使用Databricks进行零售业需求预测的应用实践
简介:本文从零售业需求预测痛点、商店商品模型预测的实践演示,介绍Databricks如何助力零售商进行需求、库存预测,实现成本把控和营收增长。
作者:李锦桂 阿里云开源大数据平台开发工程师
本文从零售业需求预测痛点、商店商品模型预测的实践演示,介绍Databricks如何助力零售商进行需求、库存预测,实现成本把控和营收增长。
本文分为以下四部分:
1.消费者需求预测对零售业的重要性
2.数据的准备与可视化
3.基于DDI建立预测单个商店-商品模型
4.将预测模型扩展到每个商店-商品的预测
一、消费者需求预测对零售业的重要性
首先,需求预测对零售商至关重要。如果商店的商品过多,货架和仓库的空间紧张,产品容易过期,财务资源被库存束缚。零售商无法利用制造商带来的新机会,从而错过消费模式的转变。
由于商店内商品过少,客户无法从上商店内买到需要的商品。不但会造成零售商的收入损失,而且随着时间的推移,消费者的失望情绪,会驱使消费者转向竞争对手。
综上所述,预测消费者需求的准确性和及时性,对零售商非常重要。
二、数据的准备与可视化
下面我们使用零售数据模拟如何使用DDI的notebook和Facebook prophet来对消费者的需求进行建模和预测。
现在我们需要的数据已经上传到了OSS的Bucket里面,接下来,开始对消费者的需求进行建模和预测。当数据上传到OSS上之后,可以在DDI的Notebook上对数据进行分析和建模。
