Kafka源码分析(四) - Server端-请求处理框架
系列文章目录
https://zhuanlan.zhihu.com/p/367683572
一. 总体结构
先给一张概览图:
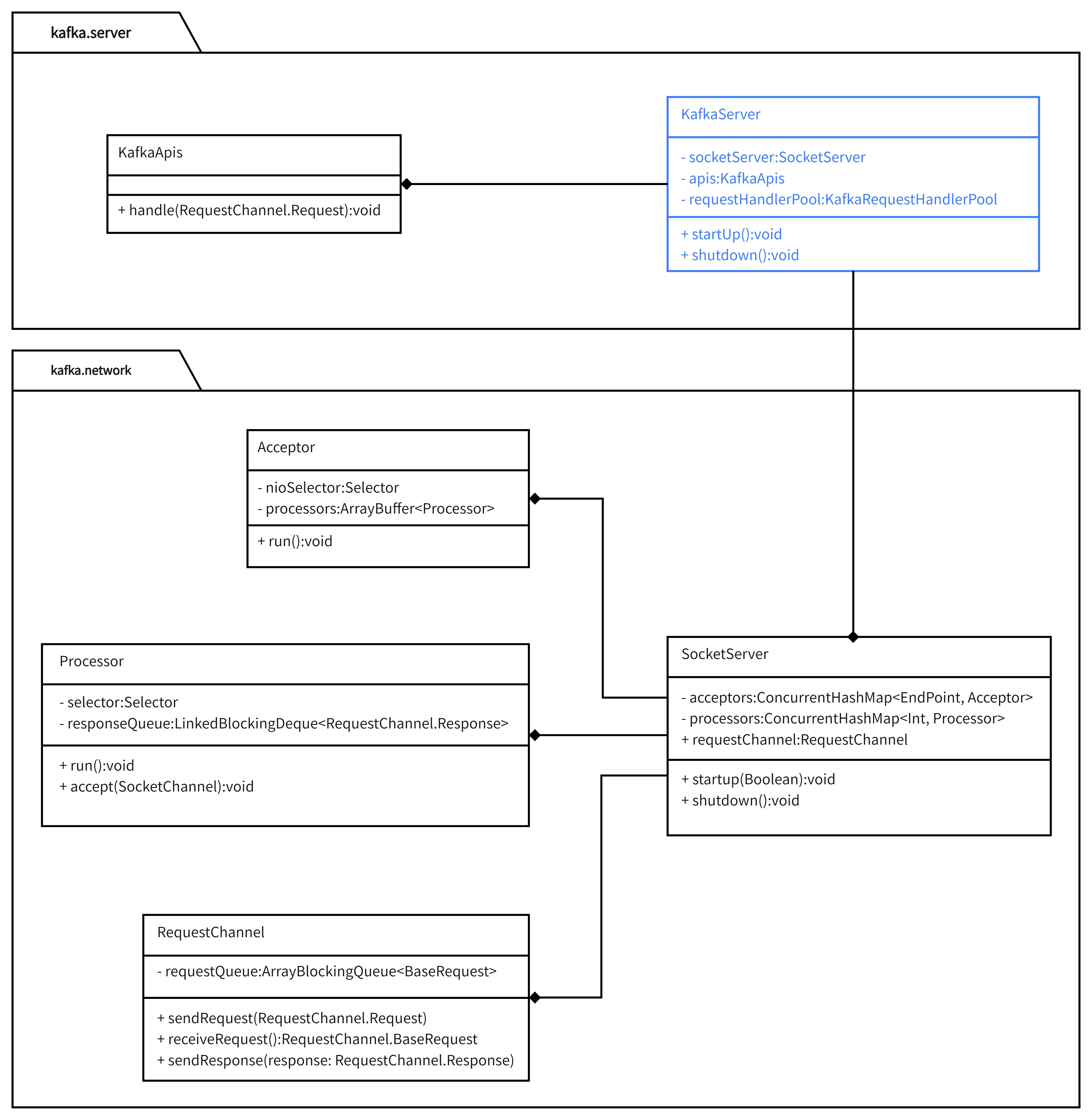
服务端请求处理过程涉及到两个模块:kafka.network和kafka.server。
1.1 kafka.network
该包是kafka底层模块,提供了服务端NIO通信能力基础。
有4个核心类:SocketServer、Acceptor、Processor、RequestChannel。各自角色如下:
SocketServer:服务端的抽象,是服务端通信的入口;
Acceptor:Reactor通信模式中处理连接ACCEPT事件的线程/线程池所执行的任务;
Processor:Reactor通信模式中处理连接可读/可写事件的线程/线程池所执行的任务;
RequestChannel:请求队列,存储已经解析好的请求以等待处理;
对于上层模块而言,该基础模块有两个输入和一个输出
