算法金 | Transformer,一个神奇的算法模型!!

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
在现代自然语言处理(NLP)领域,Transformer 模型的出现带来了革命性的变化。它极大地提升了语言模型的性能和效率,而自注意力机制是其中的核心组件。
今个儿我们将通过五个阶段,逐步深入讲解自注意力机制,帮助大侠一窥其原理和应用,成功实现变身(装 X )
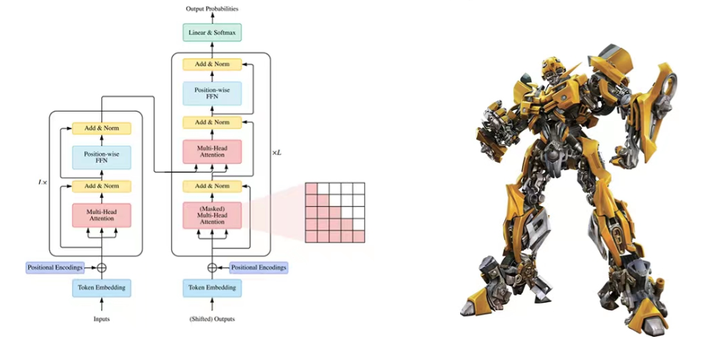
第一阶段:自注意力机制基础
在处理语言和文字时,我们经常需要理解一个句子中的单词是如何相互关联的。例如,在句子“猫追着老鼠跑”中,我们需要知道“猫”是追的主体,“老鼠”是被追的对象。传统的方法在理解这些关系时有一些困难,特别是当句子变得很长时。自注意力机制是一种新的方法,可以更好地理解句子中单词之间的关系,无论句子有多长。
自注意力机制的核心思想是:每个单词都能“注意到”句子中的其他单词,并根据这些单词来调整自己。这有点像我们在读一篇文章时,会注意到一些关键的词句来帮助我们理解文章的整体意思。
第二阶段:自注意力机制的工作原理
在自注意力机制中,每个单词会看向句子中的其他单词,并计算一个注意力得分。这些得分表示每个单词对其他单词的关注程度。这个过程可以理解为每个单词都在问自己:“我应该关注哪些单词?”
计算注意力得分
以句子“我喜欢吃苹果”为例:
- “我”计算它对“喜欢”、“吃”和“苹果”的注意力得分。
- 每个单词的得分会被转换成一个概率,表示它在句子中有多重要。
注意力得分会被一种叫做 softmax 的方法转换成概率。这种方法确保所有的得分加起来等于 1,这样我们就可以知道每个单词的重要性。例如:
- “我”可能对“喜欢”的关注度是 0.4,对“吃”的关注度是 0.3,对“苹果”的关注度是 0.3。
- 这些得分表示“我”最关注的是“喜欢”,其次是“吃”和“苹果”。
生成新表示
每个单词会根据这些概率得分,重新组合句子中的信息,生成新的表示。这就像我们在阅读一篇文章时,会根据每句话的重要性来总结文章的核心内容。
防失联,进免费知识星球,直达算法金 AI 实验室 https://t.zsxq.com/ckSu3
第三阶段:查询、键和值
在自注意力机制中,每个单词都被表示为三个向量:查询(Query)、键(Key)和值(Value)。这些向量帮助我们计算注意力得分,并生成新的单词表示。
查询(Query)
查询向量表示我们希望了解的单词。每个单词都有一个查询向量,用于计算它与其他单词的关系。
键(Key)
键向量表示句子中每个单词的特征。查询向量会与键向量进行对比,计算出注意力得分。
值(Value)
值向量表示句子中每个单词的具体内容。注意力得分会作用于值向量,以生成新的单词表示。
示例
以句子“我喜欢吃苹果”为例:
- “我”的查询向量会与“喜欢”、“吃”和“苹果”的键向量进行对比,计算出它们的注意力得分。
- 这些得分会用于加权“喜欢”、“吃”和“苹果”的值向量,生成“我”的新表示。
多头注意力机制
为了更好地捕捉句子中不同方面的信息,Transformer 引入了多头注意力机制。这个机制允许我们并行地计算多组查询、键和值向量,捕捉不同的关系。
多头注意力机制的步骤
- 分组:将查询、键和值向量分成多组,每组称为一个“头”。
- 独立计算:每个头独立计算注意力得分,并生成新的表示。
- 拼接与变换:将所有头的结果拼接起来,并通过一个线性变换生成最终的输出。
例子
假设我们有两个头:
- 第一头可能主要关注“我”和“喜欢”的关系。
- 第二头可能主要关注“吃”和“苹果”的关系。通过这种方式,多头注意力机制可以更全面地理解句子中的不同关系。
第四阶段:残差连接和层归一化
残差连接(Residual Connection)
残差连接是一种技术,它通过在网络层之间添加直接的跳跃连接,帮助缓解深度神经网络中的梯度消失问题。
原理
在每一层的输出中,我们会添加上这一层的输入。这可以用公式表示为:
其中,Layer() 表示这一层的计算结果, 是输入。
优点
- 缓解梯度消失问题:残差连接允许梯度直接通过跳跃连接传播,从而保持梯度不至于消失。
- 更快的训练速度:残差连接使得网络更容易训练,减少了训练时间。
示例
假设我们有一个句子“我喜欢吃苹果”,经过一层自注意力机制处理后,我们会将这一层的输出与原始输入相加,生成新的表示。这使得信息更好地在网络中传播。
层归一化(Layer Normalization)