本次使用的数据集是2012年到2017年,10个商店中的50商品销售数据。数据包含四列。第一列是日期;第二列是商店的ID(1-10);第三列是商品的ID(1-50);第四列是当日商品的销售量。
实验目的是预测未来三个月,这些商品在各个商店的销量,对商店未来的库存备货提供指导。
在默认配置下,YARN分配的executor CPU为1core,memory为2G,为了让我们的分析更快一些,我们可以适度调高分配的cpu核心数和分配的内存大小。
通常,在读取大量CSV格式的数据之前,会预先定义Schema。这项简单预处理,可以免去Spark自动推测数据类型的繁重工作,让Spark更加快速的读入数据。

定义Schema之后,将训练数据读取到spark的DataFrame中。
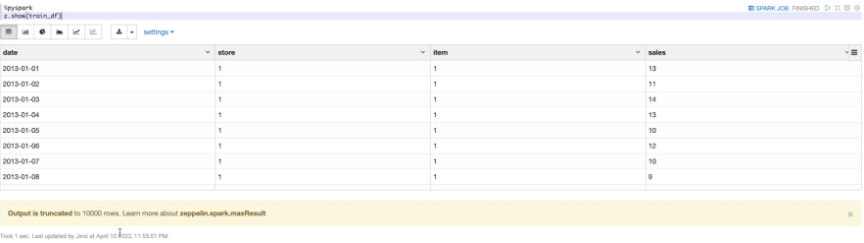
读取DataFrame之后,通过熟悉的SQL语句对数据进行分析,可以使用dataframe的createOrReplaceTempView方法,创建一个临时的视图。
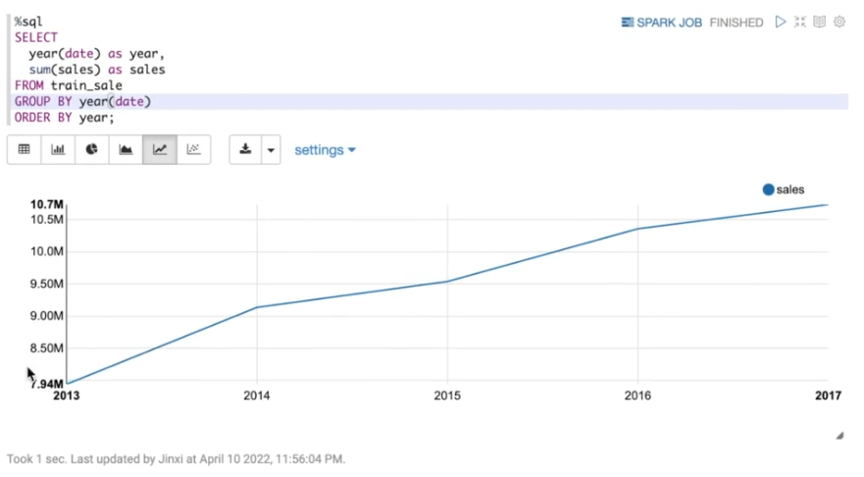
创建view之后,对dataframe中的数据进行分析。首先分析销售数据随年份的走势。从图表可以看出,在过去几年,商店的销售额稳步增长,总体呈现线性增长的趋势。在预测下一年的销售额时,可以参考过去几年的增长率。
三、基于DDI建立预测单个商店-商品模型
