分布式监控系统Zabbix3.2添加自动发现磁盘IO并注册监控
zabbix并没有给我们提供这么一个模板来完成在Linux中磁盘IO的监控,所以我们需要自己来创建一个,在此还是在Linux OS中添加。
由于一台服务器中磁盘众多,如果只一两台可以手动添加,但服务集群达到几十那就非常麻烦,因此需要利用 自动发现 这个功能,自动发现后自动添加对服务器磁盘的监控,而且添加磁盘后也会自动添加到监控,实现自动化运维的效果,所以在这里也演示一次自动发现的配置。
打开Linux模板,添加自动发现规则
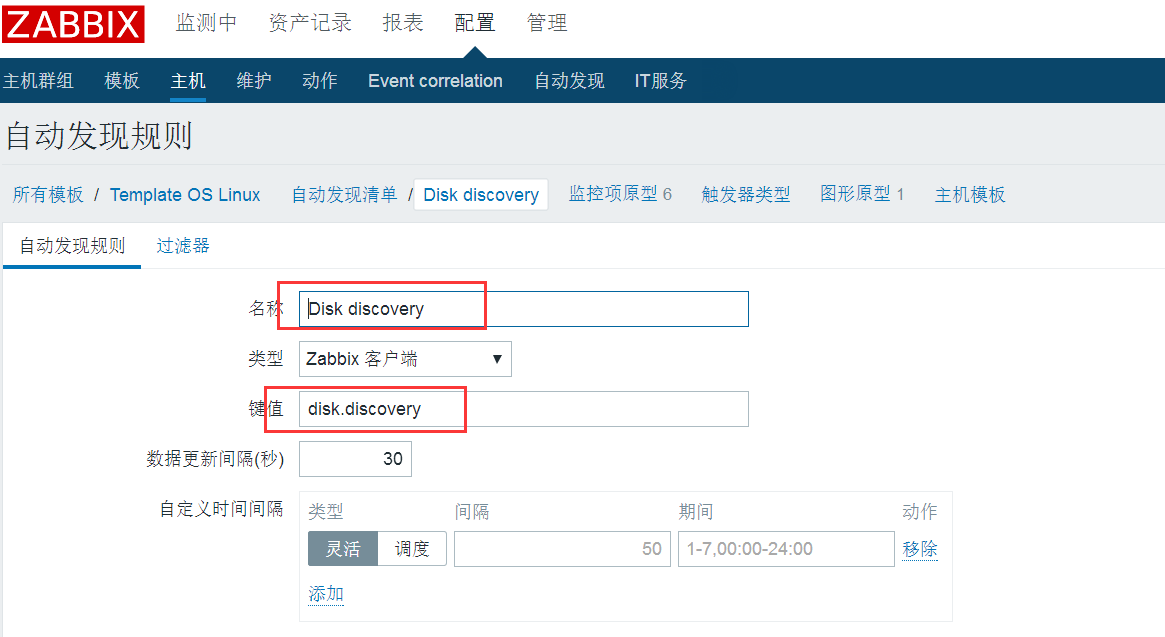
上面的key值是需要在 zabbix_agent.conf 中配置的
UserParameter=disk.discovery,/usr/local/share/zabbix/alertscripts/disk_discovery.sh
自动发面的规则用shell代码实现,返回一段磁盘的json list
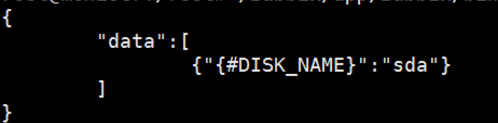
代码 disk_discovery.sh
#!/bin/bash
diskarray=(`cat /proc/diskstats |grep -E "\bsd[abcdefg]\b|\bxvd[abcdefg]\b"|grep -i "\b$1\b"|awk '{print $3}'|sort|uniq 2>/dev/null`)
length=${#diskarray[@]}
printf "{\n"
printf '\t'"\"data\":["
for ((i=0;i<$length;i++))
do
printf '\n\t\t{'
printf "\"{#DISK_NAME}\":\"${diskarray[$i]}\"}"
if [ $i -lt $[$length-1] ];then
printf ','
fi
done
printf "\n\t]\n"
printf "}\n"
到此自动发现磁盘已完,有点简单吧。