层归一化是一种技术,它通过对每一层的输出进行归一化处理,帮助加速训练和提高模型稳定性。
原理
层归一化会对每一层的输出进行归一化处理,使得输出的均值为 0,方差为 1。这可以用公式表示为:

优点
- 提高训练速度:层归一化使得网络层的输出更为稳定,加快了训练速度。
- 提高模型稳定性:通过归一化处理,减少了网络层之间的数值波动,提高了模型的稳定性。
示例
在每一层的输出经过残差连接后,我们会对结果进行层归一化处理,使得输出更加稳定。例如,在句子“我喜欢吃苹果”中,每一层的输出经过层归一化处理后,可以更好地进行下一层的计算。
点击 ↑ 领取
防失联,进免费知识星球,直达算法金 AI 实验室
第五阶段:实际应用与高级优化
自注意力机制的实现
基本实现步骤
- 输入处理:将输入文本转换为向量表示,可以使用词嵌入(word embedding)技术。
- 计算查询、键和值:根据输入向量,计算每个单词的查询、键和值向量。
- 计算注意力得分:使用查询和键向量计算注意力得分,并通过 softmax 转换成概率。
- 加权求和:根据注意力得分,对值向量进行加权求和,生成新的表示。
- 多头注意力机制:并行计算多组查询、键和值向量,并将结果拼接起来。
- 残差连接和层归一化:在每一层的输出后,添加残差连接并进行层归一化处理。
代码示例
以下是一个简化的自注意力机制的实现示例:
import torch
import torch.nn.functional as F
class SelfAttention(torch.nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert self.head_dim * heads == embed_size, "Embedding size needs to be divisible by heads"
self.values = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = torch.nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.nn.functional.softmax(energy / (self.embed_size ** (1 / 2
)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)
out = self.fc_out(out)
return out
优化技巧
使用预训练模型
在实际应用中,可以使用预训练的 Transformer 模型,如 BERT、GPT 等,这些模型已经在大规模数据上进行过训练,能够大幅提升性能。
微调(Fine-tuning)
在特定任务上对预训练模型进行微调,即在预训练模型的基础上,使用少量的任务特定数据进行训练,以适应具体的应用场景。
正则化技术
为了防止模型过拟合,可以使用正则化技术,如 Dropout、权重衰减等。
实际应用案例
自然语言处理
自注意力机制广泛应用于自然语言处理任务,如机器翻译、文本生成、情感分析等。例如,Google 的翻译系统使用 Transformer 模型进行高效的翻译。
图像处理
自注意力机制也被应用于图像处理任务,如图像分类、目标检测等。Vision Transformer(ViT)是将 Transformer 应用于图像处理的成功案例。
[ 抱个拳,总个结 ]
在第五阶段中,我们探讨了自注意力机制在实际应用中的实现步骤,提供了代码示例,并介绍了一些高级优化技巧和实际应用案例。通过这些内容,大侠可以一窥 Transformer 的核心 - 自注意力机制的实际应用和优化方法。
至此,五个阶段的学习已经完成,希望这能帮助你全面理解自注意力机制,并在实际项目中成功应用。
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
算法金 | Transformer,一个神奇的算法模型!!的更多相关文章
- viterbi维特比算法和隐马尔可夫模型(HMM)
隐马尔可夫模型(HMM) 原文地址:http://www.cnblogs.com/jacklu/p/7753471.html 本文结合了王晓刚老师的ENGG 5202 Pattern Recognit ...
- sqrt函数实现(神奇的算法)
我们平时经常会有一些数据运算的操作,需要调用sqrt,exp,abs等函数,那么时候你有没有想过:这个些函数系统是如何实现的?就拿最常用的sqrt函数来说吧,系统怎么来实现这个经常调用的函数呢? 虽然 ...