与此同时,商品销售往往有很强的季节性,特别是服装行业。T恤在夏季的销售额肯定高于羽绒服的销售额。因此,在预测商品的销售额时,季节性是不可忽略的因素。
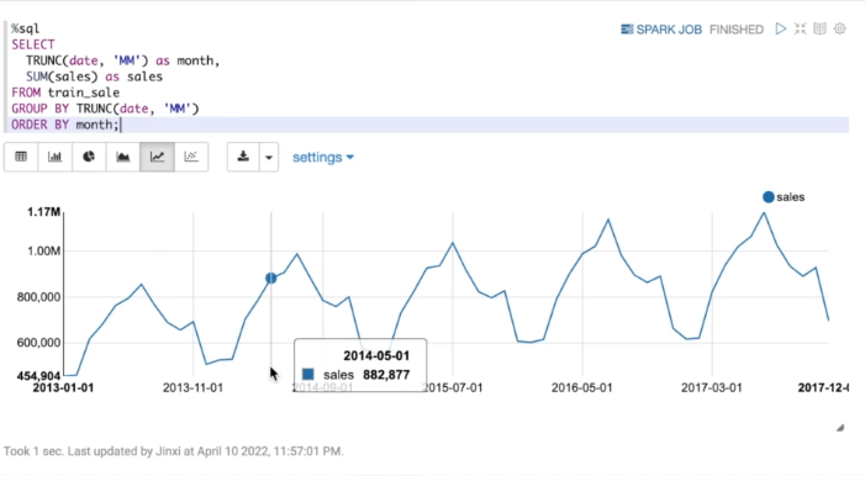
如上图所示,从2013年到2017年,商品销量不断上涨。一年之中,商品的销售额呈现很强的周期性。
在12月或1月时,商品销量到达波谷,随着月份不断攀升,7月销量到达波峰。所以在进行建模时,月份是很重要的特征之一。
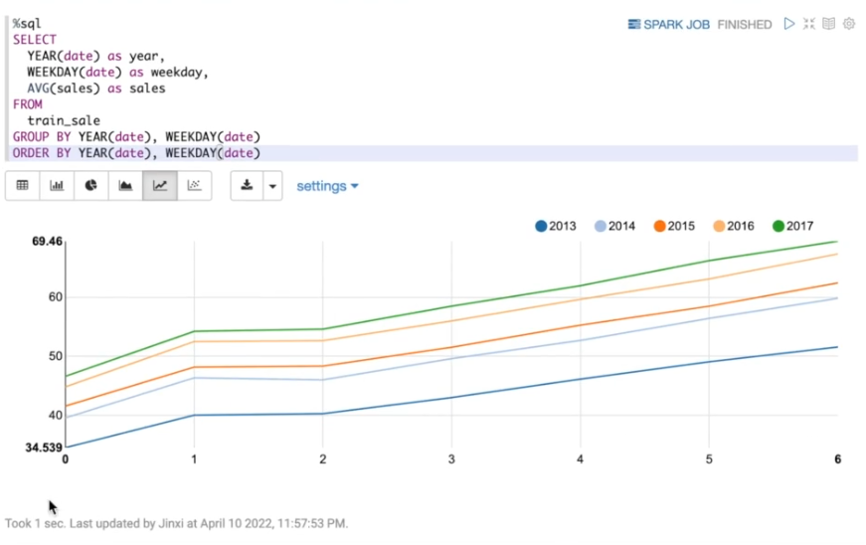
在上图中,0代表的周一,1代表周二……销售额在每周七天,也呈现出很强的周期性,在周日的销售额达到最高,周一跌到最低,然后慢慢回到高位。
Prophet是facebook开源的一个时间序列预测算法。Prophet的使用非常简单,只需要输入已知的时间序列的时间戳和相应的值以及需要预测的时间序列的长度,Prophet就能输出未来的时间序列走势。
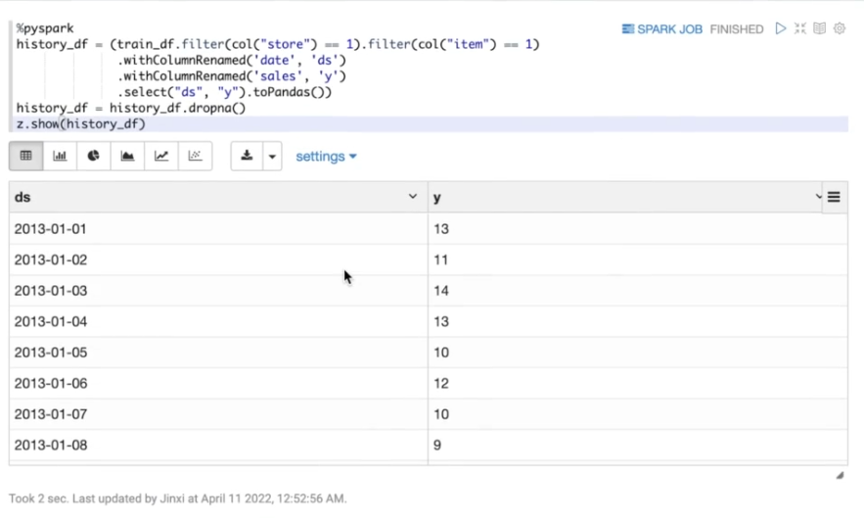
接下来,对所有商店和商品的组合进行预测之前。先选择store 1和item 1进行预测,熟悉Prophet的使用。

预测第一步,组装历史数据用于模型训练。Prophet的模型比较简单,相当于Prophet的对象。在这个对象里,把growth定义为线性。

在数据探索阶段,得到的结论是,一个商品的销量,不但有周与周之间的周期性,而且有月份之间的周期性。所以weekly,yearly作为true。然后使用fit方法,对模型进行训练。
