PaddleHub--{超参优化AutoDL Finetuner}【二】
相关文章:
基础知识介绍:
【一】ERNIE:飞桨开源开发套件,入门学习,看看行业顶尖持续学习语义理解框架,如何取得世界多个实战的SOTA效果?_汀、的博客-CSDN博客_ernie模型
百度飞桨:ERNIE 3.0 、通用信息抽取 UIE、paddleNLP的安装使用[一]_汀、的博客-CSDN博客_paddlenlp 安装
项目实战:
PaddleHub--飞桨预训练模型应用工具{风格迁移模型、词法分析情感分析、Fine-tune API微调}【一】_汀、的博客-CSDN博客
PaddleHub--{超参优化AutoDL Finetuner}【二】_汀、的博客-CSDN博客
PaddleHub实战篇{词法分析模型LAC、情感分类ERNIE Tiny}训练、部署【三】_汀、的博客-CSDN博客
PaddleHub实战篇{ERNIE实现文新闻本分类、ERNIE3.0 实现序列标注}【四】_汀、的博客-CSDN博客
PaddleHub还提供了超参优化(Hyperparameter Tuning)功能, 自动搜索最优模型超参得到更好的模型效果:
https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/tutorial/autofinetune.md
1.超参优化AutoDL Finetuner
目前深度学习模型参数可分为两类:模型参数 (Model Parameters) 与 超参数 (Hyper Parameters),前者是模型通过大量的样本数据进行训练学习得到的参数数据;后者则需要通过人工经验或者不断尝试找到最佳设置(如学习率、dropout_rate、batch_size等),以提高模型训练的效果。如果想得到一个效果好的深度学习神经网络模型,超参的设置非常关键。因为模型参数空间大,目前超参调整都是通过手动,依赖人工经验或者不断尝试,且不同模型、样本数据和场景下不尽相同,所以需要大量尝试,时间成本和资源成本非常浪费。PaddleHub AutoDL Finetuner可以实现自动调整超参数。
PaddleHub AutoDL Finetuner提供两种超参优化算法:
HAZero: 核心思想是通过对正态分布中协方差矩阵的调整来处理变量之间的依赖关系和scaling。算法基本可以分成以下三步:
采样产生新解;
计算目标函数值;
更新正态分布参数;
调整参数的基本思路为,调整参数使得产生更优解的概率逐渐增大。
- PSHE2: 采用哈密尔顿动力系统搜索参数空间中“势能”最低的点。而最优超参数组合就是势能低点。现在想求得最优解就是要找到更新超参数组合,即如何更新超参数,才能让算法更快更好的收敛到最优解。PSHE2算法根据超参数本身历史的最优,在一定随机扰动的情况下决定下一步的更新方向。
PaddleHub AutoDL Finetuner为了评估搜索的超参对于任务的效果,提供两种超参评估策略:
Full-Trail: 给定一组超参,利用这组超参从头开始Fine-tune一个新模型,之后在验证集评估这个模型;
Population-Based: 给定一组超参,若这组超参是第一轮尝试的超参组合,则从头开始Fine-tune一个新模型;否则基于前几轮已保存的较好模型,在当前的超参数组合下继续Fine-tune并评估;
二、如何配置(yaml文件和train.py)
使用PaddleHub AutoDL Finetuner需要准备两个指定格式的文件:待优化的超参数信息yaml文件hparam.yaml和需要Fine-tune的python脚本train.py。
2.1. hparam.yaml
hparam给出待搜索的超参名字、类型(int或者float)、搜索范围等信息,通过这些信息构建了一个超参空间,PaddleHub将在这个空间内进行超参数的搜索,将搜索到的超参传入train.py获得评估效果,根据评估效果自动调整超参搜索方向,直到满足搜索次数。
NOTE:
- yaml文件的最外层级的key必须是param_list;
param_list:
- name : hparam1
init_value : 0.001
type : float
lower_than : 0.05
greater_than : 0.00005
...