添加监控项

按照上面的内容添加第一个写扇区的次数监控,接下来按下面的内容添加共6个内容。
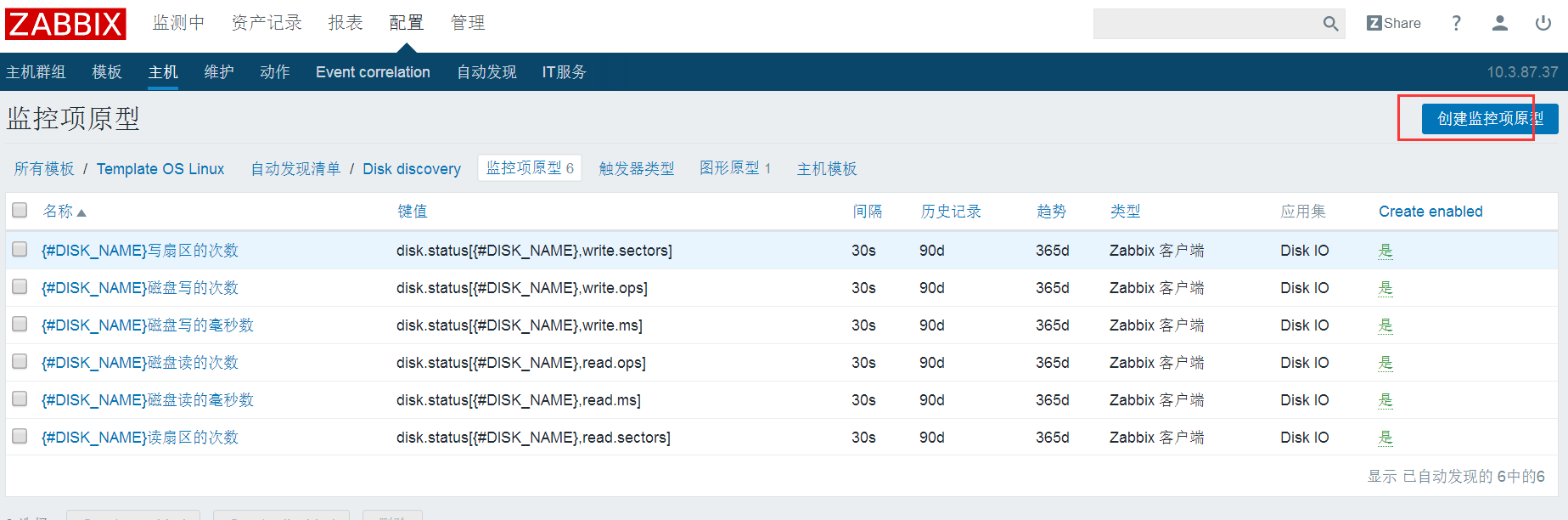
内容介绍
名称: {#DISK_NAME}磁盘读的次数
键值: disk.status[{#DISK_NAME},read.ops]
单位: ops/second
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘写的次数
键值: disk.status[{#DISK_NAME},write.ops]
单位: ops/second
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘读的毫秒数
键值: disk.status[{#DISK_NAME},read.ms]
单位: ms
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘写的毫秒数
键值: disk.status[{#DISK_NAME},write.ms]
单位: ms
储存值:差量(每秒速率)
名称: {#DISK_NAME}读扇区的次数
键值: disk.status[{#DISK_NAME},read.sectors]
单位: B/sec
使用自定义倍数:
储存值:差量(每秒速率)
名称: {#DISK_NAME}写扇区的次数
键值: disk.status[{#DISK_NAME},write.sectors]
单位: B/sec
使用自定义倍数:
储存值:差量(每秒速率)
然后如果得到这些值是需要shell脚本的:
disk_status.sh
#/bin/sh
device=$1
DISK=$2 case $DISK in
read.ops)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $4}' #//磁盘读的次数
;;