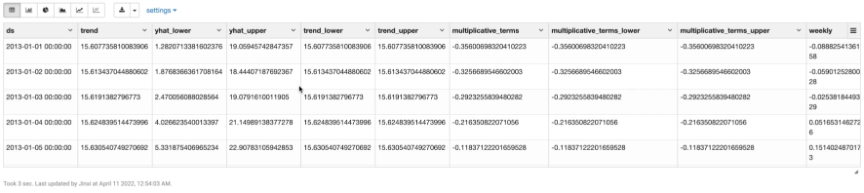
训练之后,可以使用这个模型预测未来90天的走势。
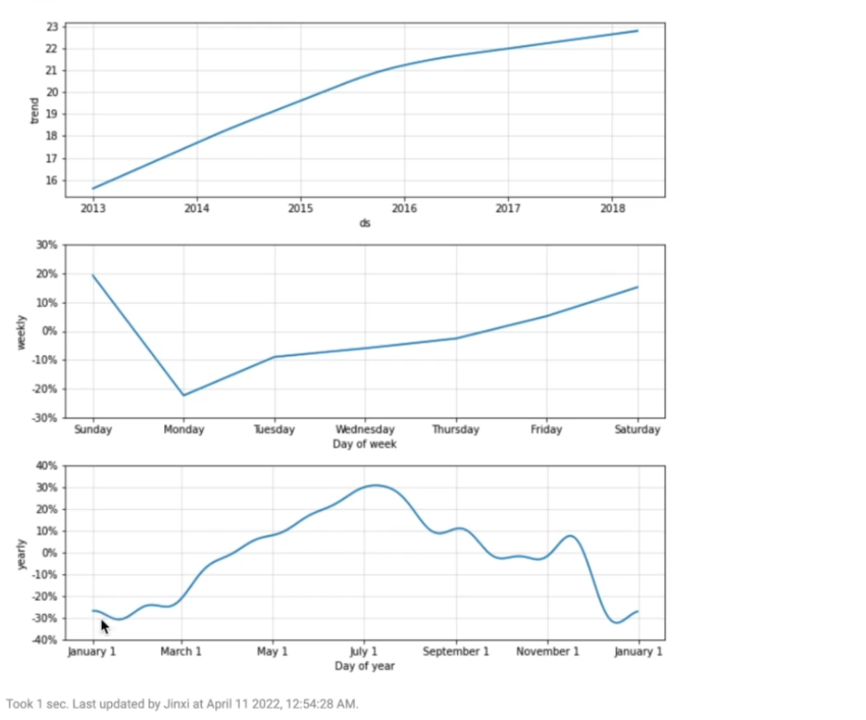
从上图可以看到,商品整体销量呈逐年增加的趋势。商品销量受季节和节假日变化影响显著。
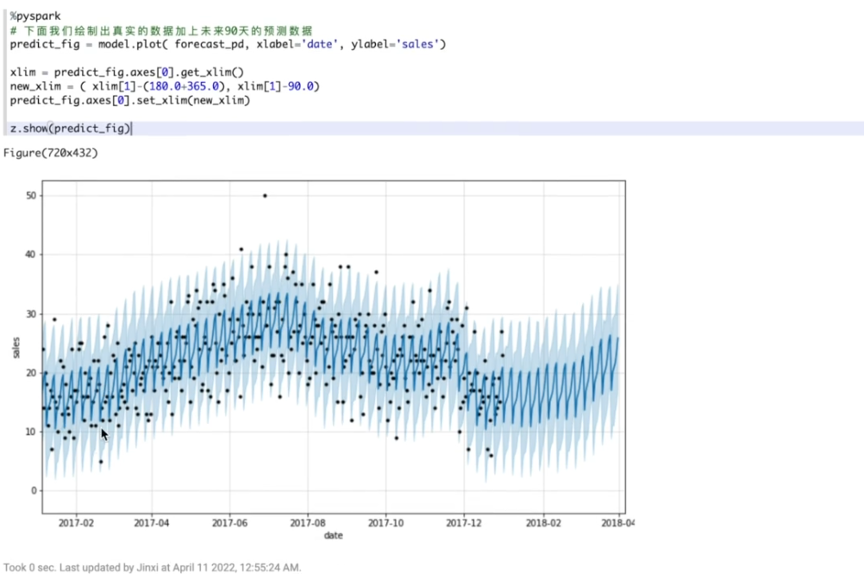
最后,把真实数据和未来90天的预测数据它拼接到一起。真实数据从2017年到2018年的1月。未来90天的预测数据,从2018年1月到4月。如上图所示,带有黑点的数据是真实数据。
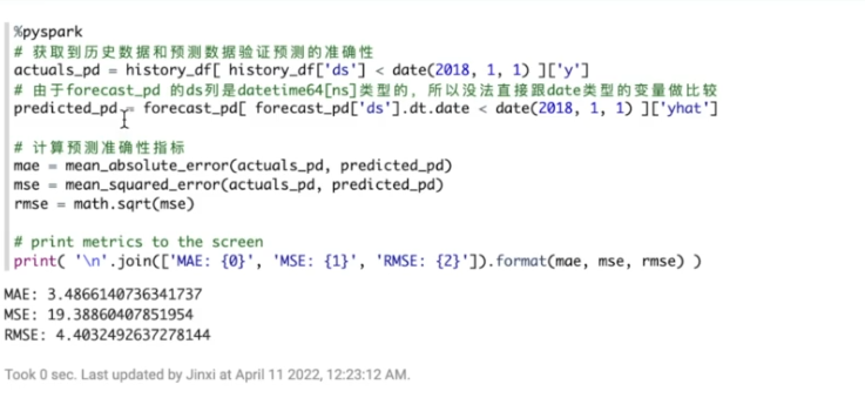
通过获取历史数据和预测数据的准确性。可以预测一些准确性指标,比如MAE、MSE和RMSE。
四、将预测模型扩展到每个商店-商品的预测
接下来,开始建立更加完善的模型对商店(10个商店)和商品(50件商品)的所有组合进行预测。建立模型的第一步是准备数据。
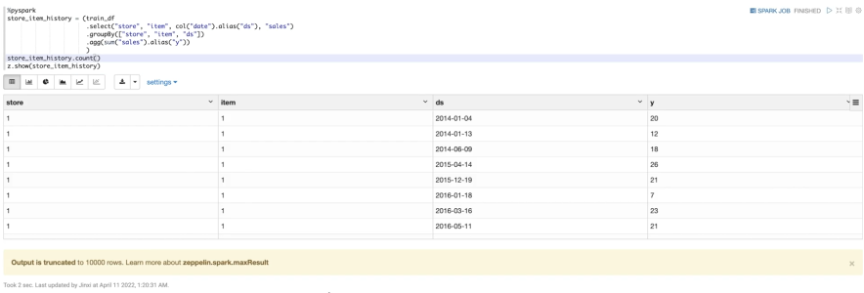
训练数据主要有四列。对应的是每一种商店商品的组合,在特定日期的销量。然后,针对这些数据进行建模。

创建一个Prophet对象,建立模型。weekly和yearly被设为true,然后预测未来90天的趋势。