超参名字可以任意指定,PaddleHub会将搜索到的值以指定名称传递给train.py使用;
优化超参策略选择HAZero时,需要提供两个以上的待优化超参;
2.2. train.py
train.py用于接受PaddleHub搜索到的超参进行一次优化过程,将优化后的效果返回。
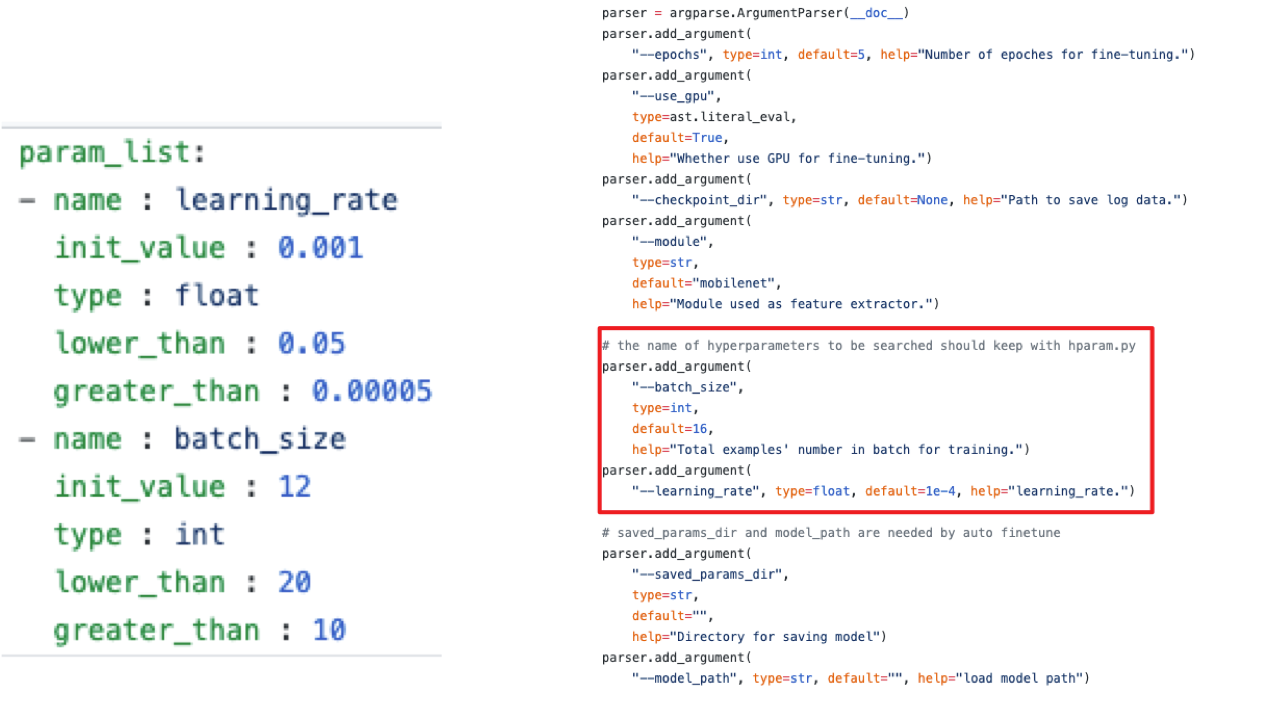
NOTE:
train.py的选项参数须包含待优化超参数,需要将超参以argparser的方式写在其中,待搜索超参数选项名字和yaml文件中的超参数名字保持一致。
train.py须包含选项参数saved_params_dir,优化后的参数将会保存到该路径下。
超参评估策略选择PopulationBased时,train.py须包含选项参数model_path,自动从model_path指定的路径恢复模型
train.py须反馈模型的评价效果(建议使用验证集或者测试集上的评价效果),通过调用
report_final_result接口反馈,如hub.report_final_result(eval_avg_score["acc"])输出的评价效果取值范围应为
(-∞, 1],取值越高,表示效果越好。
2.3 PaddleHub超参优化——文本分类参考
PaddleHub AutoDL Finetuner超参优化--NLP情感分类任务。:
PaddleHub/demo/autofinetune_text_classification at release/v1.5 · PaddlePaddle/PaddleHub · GitHub
PaddleHub AutoDL Finetuner超参优化--CV图像分类任务。
三、启动方式
确认安装PaddleHub版本在1.3.0以上, 同时PaddleHub AutoDL Finetuner功能要求至少有一张GPU显卡可用。
通过以下命令方式:
$ OUTPUT=result/
$ hub autofinetune train.py --param_file=hparam.yaml --gpu=0,1 --popsize=5 --round=10
--output_dir=${OUTPUT} --evaluator=fulltrail --tuning_strategy=pshe2
其中,选项
--param_file: 必填,待优化的超参数信息yaml文件,即上述hparam.yaml;--gpu: 必填,设置运行程序的可用GPU卡号,中间以逗号隔开,不能有空格;--popsize: 可选,设置程序运行每轮产生的超参组合数,默认为5;--round: 可选,设置程序运行的轮数,默认为10;--output_dir: 可选,设置程序运行输出结果存放目录,不指定该选项参数时,在当前运行路径下生成存放程序运行输出信息的文件夹;--evaluator: 可选,设置自动优化超参的评价效果方式,可选fulltrail和populationbased, 默认为populationbased;--tuning_strategy: 可选,设置自动优化超参算法,可选hazero和pshe2,默认为pshe2;
NOTE:
进行超参搜索时,一共会进行n轮(--round指定),每轮产生m组超参(--popsize指定)进行搜索。上一轮的优化结果决定下一轮超参数调整方向;
当指定GPU数量不足以同时跑一轮时,AutoDL Finetuner功能自动实现排队为了提高GPU利用率,建议卡数为刚好可以被popsize整除。如popsize=6,gpu=0,1,2,3,则每搜索一轮,AutoDL Finetuner自动起四个进程训练,所以第5/6组超参组合需要排队一次,在搜索第5/6两组超参时,会存在两张卡出现空闲等待的情况,如果设置为3张可用的卡,则可以避免这种情况的出现;
四、目录结构
进行自动超参搜索时,PaddleHub会生成以下目录
./output_dir/
├── log_file.txt
├── best_model
├── visualization
├── round0
├── round1
├── ...