输入:IP+端口号,该模块会对目标端口实现监听;
输出:解析好的请求,通过RequestChannel进行输出;
输入:待发送的Response,通过Processor.responseQueue来完成输入;
1.2 kafka.server
该包在kafka.network的基础上实现各种请求的处理逻辑,主要包含KafkaServer和KafkaApis两个类。其中:
KafkaServer:Kafka服务端的抽象,统一维护Kafka服务端的各流程和状态;
KakfaApis:维护了各类请求对应的业务逻辑,通过KafkaServer.apis字段组合到KafkaServer之中;
二. Server的端口监听
整体流程如图:
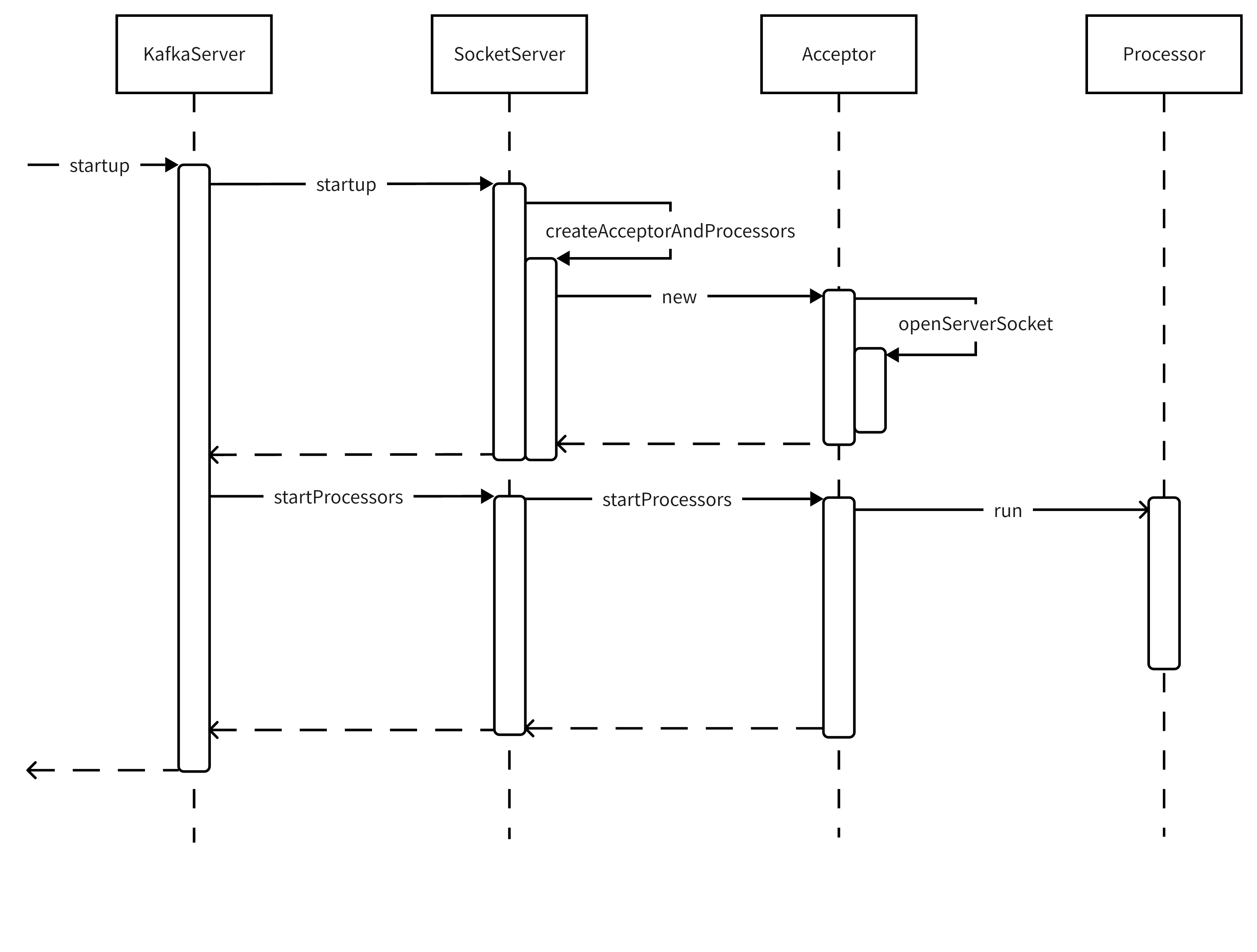
接下来按调用顺序依次分析各方法
2.1 KafkaServer.startup()
关于端口监听的核心逻辑分4步,代码如下(用注释说明各部分的目的):
def startup() {
// 省略无关代码
... ...