read.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $7}' #//磁盘读的毫秒数
;;
write.ops)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $8}' #//磁盘写的次数
;;
write.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $11}' #//磁盘写的毫秒数
;;
io.active)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $12}' #//I/O的当前进度,
;;
read.sectors)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $6}' #//读扇区的次数(一个扇区的等于512B)
;;
write.sectors)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $10}' #//写扇区的次数(一个扇区的等于512B)
;;
io.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $13}' #//花费在IO操作上的毫秒数
;; esac
在客户端中的zabbix_agent.conf 中一起配置:
UserParameter=disk.discovery,/usr/local/share/zabbix/alertscripts/disk_discovery.sh
UserParameter=disk.status[*],/usr/local/share/zabbix/alertscripts/disk_status.sh $1 $2
要注意的是以上两个文件需要给x 执行权限。
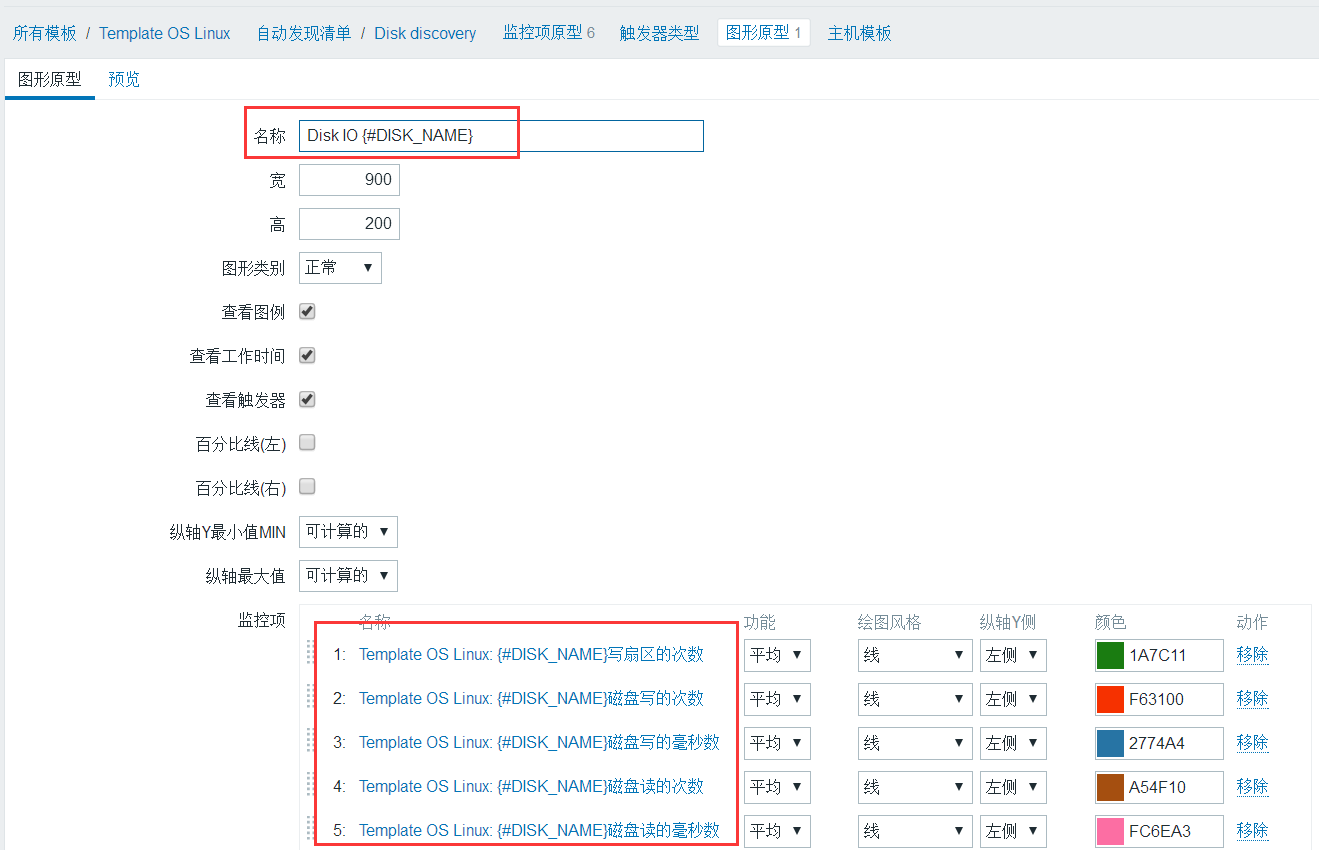
添加图形显示
在图形原型中添加,注意名称中要带哪个磁盘的动态名称,不然会出现Disk IO 已注册的错误信息。