从预测数据中,抽取出一些需要的字段和历史数据。将历史数据和预测数据拼接到一起,设置结果数据中的商店ID和商品ID,返回数据集。将模型训练应用到每个商店和商品组合,将预测结果写入OSS。
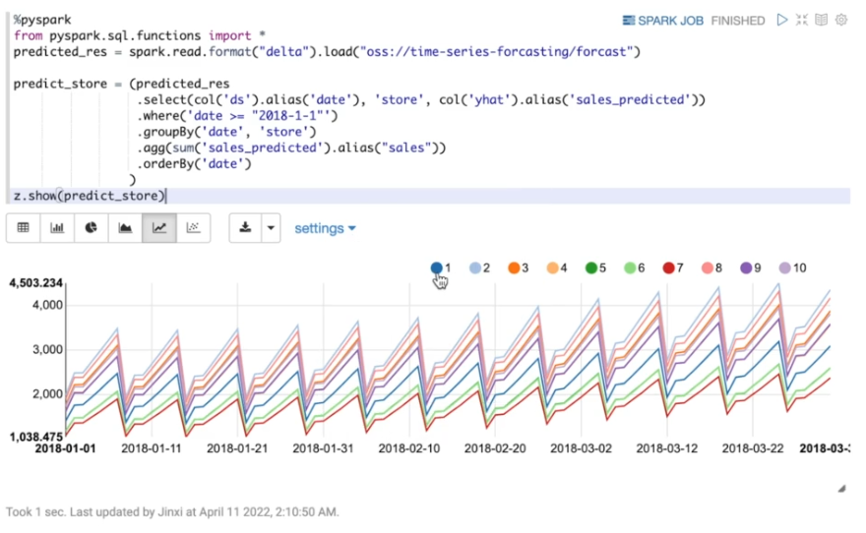
接下来,把OSS中的预测结果,加载到spark里。选择时间戳,商店和的预测值。选择日期应大于2018年1月1号。根据时间和商店组合。预测的商店销售额,如上图所示。

接下来,开始计算每个模型的测试指标。首先,定义一个UDF用于计算模型的测试指标。获取训练日期,计算训练指标,进行组装。
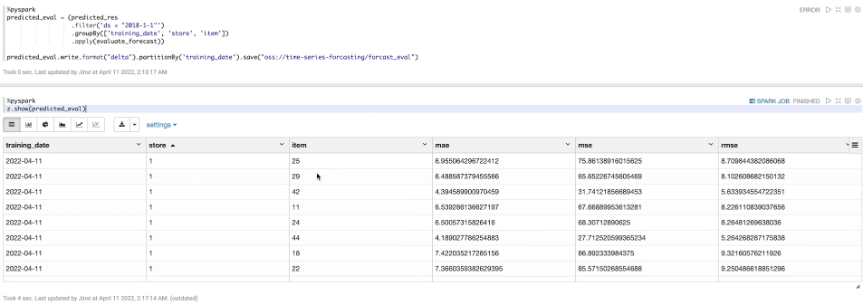
上图是针对10家商店的50种商品形成的预测结果。最终完成了每个商店和商品的组合,以及销售额的模型建立与预测。
本文为阿里云原创内容,未经允许不得转载。
使用Databricks进行零售业需求预测的应用实践的更多相关文章
- StartDT AI Lab | 需求预测引擎如何助力线下零售业降本增效?
在当下经济明显进入存量博弈的阶段,大到各经济体,小到企业,粗放的增长模式已不适宜持续,以往高增长的时代已经成为过去,亟需通过变革发掘新的增长点.对于竞争激烈的线下零售行业而言,则更需如此. 零售行业一 ...
- BI案例:BI在连锁零售业应用(ZT)【转】
第一部分:连锁零售企业上BI的必要性. 目前国内的连锁零售行业的发展趋势,呈现出产业规模化,经营业态多样化,管理精细化的特点.所谓管理精细化就是"精耕细作搞管理,领先一步订系 统" ...