- 机器学习算法(九): 基于线性判别模型的LDA手写数字分类识别
1.机器学习算法(九): 基于线性判别模型的LDA手写数字分类识别 1.1 LDA算法简介和应用 线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用.LDA是一种 ...
- ZeroMQ接口函数之 :zmq_z85_decode – 从一个用Z85算法生成的文本中解析出二进制密码
ZeroMQ 官方地址 :http://api.zeromq.org/4-0:zmq_z85_decode zmq_z85_decode(3) ØMQ Manual - ØMQ/4.1 ...
- C#算法之判断一个字符串是否是对称字符串
记得曾经一次面试时,面试官给我电脑,让我现场写个算法,判断一个字符串是不是对称字符串.我当时用了几分钟写了一个很简单的代码. 这里说的对称字符串是指字符串的左边和右边字符顺序相反,如"abb ...
- 一个UUID生成算法的C语言实现 --- WIN32版本 .
一个UUID生成算法的C语言实现——WIN32版本 cheungmine 2007-9-16 根据定义,UUID(Universally Unique IDentifier,也称GUID)在时 ...
- 一个由IsPrime算法引发的细节问题
//******************************* // // 2014年9月18日星期四,于宿舍撰写 // 作者:夏华林 // //******************* ...
- 一个简单的算法,定义一个长度为n的数组,随机顺序存储1至n的的全部正整数,不重复。
前些天看到.net笔试习题集上的一道小题,要求将1至100内的正整数随机填充到一个长度为100的数组,求一个简单的算法. 今天有空写了一下.代码如下,注释比较详细: using System; usi ...
- 手动实现一个虚拟DOM算法
发现一个好文:<深度剖析:如何实现一个 Virtual DOM 算法> 源码 文章写得非常详细,仔细看了一遍代码,加了一些注释.其实还有有一些地方看的不是很懂(毕竟我菜qaq 先码 有时间 ...
- 算法:输入一个链表,输出该链表中倒数第k个结点。
算法:输入一个链表,输出该链表中倒数第k个结点.<剑指offer> 思路加到注释里面了: 1:两个if判断是否返回值为空,首个为空,没有第k个值: 2:for循环找到倒数第k个值,返回为a ...
随机推荐
- rpc 和 http的区别
- Go类型断言demo
Go类型断言demo package main import ( "bytes" "encoding/json" "fmt" "i ...
- WebKit中WTFMove实现
WTFMove定义位置: WTF/Source/wtf/StdLibExtras.h,其定义如下: #define WTFMove(value) std::move<WTF::CheckMove ...
- ansible(10)--ansible的systemd模块
1. systemd模块 功能:管理服务启动与停止,与 service 模块用法一致: 主要参数如下: 参数 说明 name 指定需要控制的服务名称 state 指定服务状态,其值可以为stopped ...
- Spring环境获取Spring的Bean
一.测试数据准备 /* Navicat Premium Data Transfer Source Server : swp-mysql Source Server Type : MySQL Sourc ...
- 推荐几款火爆的Python在线编辑器
在当今数字化时代,编程已成为一项不可或缺的技能.Python作为一种简单易学且功能强大的编程语言,受到了广大编程爱好者和专业开发人员的青睐.为了方便大家随时随地编写和运行Python代码,市面上涌现了 ...
- Chrome 插件 V3 版本 Manifest.json 中的内容脚本(Content Scripts)解析
内容脚本(Content Scripts) 指定在用户打开某些网页时要使用的 JavaScript 或 CSS 文件. 内容脚本是在网页环境中运行的文件.通过使用标准文档对象模型 (DOM),开发者能 ...
- CodePen 的国内替代「笔.COOL」,一个功能完备、使用便捷的在线HTML/CSS/JS编辑器和作品分享平台
笔.COOL,是一个最近在国内崭露头角的在线HTML/CSS/JS编辑器和作品分享平台. 笔.COOL 提供了一个在线的 HTML.CSS 和 JavaScript 代码编辑器.无需任何安装,你只需打 ...
- 前端如何对cookie加密
在前端对 Cookie 进行加密时,你可以使用加密算法对 Cookie 的值进行加密,然后再将加密后的值存储到 Cookie 中.常用的加密算法包括对称加密算法(如 AES)和非对称加密算法(如 RS ...
- 数据结构(C++)--学习单链表时发现的一些小坑
基于类的链表类无相应构造函数报错 #include<bits/stdc++.h> using namespace std; const int MaxSize = 10; template ...