zabbix3 Cannot create graph: graph with the same name "Disk IO" already exists
在监控项中选择上面添加的6个监控项。
测试效果
重启客户端的zabbix_agentd,然后在zabbix服务端对服务发现和写扇区次数进行测试。代码如下,有显示内容说明已经部署成功。


查看图形化,选择监控主机,图形中查看,若还没有项,需要等个几分钟再看。
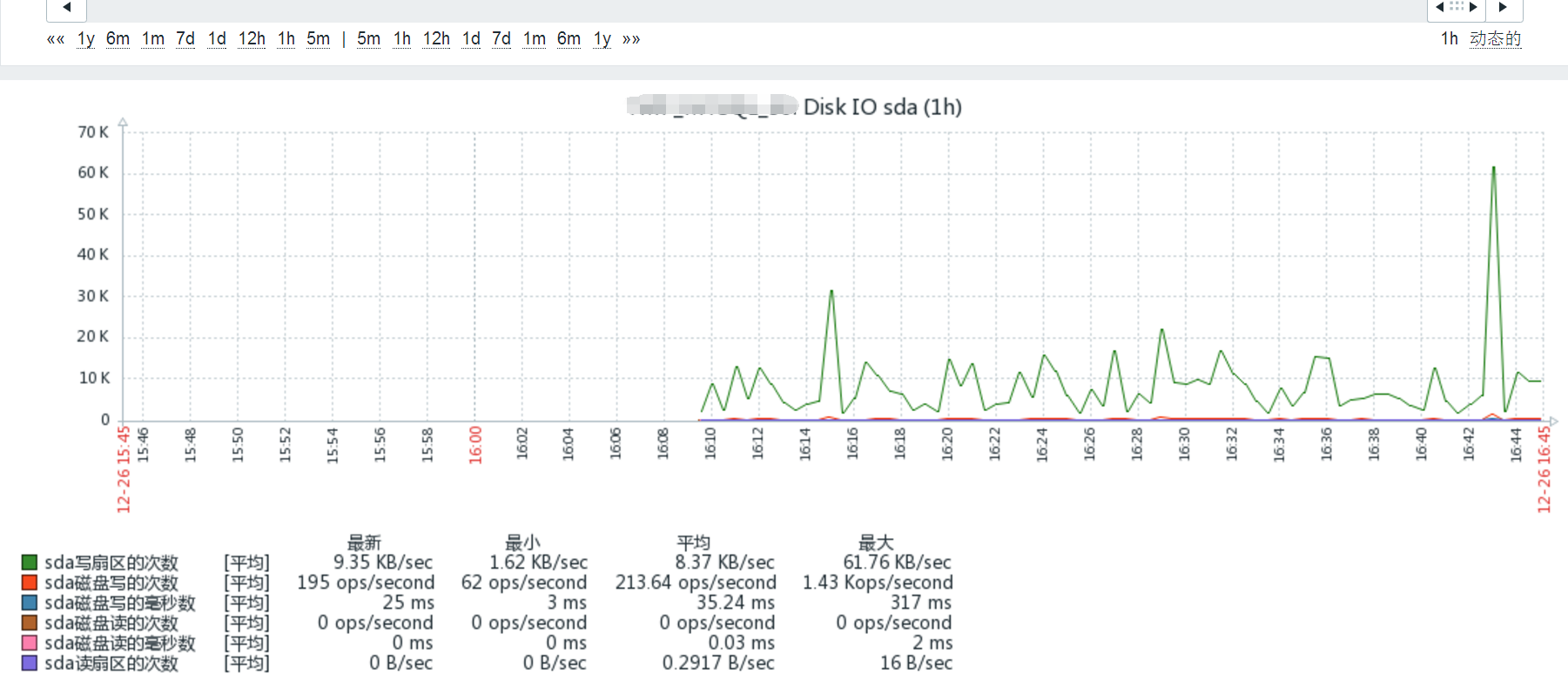
问题:
网上有网友用的是python来实现自动发现功能,但测试发现老是报错:
python import: command not found

可能是依赖包有问题,考虑到集群服务器的python环境问题,因此就不考虑用python的实现。
以上的内容也是基于之前的文章中的内容作为介绍基础,若有其他问题可先看之前的文章中介绍的基础环境。
分布式监控系统Zabbix3.2添加自动发现磁盘IO并注册监控的更多相关文章
- 分布式监控系统Zabbix-3.0.3-完整安装记录(3)-监控nginx,php,memcache,Low-level discovery磁盘IO
前段时间在公司IDC服务器上部署了zabbix3.0.3监控系统,除了自带的内存/带宽/CPU负载等系统资源监控模板以及mysql监控模板外,接下来对诸如nginx.php.memcache.磁盘IO ...
- zabbix之 自动发现磁盘io util 监控
一.iostat Zabbix并没有提供模板来监控磁盘的IO性能,所以我们需要自己来创建一个.iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之 ...
- 分布式监控系统Zabbix3.2给异常添加邮件报警
在前一篇 分布式监控系统Zabbix3.2跳坑指南 中已安装好服务端和客户端,此处客户端是被监控的服务器,可能有上百台服务器.监控的目的一个是可以查看历史状态,可以对比零晨和工作区间数据的对比,以便后 ...