// 1. 创建SocketServer
socketServer = new SocketServer(config, metrics, time, credentialProvider)
// 2. 启动端口监听
// (在这里完成了Acceptor的创建和端口ACCEPT事件的监听)
// (startupProcessors = false表示暂不启动Processor处理线程)
socketServer.startup(startupProcessors = false)
// 3. 启动请求处理过程中的相关依赖
// (这也是第2步中不启动Processor处理线程的原因,有依赖项需要处理)
... ...
// 4. 启动端口可读/可写事件处理线程(即Processor线程)
socketServer.startProcessors()
// 省略无关代码
... ...
}
2.2 SocketServer.startup(Boolean)
代码及说明性注释如下:
def startup(startupProcessors: Boolean = true) {
this.synchronized {
// 省略无关代码
... ...
// 1. 创建Accetpor和Processor的实例,
// 同时页完成了Acceptor对端口ACCEPT事件的监听
createAcceptorAndProcessors(config.numNetworkThreads, config.listeners)
// 2. [可选]启动各Acceptor对应的Processor线程
if (startupProcessors) {
startProcessors()
}
}
}
2.3 ScocketServer.createAcceptorAndProcessor()
直接上注释版的代码,流程分3步:
// 入参解释
// processorsPerListener: 对于每个IP:Port, 指定Reactor模式子线程池大小,
// 即处理端口可读/可写事件的线程数(Processor线程);
// endpoints: 接收请求的IP:Port列表;
def createAcceptorAndProcessors(processorsPerListener: Int,
endpoints: Seq[EndPoint]): Unit = synchronized {
// 省略无关代码
... ...
endpoints.foreach { endpoint =>
// 省略无关代码
... ...
// 1. 创建Acceptor对象
// 在此步骤中调用Acceptor.openServerSocket, 完成了对端口ACCEPT事件的监听
val acceptor = new Acceptor(endpoint, sendBufferSize, recvBufferSize, brokerId, connectionQuotas)
// 2. 创建了与acceptor对应的Processor对象列表
// (这里并未真正启动Processor线程)
addProcessors(acceptor, endpoint, processorsPerListener)
// 3. 启动Acceptor线程
KafkaThread.nonDaemon(s"kafka-socket-acceptor-$listenerName-$securityProtocol-${endpoint.port}", acceptor).start()
// 省略无关代码
... ...
