Spark-Core RDD依赖关系
scala> var rdd1 = sc.textFile("./words.txt")
rdd1: org.apache.spark.rdd.RDD[String] = ./words.txt MapPartitionsRDD[16] at textFile at <console>:24
scala> val rdd2 = rdd1.flatMap(_.split(" "))
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[17] at flatMap at <console>:26
scala> val rdd3 = rdd2.map((_, 1))
rdd3: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[18] at map at <console>:28
scala> val rdd4 = rdd3.reduceByKey(_ + _)
rdd4: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[19] at reduceByKey at <console>:30
1、查看 RDD 的血缘关系
scala> rdd1.toDebugString
res1: String =
(2) ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
scala> rdd2.toDebugString
res2: String =
(2) MapPartitionsRDD[2] at flatMap at <console>:26 []
| ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
scala> rdd3.toDebugString
res3: String =
(2) MapPartitionsRDD[3] at map at <console>:28 []
| MapPartitionsRDD[2] at flatMap at <console>:26 []
| ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
scala> rdd4.toDebugString
res4: String =
(2) ShuffledRDD[4] at reduceByKey at <console>:30 []
+-(2) MapPartitionsRDD[3] at map at <console>:28 []
| MapPartitionsRDD[2] at flatMap at <console>:26 []
| ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
说明:
圆括号(2): 2表示RDD的并行度,几个分区
2、查看RDD的依赖关系
scala> rdd1.dependencies
res28: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@70dbde75)
scala> rdd2.dependencies
res29: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@21a87972)
scala> rdd3.dependencies
res30: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@4776f6af)
scala> rdd4.dependencies
res31: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@4809035f)
RDD之间的关系可以从两个维度来理解:
(1)一个是RDD从哪些RDD转换而来,也就是RDD的parent RDD(s)是什么
(2)另一个是RDD依赖于parent RDD(s)的哪些 Partitions(s),这种关系称为RDD之间的依赖
RDD依赖的 2 中策略:
(1)窄依赖(transformations with narrow dependencies)
(2)宽依赖(transformations with wide dependencies)
宽依赖对 Spark 去评估一个 transformations 有更加重要的影响, 比如对性能的影响.
3、窄依赖
如果 B-RDD 是由 A-RDD 计算得到的, 则 B-RDD 就是Child RDD, A-RDD 就是 parent RDD.
如果依赖关系在设计的时候就可以确定,而不需要考虑父RDD分区中的记录。并且如果父RDD中的每个分区最多只有一个分区,这样的依赖就是窄依赖
总结:父RDD的每个分区最多被一个RDD的分区使用
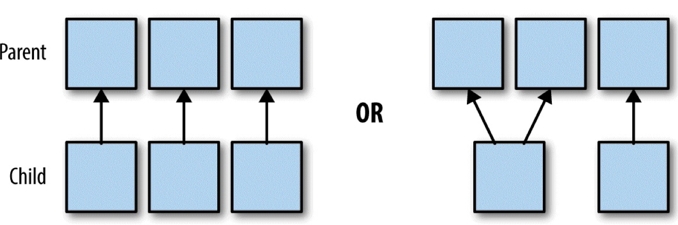
具体来说,窄依赖的时候,子RDD中的分区要么只依赖一个父RDD中的一个分区(map,filter),要么在设计的时候就能确定子RDD是父RDD的一个子集(coalesce)
所以, 窄依赖的转换可以在任何的的一个分区上单独执行, 而不需要其他分区的任何信息.
4、宽依赖
如果 父 RDD 的分区被不止一个子 RDD 的分区依赖, 就是宽依赖.
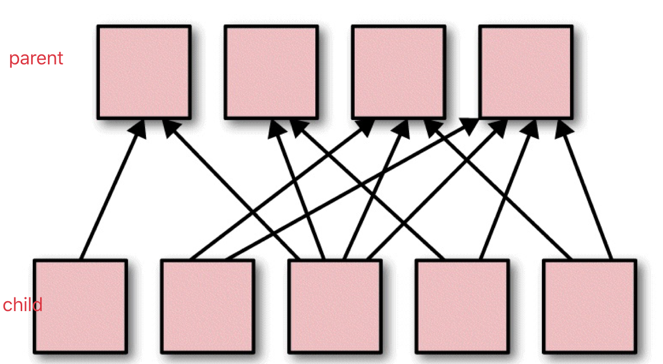
宽依赖工作的时候, 不能随意在某些记录上运行, 而是需要使用特殊的方式(比如按照 key)来获取分区中的所有数据.