- 分布式监控系统Zabbix-3.0.3-新版微信报警(企业微信取代企业号)
一般来说,Zabbix可以通过多种方式把告警信息发送到指定人,常用的有邮件,短信报警方式,但是现在越来越多的企业开始使用zabbix结合微信作为主要的告警方式,这样可以及时有效的把告警信息推送到接收人 ...
- 分布式监控系统Zabbix-3.0.3-完整安装记录(1)
分布式监控系统Zabbix-3.0.3的安装记录 环境说明zabbix-server:192.168.1.30 #zabbix的服务端(若要监控本机,则需要配置本机的Zabbix agent, ...
- 分布式监控系统Zabbix-3.0.3-完整安装记录(7)-使用percona监控MySQL
前面已经介绍了分布式监控系统Zabbix-3.0.3-完整安装记录(2)-添加mysql监控,但是没有提供可以直接使用的Key,太过简陋,监控效果不佳.要想更加仔细的监控Mysql,业内同学们都会选择 ...
- 分布式监控系统Zabbix3.2监控数据库的连接数
在 分布式监控系统Zabbix3.2跳坑指南 和 分布式监控系统Zabbix3.2给异常添加邮件报警 已经介绍了如何安装以及报警.此篇通过介绍监控数据库的3306端口连接数来了解如何监控其它端口和配置 ...
- 分布式监控系统Zabbix3.2对数据库的连接数预警
在前篇分布式监控系统Zabbix3.2监控数据库的连接数 中已经对数据库的端口3306进行了监控,可以看到数据库的连接数历史变化有高有低,那如果达到了数据库连接数的阀值是不是主动通知给运维人员去检查问 ...
- zabbix3.0自动发现磁盘并监控磁盘IO
Zabbix 版本:3.0 操作系统:Ubuntu16.04 操作环境,在被监控的主机上安装zabbix agent.安装方式为源码包安装. 简要安装步骤: 参考:https://www.zabbix ...
随机推荐
- JS 中对变量类型的五种判断方法
5种基本数据类型:undefined.null.boolean.unmber.string 复杂数据类型:object. object:array.function.date等 方法一:使用typeo ...
- LABjs、RequireJS、SeaJS 哪个最好用?为什么?
感谢玉伯在知乎的奉献,下面全文转载:http://www.zhihu.com/question/20342350/answer/14828786 LABjs 的核心是 LAB(Loading and ...
- caffe在windows编译project及执行mnist数据集測试
caffe在windows上的配置和编译能够參考例如以下的博客: http://blog.csdn.net/joshua_1988/article/details/45036993 http://bl ...
- logstash 向elasticsearch写入数据,怎样指定多个数据template
之前在配置从logstash写数据到elasticsearch时,指定单个数据模板没有问题.可是在配置多个数据模板时候,总是不成功,后来找了非常多资料,最终找到解决的方法,就是要多加一个配置项: te ...
- Android事件拦截机制简单分析
前一阶段,在学习的时候,遇到了我觉得的我接触安卓以来的最多的一次事件拦截出来,那个项目,用到了slidemenu側滑菜单条,然后加上tab标签,还有轮播广告,listview上下滑动.viewpage ...
- Python 项目实践一(外星人入侵小游戏)第二篇
接着上次的继续学习. 一 创建一个设置类 每次给游戏添加新功能时,通常也将引入一些新设置.下面来编写一个名为settings的模块,其中包含一个名为Settings的类,用于将所有设置存储在一个地方, ...
- C#应用程序隐藏调用bat脚本
做c#应用程序有些调用windows自带的bat脚本会比较方便 Process proc; proc = null; try { string targetDir = GetParentUrl() + ...
- OC学习9——反射机制
1.OC提供了3种编程方式与运行环境进行交互: 直接通过OC的源代码:这是最常见的方式,开发人员只是编写OC源代码,而运行环境负责在后台工作. 通过NSObject类中定义的方法进行动态编程:因为绝大 ...
- Oracle初级——续续篇
逝者如斯夫,不舍昼夜 所有的SQL都经过测试,可粘贴,可复制,有问题请各位大神指出...... --约束 与表一起使用 约束不合理的数据,使其不能进入表中? ','李小龙','一班','该学生成天练武 ...
- 回顾2017系列篇(一):最佳的11篇UI/UX设计文章
2017已经接近尾声,在这一年中,设计领域发生了诸多变化.也是时候对2017年做一个总结,本文主要是从2017设计文章入手,列出了个人认为2017设计行业里最重要的UI/UX文章的前11名,供大家参考 ...