}
}
2.4 Acceptor.openServerSocket()
该方法中没什么特殊点,就是java NIO的标准流程:
def openServerSocket(host: String, port: Int): ServerSocketChannel = {
// 1. 构建InetSocketAddress对象
val socketAddress =
if (host == null || host.trim.isEmpty)
new InetSocketAddress(port)
else
new InetSocketAddress(host, port)
// 2. 构建ServerSocketChannel对象, 并设置必要参数值
val serverChannel = ServerSocketChannel.open()
serverChannel.configureBlocking(false)
if (recvBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
serverChannel.socket().setReceiveBufferSize(recvBufferSize)
// 3. 端口绑定, 实现事件监听
try {
serverChannel.socket.bind(socketAddress)
info("Awaiting socket connections on %s:%d.".format(socketAddress.getHostString, serverChannel.socket.getLocalPort))
} catch {
case e: SocketException =>
throw new KafkaException("Socket server failed to bind to %s:%d: %s.".format(socketAddress.getHostString, port, e.getMessage), e)
}
// 4. 返回ServerSocketChannel对象, 用于后续register到Selector中
serverChannel
}
2.5 SocketServer.startProcessor()
从这步开始,仅剩的工作就是启动Processor线程,代码都非常简单。比如本方法只是遍历Acceptor列表,并调用Acceptor.startProcessors()
def startProcessors(): Unit = synchronized {
acceptors.values.asScala.foreach { _.startProcessors() }
info(s"Started processors for ${acceptors.size} acceptors")
}
2.6 Acceptor.startProcessors()
该方法很简明,直接上代码
def startProcessors(): Unit = synchronized {
if (!processorsStarted.getAndSet(true)) {
startProcessors(processors)
}
}
def startProcessors(processors: Seq[Processor]): Unit = synchronized {
processors.foreach { processor =>
KafkaThread.nonDaemon(s"kafka-network-thread-$brokerId-${endPoint.listenerName}-${endPoint.securityProtocol}-${processor.id}",
