └───────────────────── 起点是 "player102"
│
└────────────────────────────────── 探索 3 步
这里只是做了一个简单的 GO 语法示例,像 GO 实现的反向、双向拓展,指定可变跳数遍历等,更多 GO 语句用法可查阅参考资料。
LOOKUP 基于索引反查 ID
和 GO 的从已知的点出发相反,LOOKUP 是一个类似于 SQL 里 SELECT 语义的关键字,它实际的作用也类似与关系型数据库中的扫表。
LOOKUP 需要手动创建相应 TAG、边类型上索引才能进行相关查询。
为什么 LOOKUP 需要索引?
因为 NebulaGraph 中的数据默认是按照邻接表的形式存储,在分布式设计中,扫描一个类型的点、边是非常昂贵的,所以它被默认禁止了。NebulaGraph 索引的存在增加了类似于表结构数据库的排序数据,可以用来做像是 SELECT 的查询。
# 索引反查
LOOKUP ON player WHERE player.name == "Tony Parker" YIELD id(vertex);
──┬─── ──────┬────────────────────────── ──┬──────
│ │ ┌───────────────────┘
│ │ │
│ │ └──────────── 返回查到点的 VID
│ │
│ └─────────────────────── 过滤条件是属性 name 的值
│
└─────────────────────────────────── 根据点的类别/TAG player 查询
本文仅作 LOOKUP 语法的使用入门,关于索引原理和使用,比如:创建索引会有什么代价?索引会加速读么?记得查看文末的参考资料。
FETCH PROP 获取属性
如字面意思,如果我们知道一个点、边的 ID,想要获取它上边的属性,这时候我们要用 FETCH PROP 而非 LOOKUP。
# 取属性
FETCH PROP ON player "player100" YIELD properties(vertex);
──┬─── ────┬───── ─────────┬────────
│ │ ┌───────────┘
│ │ │
│ │ └─────── 返回点的 player TAG 下所有属性
│ │
│ └───────────────── 从 "player100" 这个点获取
│
└─────────────────────────── 获取 player 这个 TAG 下的属性
路径查找 FIND PATH
如果我们要找到指定两点之间的所有路径,一定要用 FIND PATH。
# 起点终点间路径
FIND SHORTEST PATH FROM "player102" TO "team204" OVER * \
──┬───── ───────────┬─────────── ───┬───
YIELD│path AS p; ┌────────────────┘ │
│────┬──── │ ┌──────────────────────────┘
│ │ │ │
│ │ │ └───────── 经由所有类型的边出向探索
│ │ │
│ │ └─────────────── 从给定的起点、终点 VID
│ │
│ └────────────────────── 返回路径为 p 列
│
└─────────────────────────── 查找最短路径
单点子图 GET SUBGRAPH
和路径查找类似,如果我们只给定一个起点和拓展步数,用 GET SUBGRAPH 可以帮我们获取同样的 BFS 出去的子图。
# 单点 BFS 子图
GET SUBGRAPH 5 STEPS FROM "player101" \
───┬─── ─────┬──────────
YIELD VERTICES AS nodes, EDGES AS relationships;
────┬───┼─────────┼───────────────────────
┌────────┘ │ │
│ │ └─────── 从 "player101" 开始触发
│ │
│ └───────────────── 获取 5 步的探索
│
└────────────────────────────── 返回所有的点、边
利用管道和属性引用符
NebulaGraph 的管道设计和 Unix-Shell 的设计很像,可以将简单的几种语句结合起来,有强大的表达力。
# 使用通道
GO FROM "player100" OVER follow YIELD dst(edge) AS did | \
─────┬──────────────────────────────────────────── ─┬─
GO FROM│$-.did OVER follow YIELD dst(edge); │
│────┬── ┌─────────────────────────────────┘
│ │ │
│ │ └──────── 管道将左边的 AS 输出作为右边语句输入
│ │
│ └──────────────── 从管道左边的 did 属性开始探索
│
└───────────────────── 第一个查询语句
除了以上的集中表达之外,NebulaGraph 独有查询语句还有聚合的表达参考 GROUP-BY,另外在文档里还有一个 Cheatsheet供大家查询一些复杂的例子。
NebulaGraph openCypher DQL
从 NebulaGraph v2.0 起,openCypher 的 MATCH 语句也被 NebulaGraph 原生支持了。虽然 NebulaGraph 这里是一个“方言”,有一些使用细节差异。
MATCH <pattern> [<clause_1>] RETURN <output> [<clause_2>];
MATCH 的基本表达是由 (v:tag_a) 包裹的点和 --> 或者 <-[:edge_type_1]- 表达的边组成的模式,再与 RETURN 结合表达输出。