例如: 在排序(sort)的时候, 数据必须被分区, 同样范围的 key 必须在同一个分区内. 具有宽依赖的 transformations 包括: sort, reduceByKey, groupByKey, join, 和调用rePartition函数的任何操作.
Spark-Core RDD依赖关系的更多相关文章
- Spark之RDD依赖关系及DAG逻辑视图
RDD依赖关系为成两种:窄依赖(Narrow Dependency).宽依赖(Shuffle Dependency).窄依赖表示每个父RDD中的Partition最多被子RDD的一个Partition ...
- RDD算子、RDD依赖关系
RDD:弹性分布式数据集, 是分布式内存的一个抽象概念 RDD:1.一个分区的集合, 2.是计算每个分区的函数 , 3.RDD之间有依赖关系 4.一个对于key-value的RDD的Partit ...
- (摘)使用 .NET Core 实现依赖关系注入
为什么使用依赖关系注入? 使用 .NET,通过 new 运算符(即,new MyService 或任何想要实例化的对象类型)调用构造函数即可轻松实现对象实例化.遗憾的是,此类调用会强制实施客户端(或应 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- Spark之RDD的定义及五大特性
RDD是分布式内存的一个抽象概念,是一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,能横跨集群所有节点并行计算,是一种基于工作集的应用抽象. RDD底层存储原理:其数据分布存储于多台机器上 ...
- Spark之RDD
Spark学习之路Spark之RDD 目录 一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数 ...
随机推荐
- NOIP2016提高A组五校联考1总结
第一题二分,在比赛上明明想到的方法,结果考虑的时候似乎漏了什么,被否决掉了. 只打了个水法,10分. 第二题,最长不上升子序列,原题,类似的题目做过两道,直接搞定. 第三题,一开始想了一种通过在树上打 ...
- 原生js数组排序(封装方法)
//两值互换 function Sort(arr, index){ //参数arr代表数组,index代表数组元素下标 arr[index] += arr[index + 1]; //a+=b; a ...
- JPA学习(二、JPA_基本注解)
框架学习之JPA(二) JPA是Java Persistence API的简称,中文名Java持久层API,是JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中 ...
- 游标定位:Cursor类
关于 Cursor Cursor 是每行的集合. 使用 moveToFirst() 定位第一行. 你必须知道每一列的名称. 你必须知道每一列的数据类型. Cursor 是一个随机的数据源. 所有的数据 ...
- [Usaco2010 Dec]Treasure Chest 藏宝箱
题目链接:点这里 Solution: 刚开始以为是博弈论,然而不是... 首先考虑n方dp,设f(l,r)为只有\(l\)到\(r\)区间的钱的先手最大获利 那么我们可以得到式子f(l,r)=sum( ...
- 详细讲解Android中的Message的源码
相信大家对于Android中的Handler是在为熟悉不过了,但是要知道,Handler就其本身而言只是一个壳子,真正在内部起到作用的是Message这个类,对于Message这个类,相信大家也不会陌 ...
- [BZOJ4456][ZJOI2016]旅行者:分治+最短路
分析 类似于点分治的思想,只统计经过分割线的最短路,然后把地图一分为二. 代码 #include <bits/stdc++.h> #define rin(i,a,b) for(regist ...
- mysqli使用localhost问题
<?php $mysqli = new mysqli('localhost', 'root', '123456', 'mysql'); if ($mysqli->connect_error ...
- 快速排序和二分查找(Go)
package main import ( "fmt" "sync") var waitGroup sync.WaitGroup func main() { d ...
- (转)GitBlit安装
转:https://blog.csdn.net/qq_32599479/article/details/90748371 GitBlit的安装本文是基于Windows 10系统环境,安装和测试GitB ...