processor).start()
}
}
三. 请求/响应的格式
3.1 格式概述
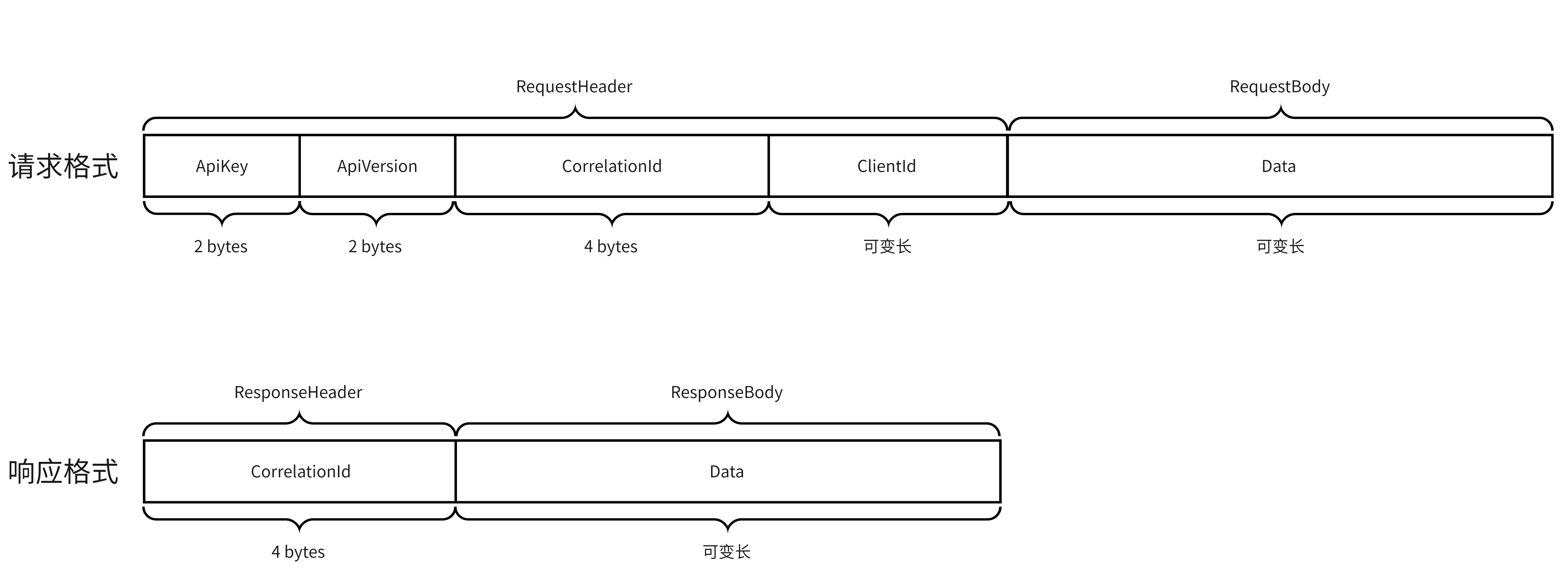
请求和响应都由两部分组成:Header和Body。RequestHeader中包含ApiKey、ApiVersion、CorrelationId、ClientId;ResponseHeader中只包含CorrelationId字段。接下来逐个讲解这些字段。
ApiKey
2字节整型,指明请求的类型;比如0代表Produce请求,1代表Fetch请求;具体id和请求类型之间的映射关系可在 org.apache.kafka.common.protocol.ApiKeys 中找到;
ApiVersion
随着API的升级迭代,各类型请求的请求体格式可能有变更;这个2字节的整型指明了请求体结构的版本;
CorrelationId
4字节整型,在Response中传回,Kafka Server端不处理,用于客户端内部关联业务数据;
ClientId
可变长字符串,标识客户端;
3.2 请求体/响应体的具体格式
各业务操作(比如Produce、Fetch等)对应的请求体和响应体格式都维护在 org.apache.kafka.common.protocol.ApiKeys 中。接下来以Produce为例讲解ApiKeys是如何表达数据格式的。
ApiKeys是个枚举类,其核心属性如下:
public enum ApiKeys {
// 省略部分代码
... ...
// 上文提到的请求类型对应的id
public final short id;
// 业务操作名称
public final String name;
// 各版本请求体格式
public final Schema[] requestSchemas;
// 各版本响应体格式
public final Schema[] responseSchemas;
// 省略部分代码
... ...
}
其中PRODUCE枚举项的定义如下
PRODUCE(0, "Produce", ProduceRequest.schemaVersions(), ProduceResponse.schemaVersions())
可以看到各版本的请求格式维护在 ProduceRequest.schemaVersions(),代码如下
public static Schema[] schemaVersions() {
return new Schema[] {PRODUCE_REQUEST_V0, PRODUCE_REQUEST_V1, PRODUCE_REQUEST_V2, PRODUCE_REQUEST_V3,
PRODUCE_REQUEST_V4, PRODUCE_REQUEST_V5, PRODUCE_REQUEST_V6};
}
这里只是简单返回了一个Schema数组。一个Schema对象代表了一种数据格式。请求头中的ApiVersion指明了请求体的格式对应数组的第几项(从0开始)。
接下来我们看看Schema是如何表达数据格式的。其结构如下

Schema有两个字段:fields和fieldsByName。其中fields是体现数据格式的关键,它指明了字段的排序和各字段类型;而fieldsByName只是按字段名重新组织的Map,用于根据名称查找对应字段。
BoundField只是Field的简单封装。Field有两个核心字段:name和type。其中name表示字段名称,type表示字段类型。常见的Type如下:
Type.BOOLEAN;
Type.INT8;
Type.INT16;
Type.INT32;
// 可通过org.apache.kafka.common.protocol.types.Type查看全部类型
... ...