- BI案例:BI在连锁零售业应用(ZT)
第一部分:连锁零售企业上BI的必要性. 目前国内的连锁零售行业的发展趋势,呈现出产业规模化,经营业态多样化,管理精细化的特点.所谓管理精细化就是"精耕细作搞管理,领先一步订系统". ...
- BI在连锁零售业应用
BI案例:BI在连锁零售业应用(ZT) Posted on 2015-08-25 09:31 xuzhengzhu 阅读(42) 评论(0) 编辑 收藏 第一部分:连锁零售企业上BI的必要性. 目前国 ...
- 利用BI搭建零售业数据信息平台
某百货公司是全市规模最大的以零售为主.多元化经营的股份制商业企业.拥有员工数千人,经营国内外品牌2300余种,年商品销售额逾10亿人元. 销售体量如此庞大的企业近几年在IT建设上出现了问题,集团内部的 ...
- odoo:开源 ERP/CRM 入门与实践
看了这张图,或许你对odoo有了一些兴趣. 这次就是和大家一起交流开源ERP/CRM系统:odoo 对以下读者有帮助:研发.产品.项目.市场.服务.运营.管理等. 一.背景趋势 社交网络.电商O2O: ...
- GC调优在Spark应用中的实践(转载)
Spark是时下非常热门的大数据计算框架,以其卓越的性能优势.独特的架构.易用的用户接口和丰富的分析计算库,正在工业界获得越来越广泛的应用.与Hadoop.HBase生态圈的众多项目一样,Spark的 ...