如果你从 Cypher 的查询语言入门图数据库,可以从下边几个例子了解到若干 NebulaGraph 里的使用细节差异:
- 增加了
WHERE id(v) == "foo"的表达; ==表达相等判断而不是=;- 点的属性表达需要填写 TAG,例如
v3.player.name而不是v3.name;
MATCH (v:`player`{name:"Tim Duncan"})-->(v2)<--(v3) \
RETURN v3.`player`.name AS Name;
MATCH (v:`player`) \
WHERE NOT (v)--() \
RETURN v;
MATCH (v:`player`)--(v2) \
WHERE id(v2) IN ["player101", "player102"] \
RETURN v;
MATCH (m)-[]->(n) WHERE id(m)=="player100" \
OPTIONAL MATCH (n)-[]->(l) WHERE id(n)=="player125" \
RETURN id(m), id(n), id(l);
以上,为本次简明教程的第一集。
参考资料
- 快速入门 NebulaGraph:https://docs.nebula-graph.com.cn/3.2.0/2.quick-start/1.quick-start-workflow/
- nGQL 常见命令:https://docs.nebula-graph.com.cn/3.2.0/2.quick-start/4.nebula-graph-crud/
- GO 语句文档:https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/7.general-query-statements/3.go/
- 全方位讲解 NebulaGraph 索引原理和使用:https://discuss.nebula-graph.com.cn/t/topic/8074
- LOOKUP 语句文档:https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/7.general-query-statements/5.lookup/
- FETCH PROP 语句文档:https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/7.general-query-statements/4.fetch/
- GET SUBGRAPH 语句文档:https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/16.subgraph-and-path/1.get-subgraph/
- 管道 | 文档:https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/5.operators/4.pipe/
- 引用符 $ 文档:https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/5.operators/5.property-reference/
- GROUP-BY:https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/8.clauses-and-options/group-by/
- nGQL Cheatsheet:https://docs.nebula-graph.com.cn/3.2.0/2.quick-start/6.cheatsheet-for-ngql-command/
- MATCH 语句文档:https://docs.nebula-graph.com.cn/3.2.0/3.ngql-guide/7.general-query-statements/2.match/
谢谢你读完本文 (///▽///)
免部署省时省力,现在可以用用 NebulaGraph Cloud 来搭建自己的图数据系统哟~NebulaGraph 阿里云计算巢现 30 天免费使用中,点击链接来用用图数据库吧~
想看源码的小伙伴可以前往 GitHub 阅读、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呢~
图查询语言 nGQL 简明教程 vol.01 快速入门的更多相关文章
- JasperReports入门教程(一):快速入门
JasperReports入门教程(一):快速入门 背景 现在公司的项目需要实现一个可以配置的报表,以便快速的适应客户的需求变化.后来在网上查资料发现可以使用JasperReports + Jaspe ...
- Spring Boot 2 快速教程:WebFlux 快速入门(二)
摘要: 原创出处 https://www.bysocket.com 「公众号:泥瓦匠BYSocket 」欢迎关注和转载,保留摘要,谢谢! 02:WebFlux 快速入门实践 文章工程: JDK 1.8 ...
- spring boot入门教程——Spring Boot快速入门指南
Spring Boot已成为当今最流行的微服务开发框架,本文是如何使用Spring Boot快速开始Web微服务开发的指南,我们将使创建一个可运行的包含内嵌Web容器(默认使用的是Tomcat)的可运 ...
- Expression Blend实例中文教程(9) - 行为快速入门Behaviors
在Blend强大的设计功能支持下,设计人员和开发人员可以无代码实现Silverlight/WPF动画效果,例如上文介绍的StoryBoard,就是一个典型例子,设计人员和开发人员仅需提供必要元素,即可 ...
- MyBatis 学习总结 01 快速入门
本文测试源码下载地址: http://onl5wa4sd.bkt.clouddn.com/MyBatis0918.rar 一.Mybatis介绍 MyBatis是一个支持普通SQL查询,存储过程和高级 ...