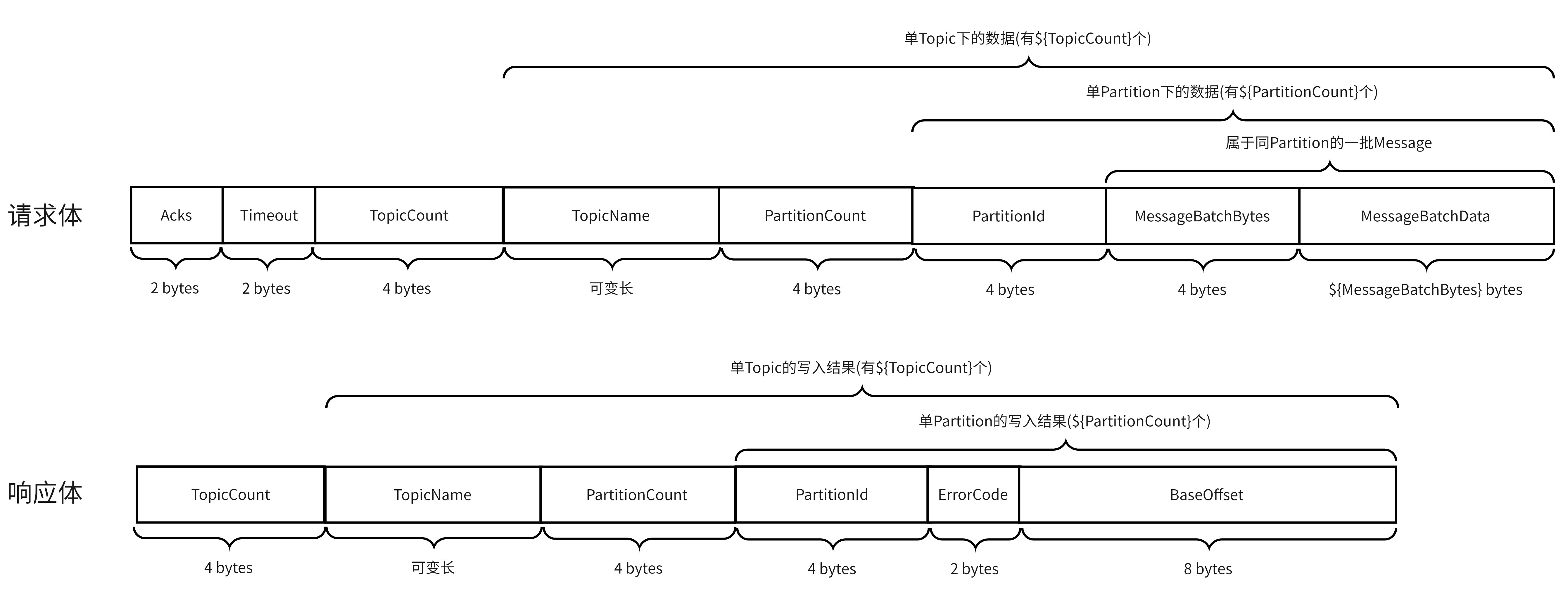
回到PRODUCE API,通过查看Schema的定义,能看到其V0版本的请求体和响应体的结构如下:
四. 请求的处理流程
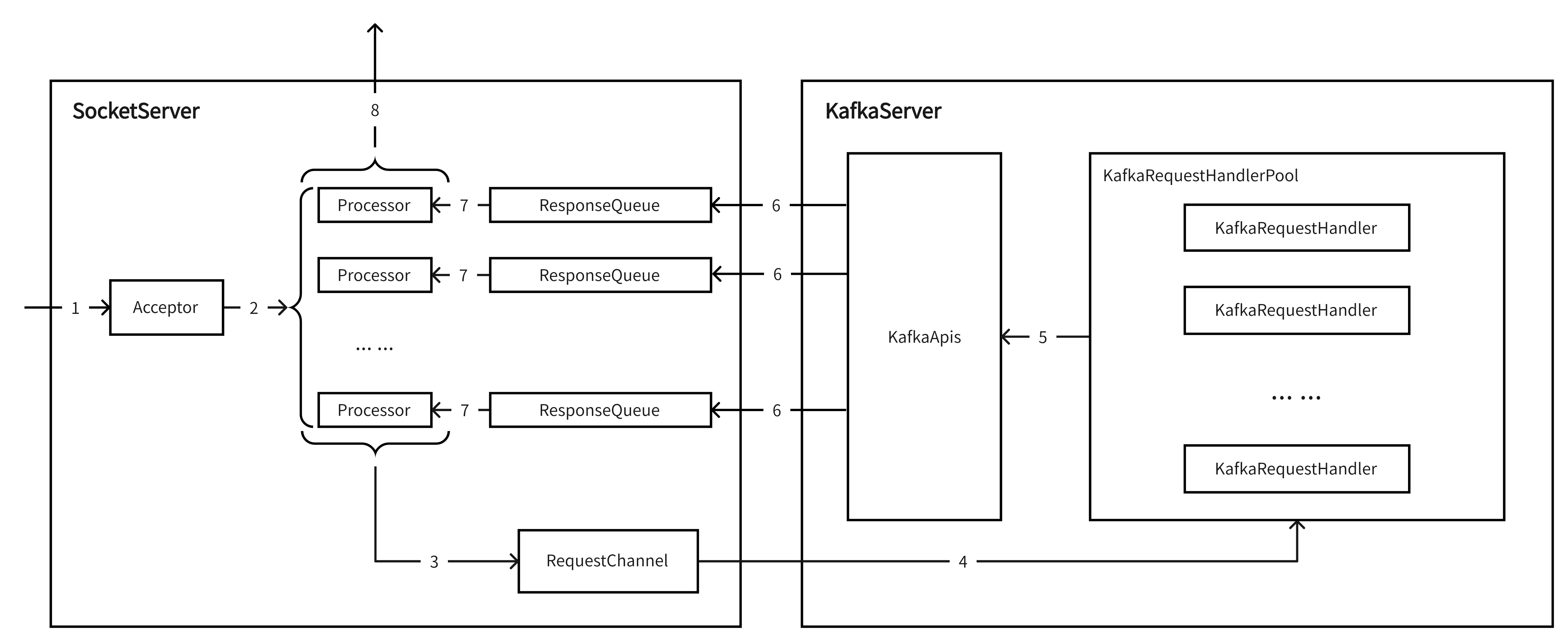
Acceptor监听到ACCEPT事件(TCP创建连接"第一次握手"的SYN);
Acceptor将将连接注册到Processor列表内的其中一个,由该Processor监听这个连接的后续可读可写事件;
Processor接收到完整请求后,会将Request追加到RequestChannel中进行排队,等待后续处理;
KafkaServer中有个requestHandlerPool的字段,KafkaRequestHandlerPool类型,代表请求处理线程池;KafkaRequestHandler就是其中的线程,会从RequestChannel拉请求进行处理;
KafkaRequestHandler将拉到的Request传入KafkaApis.handle(Request)方法进行处理;
KafkaApis根据不同的ApiKey调用不同的方法进行处理,处理完毕后会将Response最终写入对应的Processor的ResponseQueue中等待发送;KafkaApis.handle(Request)的方法结构如下:
def handle(request: RequestChannel.Request) {
try {
// 省略部分代码
... ...
request.header.apiKey match {
case ApiKeys.PRODUCE => handleProduceRequest(request)
case ApiKeys.FETCH => handleFetchRequest(request)
case ApiKeys.LIST_OFFSETS => handleListOffsetRequest(request)
case ApiKeys.METADATA => handleTopicMetadataRequest(request)
case ApiKeys.LEADER_AND_ISR => handleLeaderAndIsrRequest(request)