- odoo:开源 ERP/CRM 入门与实践 -- 上海嘉冰信息技术公司提供咨询服务
odoo:开源 ERP/CRM 入门与实践 看了这张图,或许你对odoo有了一些兴趣. 这次Chat就是和大家一起交流开源ERP/CRM系统:odoo 对以下读者有帮助:研发.产品.项目.市场.服务. ...
- 虎牙直播运维负责人张观石 | SRE实践指南
虎牙直播运维负责人张观石 本文是根据虎牙直播运维负责人张观石10月20日在msup携手魅族.Flyme.百度云主办的第十三期魅族开放日<虎牙直播平台SRE实践>演讲中的分享内容整理而成. ...
- 京东无人超市的成长之路 如何利用AI技术在零售业做产品创新?
随着消费及用户体验的需求升级.人货场的运营效率需求提升.人工智能技术的突破以及零售基础设施的变革等因素共同推动了第四次零售革命的到来,不仅在国内,国外一线巨头互联网亚马逊等企业都在研发无人驾驶.无人超 ...
随机推荐
- Kotlin 语法糖(对象不为空返回自身,为空返回其他)
原文地址: Kotlin 语法糖(对象不为空返回自身,为空返回其他) - Stars-One的杂货小窝 开发中,经常会有这样逻辑: 判断对象如果不为空,则取对象本身; 为空,则得到其他对象; 然后每次 ...
- Java Spring Redis 如何向Set中添加List?
调用list.toArray方法将list转成数组,再使用add方法参数传入数组,即可批量添加. redisTemplate.opsForSet().add(key,collect.toArray(n ...
- Leetcode 2157 字符串分组
广度搜索+哈希表+状态转换 贴代码: import java.util.HashMap; import java.util.HashSet; import java.util.LinkedList; ...
- 浅析三维模型3DTile格式轻量化处理常见问题与处理措施
浅析三维模型3DTile格式轻量化处理常见问题与处理措施 三维模型3DTile格式的轻量化处理是大规模三维地理空间数据可视化的关键环节,但在实际操作过程中,往往会遇到一些问题.下面我们来看一下这些常见 ...
- 【LeetCode刷题】239.滑动窗口最大值
239.滑动窗口最大值(点击跳转LeetCode) 给你一个整数数组nums,有一个大小为k的滑动窗口从数组的最左侧移动到数组的最右侧.你只可以看到在滑动窗口内的k个数字.滑动窗口每次只向右移动一位. ...
- 鸿蒙HarmonyOS实战-ArkTS语言(状态管理)
前言 状态管理是指在应用程序中维护和更新应用程序状态的过程.在一个程序中,可能有很多不同的组件和模块,它们需要共享和相互作用的状态.如果没有一个明确的方式来管理这些状态,就会导致代码混乱.不易维护和难 ...
- 使用JMeter从JSON响应的URL参数中提取特定值
在使用Apache JMeter进行API测试时,我们经常需要从JSON格式的响应中提取特定字段的值.这可以通过使用JMeter内置的JSON提取器和正则表达式提取器来完成.以下是一个具体的例子,展示 ...
- KingbaseES 执行计划常见节点介绍
KingbaseES中explain命令来查看执行计划时最常用的方式.其命令格式如下: explain [option] statement 其中option为可选项,常用的是以下5种情况的组合: a ...
- 应对 DevOps 中的技术债务:创新与稳定性的微妙平衡
技术性债务在DevOps到底意味着什么?从本质上讲,这是小的开发缺陷的积累,需要不断地返工.它可能由多种原因引起,例如快速交付新功能的压力,这可能会导致团队不得不牺牲代码的整洁和完善.但这些不完整的小 ...
- #二进制拆分,矩阵乘法#洛谷 6569 [NOI Online #3 提高组] 魔法值
题目 分析 考虑一个点的权值能被统计到答案当且仅当其到1号点的路径条数为奇数条. 那么设 \(dp[i][x][y]\) 表示从 \(x\) 到 \(y\) 走 \(i\) 步路径条数的奇偶性, 这个 ...