- Expression Blend实例中文教程(2) - 界面快速入门
上一篇主要介绍Expression系列产品,另外概述了Blend的强大功能,本篇将用Blend 3创建一个新Silverlight项目,通过创建的过程,对Blend进行快速入门学习. 在开始使用Ble ...
- emWin 2天速成实例教程000_如何快速入门ucGUI/emWin
备注:(1)打开工程目录下的"Exe\GUISimulationDebug.exe"即可看到效果.(2)看完教程000-005就基本会用emWin做项目,其他章节可以需要时再参考. ...
- 几张图帮你理解 docker 基本原理及快速入门
写的非常好的一篇文章,不知道为什么被删除了. 利用Google快照,做个存档. 快照地址:地址 作者地址:青牛 什么是docker Docker 是一个开源项目,诞生于 2013 年初,最初是 do ...
- SignalR系列教程:SignalR快速入门
---恢复内容开始--- 本篇是SignalR系列教程的第一篇,本篇内容介绍了如何创建SignalR应用,如何利用SignalR搭建简易的聊天室等,本篇内容参考自:http://www.asp.net ...
- Shell脚本深入教程(1):快速入门
Shell脚本基础入门 Bash注释 Bash只支持单行注释,使用#开头的都被当作注释语句: # 整行注释 echo hello world # 行尾注释 通过Bash的一些特性,可以取巧实现多行注释 ...
随机推荐
- 【验证码逆向专栏】某度滑块、点选、旋转验证码 v1、v2 逆向分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容.敏感网址.数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 本文章未经许 ...
- 手撕Vue-监听数据变化
经过上一篇的介绍,已经实现了将模板编译成具体数据,接下来要介绍的是如何监听数据的变化,本章主要完成这个需求即可. 在我们文章的开始,我写了一个 Vue 双向数据绑定原理的文章当中封装了一个 Obser ...
- 微信小程序-页面生命周期方法
在经过上一篇文章的介绍之后,我们知道了大体的生命周期在什么时候执行,这次主要是以代码的形式来展示一下具体的阶段执行什么生命周期方法. 首先我们编写一个代码可以从首页跳转到日志页面: <!--in ...
- vi / vim编辑器的使用 [补档-2023-07-01]
vi/vim编辑器 vi/vim编辑器是linux中的文本编辑器,其中vim比vi的功能更加强大,可以编辑shell程序,推荐使用vim,下面也将介绍vim如何使用. 2-1 vi/vim的三种工 ...
- PHP 会话(Session)实现用户登陆功能
PHP 会话(Session)实现用户登陆功能 Session 的工作机制是:为每个访客创建一个唯一的 id (UID),并基于这个 UID 来存储变量.UID 存储在 cookie 中,或者通过 U ...
- Oracle 11g ADG 部署(duplicate)快速参考
本文旨在指导客户完成Oracle 11g的ADG部署工作,主库环境已具备,备库环境已安装完成数据库软件. 环境:RHEL 6.8 + Oracle 11.2.0.4 1.确认主库运行在归档模式 2.确 ...
- Linux Shell获取指定日期 N 天/月/年前(后)的日期
我们有时候在写批处理 Shell 脚本时,可能需要获取指定日期前(后) N 天/月/年的日期,这里的 N 可以是 1 天/月/年.2 天/月/年.3 天/月/年等等.方法其实很简单,这里做一个简单记录 ...
- NOI 2023 题解
Copper Loser 的题解-- Day1 T1 方格染色 有一个 \(n\times m\) 的网格,有 \(Q\) 次操作,每次形如有三种:将 \((x_i+j,y_i)\)/\((x_i,y ...
- PCIE分层结构
PCIe分层结构 绝大多数的总线或者接口,都是采用分层实现的.PCIe也不例外,它的层次结构如下: PCIe定义了下三层(彩色部分):事务层(Transaction Layer),数据链路层(Data ...
- python中两个不同shape的数组间运算规则
1 前言 声明:本博客讨论的数组间运算是指四则运算,如:a+b.a-b.a*b.a/b,不包括 a.dot(b) 等运算,由于 numpy 和 tensorflow 中都遵循相同的规则,本博客以 nu ...