// 省略部分代码
... ...
}
} catch {
case e: FatalExitError => throw e
case e: Throwable => handleError(request, e)
} finally {
request.apiLocalCompleteTimeNanos = time.nanoseconds
}
}
Processor从自己的ResponseQueue中拉取待发送的Respnose;
Processor将Response发给客户端;
五. 总结
才疏学浅,未能窥其十之一二,随时欢迎各位交流补充。若文章质量还算及格,可以点赞收藏加以鼓励,后续我继续更新。
知乎主页:https://www.zhihu.com/people/hao_zhihu
关注收藏不迷路,第一时间接收技术文章推送
微信公众号:

Kafka源码分析(四) - Server端-请求处理框架的更多相关文章
- Kafka源码分析(三) - Server端 - 消息存储
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 业务模型 1.1 概念梳理 1.2 文件分析 1.2.1 数据目录 1.2.2 . ...
- Apache Kafka源码分析 – Broker Server
1. Kafka.scala 在Kafka的main入口中startup KafkaServerStartable, 而KafkaServerStartable这是对KafkaServer的封装 1: ...
- kafka源码分析之一server启动分析
0. 关键概念 关键概念 Concepts Function Topic 用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上. Partition 是Kafka中横向扩展和一 ...
- Hbase源码分析:server端RPC
server端rpc包括master和RegionServer.接下来主要梳理一下,master和regionserver中有关rpc创建,启动以及处理的过程. 1,server rpc的初始化过程 ...