└── roundn
├── log-0.info
├── log-1.info
├── ...
├── log-m.info
├── model-0
├── model-1
├── ...
└── model-m
其中output_dir为启动autofinetune命令时指定的根目录,目录下:
log_file.txt记录每一轮搜索所有的超参以及整个过程中所搜索到的最优超参;
best_model保存整个搜索训练过程中得到的最优的模型参数;
visualization记录可视化过程的日志文件;
round0 ~ roundn记录每一轮的数据,在每个round目录下,还存在以下文件;
log-0.info ~ log-m.info记录每个搜索方向的日志;
model-0 ~ model-m记录对应搜索的参数;
五、可视化
AutoDL Finetuner API在优化超参过程中会自动对关键训练指标进行打点,启动程序后执行下面命令。
$ tensorboard --logdir ${OUTPUT}/visualization --host ${HOST_IP} --port ${PORT_NUM}
其中为输出目录,OUTPUT为AutoDLFinetuner输出目录,{HOST_IP}为本机IP地址,${PORT_NUM}为可用端口号,如本机IP地址为192.168.0.1,端口号8040, 用浏览器打开192.168.0.1:8040,即可看到搜索过程中各超参以及指标的变化情况。
六、args参数传递
PaddleHub AutoDL Finetuner 支持将train.py中的args其余不需要搜索的参数通过autofinetune remainder方式传入。这个不需要搜索的选项参数名称应该和通过hub autofinetune的传入选项参数名称保持一致。如PaddleHub AutoDL Finetuner超参优化--NLP情感分类任务示例中的max_seq_len选项,可以参照以下方式传入。
$ OUTPUT=result/
$ hub autofinetune train.py --param_file=hparam.yaml --gpu=0,1 --popsize=5 --round=10
--output_dir=${OUTPUT} --evaluator=fulltrail --tuning_strategy=pshe2 max_seq_len 128
七、其他
- 如在使用AutoDL Finetuner功能时,输出信息中包含如下字样:
WARNING:Program which was ran with hyperparameters as ... was crashed!
首先根据终端上的输出信息,确定这个输出信息是在第几个round(如round 3),之后查看${OUTPUT}/round3/下的日志文件信息log.info, 查看具体出错原因。
- PaddleHub AutoDL Finetuner功能使用过程中建议使用的GPU卡仅供PaddleHub使用,无其他任务使用。
PaddleHub--{超参优化AutoDL Finetuner}【二】的更多相关文章
- 机器学习超参数优化算法-Hyperband
参考文献:Hyperband: Bandit-Based Configuration Evaluation for Hyperparameter Optimization I. 传统优化算法 机器学习 ...
- CNN超参数优化和可视化技巧详解
https://zhuanlan.zhihu.com/p/27905191 在深度学习中,有许多不同的深度网络结构,包括卷积神经网络(CNN或convnet).长短期记忆网络(LSTM)和生成对抗网络 ...
- 小白学习Spark系列六:Spark调参优化
前几节介绍了下常用的函数和常踩的坑以及如何打包程序,现在来说下如何调参优化.当我们开发完一个项目,测试完成后,就要提交到服务器上运行,但运行不稳定,老是抛出如下异常,这就很纳闷了呀,明明测试上没问题, ...
- 百度APP移动端网络深度优化实践分享(二):网络连接优化篇
本文由百度技术团队“蔡锐”原创发表于“百度App技术”公众号,原题为<百度App网络深度优化系列<二>连接优化>,感谢原作者的无私分享. 一.前言 在<百度APP移动端网 ...
- scrapy框架的日志等级和请求传参, 优化效率
目录 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 请求传参 如何提高scripy的爬取效率 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 在使 ...
- sklearn.GridSearchCV选择超参
from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.model ...
- lecture16-联合模型、分层坐标系、超参数优化及本课未来的探讨
这是HInton的第16课,也是最后一课. 一.学习一个图像和标题的联合模型 在这部分,会介绍一些最近的在学习标题和描述图片的特征向量的联合模型上面的工作.在之前的lecture中,介绍了如何从图像中 ...
- 前端js优化方案(二)持续更新
由于上篇篇幅过长,导致编辑出了问题,另开一篇文章继续: (4)减少迭代次数,最广为人知的一种限制循环迭代次数的模式被称为“达夫设备(Duff`s Device)” Duff`s Device的理念是: ...
- Java 程序优化:字符串操作、基本运算方法等优化策略(二)
五.数据定义.运算逻辑优化 多使用局部变量 调用方法时传递的参数以及在调用中创建的临时变量都保存在栈 (Stack) 里面,读写速度较快. 其他变量,如静态变量.等,都在堆实例变量 (heap) 中创 ...
- SQL Server 性能优化实战系列(二)
SQL Server datetime数据类型设计.优化误区 一.场景 在SQL Server 2005中,有一个表TestDatetime,其中Dates这个字段的数据类型是datetime,如果你 ...
随机推荐
- 【Redis】面试题 GEO地理位置信息
目录 面试 1 http协议详情,http协议版本,http一些请求头 2 GET请求和POST请求的区别 3 如何实现服务器给客户端发送消息,websocket是什么? 4 悲观锁和乐观锁,如何实现 ...
- 【django-Vue】项目day01 pip永久换源 虚拟环境搭建 项目前后端创建 项目目录调整
目录 昨日回顾 1 企业项目类型 2 企业项目开发流程 3 路飞项目需求 4 pip永久换源 5 虚拟环境搭建 5.1 使用pycharm创建虚拟环境 5.2 通用方案创建虚拟环境 6 luffy项目 ...
- PS CJ37/CJ38 增加和返回预算
一.预算补充CJ37/预算返回CJ38 二.补充预算CJ37,点击保存 预算返回CJ38,点击保存 三.代码示例 预算补充代码 "------------------------------ ...
- 面对科技公司的制裁,俄罗斯放出封印7年的神兽:RuTracker
大家好,我是DD! 最近俄乌冲突引发的科技公司站队,Oracle.微软.三星等全球知名科技公司都开始对俄罗斯实施制裁与封锁.就连崇尚自由的开源社区GitHub也发文会严格限制俄罗斯获得维持其咄咄逼人的 ...
- Educational Codeforces Round 100 (Rated for Div. 2) 简单记录
最近在写Web大作业和期末复习,可能还会有一段时间不会更新blog了 1463A. Dungeon 题意:有3个血量为a,b,c的敌人,现在你每7发子弹能进行一次范围AOE攻击(即一次能集中三人),每 ...
- vue tabBar导航栏设计实现5-最终版本
系列导航 一.vue tabBar导航栏设计实现1-初步设计 二.vue tabBar导航栏设计实现2-抽取tab-bar 三.vue tabBar导航栏设计实现3-进一步抽取tab-item 四.v ...
- 黑马vue学习笔记
1.v-model原理 2.数组相关API 3.prop命名规则: 4.非父子组件传值-事件中心
- 【教你学Qt桌面端开发】pt1:浅谈Qt:特色C++主义类库
还在为头脑简单看不懂代码而发愁吗?还在为思想浅薄只会人云亦云.拾人牙慧.鹦鹉学舌而遭人鄙夷吗? <教你写代码>,从另一维度解读代码,让你成为见解独特的黑马观众. 教你学Qt桌面端开发栏目旨 ...
- 2023 SHCTF-校外赛道 MISC WP
WEEK1 请对我使用社工吧 提示:k1sme4的朋友考到了一所在k1sme4家附近的大学,一天,k1sme4的朋友去了学校对面的商场玩,并给k1sme4拍了一张照片,你能找到他的学校吗? flag格 ...
- SpringMVC02——第一个MVC程序-配置版(low版)
配置版 新建一个子项目,添加Web支持![在MVC01中有详细方法] 确定导入了SpringMVC的依赖 配置web.xml,注册DispatcherServlet <?xml version= ...