- Kafka源码分析系列-目录(收藏不迷路)
持续更新中,敬请关注! 目录 <Kafka源码分析>系列文章计划按"数据传递"的顺序写作,即:先分析生产者,其次分析Server端的数据处理,然后分析消费者,最后再补充 ...
- 使用react全家桶制作博客后台管理系统 网站PWA升级 移动端常见问题处理 循序渐进学.Net Core Web Api开发系列【4】:前端访问WebApi [Abp 源码分析]四、模块配置 [Abp 源码分析]三、依赖注入
使用react全家桶制作博客后台管理系统 前面的话 笔者在做一个完整的博客上线项目,包括前台.后台.后端接口和服务器配置.本文将详细介绍使用react全家桶制作的博客后台管理系统 概述 该项目是基 ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- Kafka源码分析(一) - 概述
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 实际问题 二. 什么是Kafka, 如何解决这些问题的 三. 基本原理 1. 基本 ...
- Kafka源码分析及图解原理之Producer端
一.前言 任何消息队列都是万变不离其宗都是3部分,消息生产者(Producer).消息消费者(Consumer)和服务载体(在Kafka中用Broker指代).那么本篇主要讲解Producer端,会有 ...
随机推荐
- proteus的C51仿真
Proteus的C51仿真 1.实验原理 Proteus是对C51仿真效果比较好的软件了,可以利用丰富的数字资源的外设实现比较接近实际的设计.仿真方法也比较简单,不需要下载,只需要将仿真文件导出到器件 ...
- MicroNet: 低秩近似分解卷积以及超强激活函数,碾压MobileNet | 2020新文分析
论文提出应对极低计算量场景的轻量级网络MicroNet,包含两个核心思路Micro-Factorized convolution和Dynamic Shift-Max,Micro-Factorized ...
- 【Java面试题】Spring
八.Spring 57)什么是 Spring 的依赖注入 IOC( Inversion of Control )的⼀个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象. 其中依赖注入(DI ...
- 关于JDK21控制台字符集编码问题
关于JDK21控制台字符集编码问题 前言: 某日尝试JDK21,idea控制台字符集编码一直乱码,后将idea所有能配置UTF-8的配置都配了一遍,无果,后搜索JDK21字符集编码相关后解决 1.配置 ...
- #网络流,dinic,最小割#洛谷 3227 [HNOI2013]切糕
题目传送门 题目大意 \(P\)行\(Q\)列的楼房高度均为\(R\),每一层改造要花费一定的金钱, 每个楼房都要挑选有且仅有一层进行改造,并且相邻两个楼房改造位置的相对高度不能超过\(D\), 问最 ...
- #斯坦纳树,状压dp#洛谷 3264 [JLOI2015]管道连接
题目 分析 如果对于每一个频道单独跑斯坦纳树可能会存在两种频道共用一条道路而重复统计的情况, 考虑状压dp,设\(f[s]\)表示选择频道二进制状态为\(s\)的最小贡献,那么对于每个状态跑斯坦纳树然 ...
- #模拟#洛谷 2327 [SCOI2005]扫雷
题目 分析 考虑最多只有两种情况,因为确定一个位置其它位置随即也能确定, 那么指定第一个位置有没有雷然后判断一下后面推出的雷数是否为0或1,不是显然不行 代码 #include <cstdio& ...
- OpenHarmony Meetup 深圳站招募令
OpenHarmony Meetup城市巡回深圳站火热来袭!! 日期:2023年10月15日14:00 地点:深圳市福田区上步路中路1003号 深圳市科学馆 与OpenHarmony技术大咖近距离 ...
- “最新趋势:R语言lavaan结构方程模型(SEM)的实践应用与技巧”
结构方程模型(Sructural Equation Modeling,SEM)是分析系统内变量间的相互关系的利器,可通过图形化方式清晰展示系统中多变量因果关系网,具有强大的数据分析功能和广泛的适用性, ...
- Noah-MP陆面过程模型建模
[原文链接]:Noah-MP陆面过程模型建模方法与站点.区域模拟实践技术 [方式]:直播+永久回放+长期答疑群辅助+全套资料 [目标]:了解陆表过程的主要研究内容以及陆面模型在生态水文研究中的地位和作 ...