Pandas基础学习与Spark Python初探
1.Pandas是什么?
pandas是一个强大的Python数据分析工具包,是一个提供快速,灵活和表达性数据结构的python包,旨在使“关系”或“标记”数据变得简单直观。它旨在成为在Python中进行实用的真实世界数据分析的基本高级构建块。此外,它的更广泛的目标是成为最强大和最灵活的任何语言的开源数据分析/操作工具。
2.Pandas安装
这里使用pip包管理器安装(python版本为2.7.13)。在windows中,cmd进入python的安装路径下的Scripts目录,执行:
pip install pandas
即可安装pandas,安装完成后提示如下:
说明已成功安装pandas.这里同时安装了numpy等。
3.Pandas数据类型
pandas非常适合许多不同类型的数据:
- 具有非均匀类型列的表格数据,如在SQL表或Excel电子表格中
- 有序和无序(不一定是固定频率)时间序列数据。
- 带有行和列标签的任意矩阵数据(均匀类型或异质)
- 任何其他形式的观测/统计数据集。数据实际上不需要被标记就可以被放置到Pandas的数据结构中
4.Pandas基础
这里简单学习Pandas的基础,以命令模式为例,首先需要导入pandas包与numpy包,numpy这里主要使用其nan数据以及生成随机数:
import pandas as pd
import numpy as np
4.1 pandas之Series
通过传递值列表创建Series,让pandas创建一个默认整数索引:

4.2 pandas之DataFrame
通过传递numpy数组,使用datetime索引和标记的列来创建DataFrame:

查看DataFrame的头部和尾部数据:

显示索引,列和基础numpy数据:

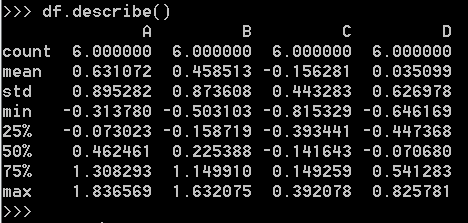
显示数据的快速统计摘要:
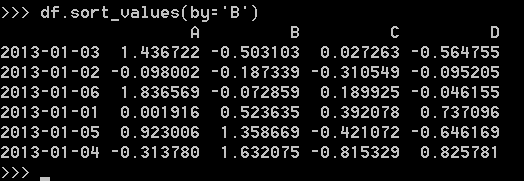
按值排序:
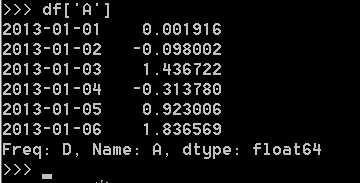
选择单个列,产生Series:
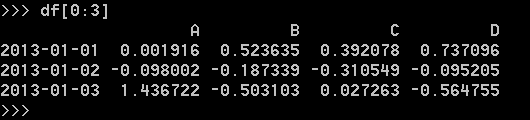
通过[]选择,通过切片选择行:
4.2.1 DataFrame读写csv文件
保存DataFrame数据到csv文件:

这里保存到c盘下,可以查看文件内容:
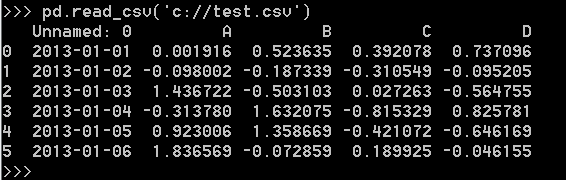
从csv文件读取数据:
4.2.2 DataFrame读写excel文件
保存数据到excel文件:

这里保存到c盘下,可以查看文件内容:
注:此处需要安装openpyxl,同pandas安装相同,pip install openpyxl.
从excel文件读取:
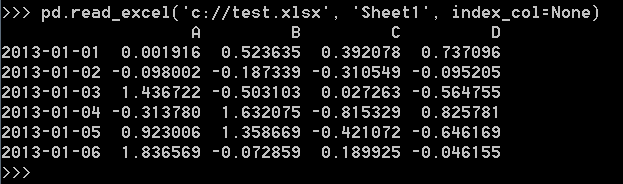
注:因为Excel需要单独的模块支持,所以需要安装xlrd,同pandas安装相同,pip install xlrd.
5.Pandas在Spark Python
这里测试读取一个已存在的parquet文件,目录为/data/parquet/20170901/,这里读取该目录下名字为part-r-00000开始的文件。将文件内容中的两列数据读取并保存到文件。代码如下:
#coding=utf-8 import sys
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.sql import SQLContext class ReadSpark(object):
def __init__(self, paramdate):
self.parquetroot = '/data/parquet/%s' # 这里是HDFS路径
self.thedate = paramdate
self.conf = SparkConf()
self.conf.set("spark.shuffle.memoryFraction", "0.5")
self.sc = SparkContext(appName='ReadSparkData', conf=self.conf)
self.sqlContext = SQLContext(self.sc) def getTypeData(self):
basepath = self.parquetroot % self.thedate
parqFile = self.sqlContext.read.option("mergeSchema", "true").option('basePath', basepath).parquet(
'%s/part-r-00000*' % (basepath))
resdata = parqFile.select('appId', 'os')
respd = resdata.toPandas()
respd.to_csv('/data/20170901.csv') #这里是Linux系统目录
print("--------------------data count:" + str(resdata.count())) if __name__ == "__main__":
reload(sys)
sys.setdefaultencoding('utf-8')
rs = ReadSpark('')
rs.getTypeData()
将代码命名为TestSparkPython.py,在集群提交,这里使用的命令为(参数信息与集群环境有关):
spark-submit --master yarn --driver-memory 6g --deploy-mode client --executor-memory 9g --executor-cores 3 --num-executors 50 /data/test/TestSparkPython.py
执行完成后,查看文件前五行内容,head -5 /data/20170901.csv:
总结:python编写spark程序还是非常方便的,pandas包在数据处理中的优势也很明显。在python越来越火的当下,值得深入学好python,就像python之禅写的那样……
Pandas基础学习与Spark Python初探的更多相关文章
- Python零基础学习系列之三--Python编辑器选择
上一篇文章记录了怎么安装Python环境,同时也成功的在电脑上安装好了Python环境,可以正式开始自己的编程之旅了.但是现在又有头疼的事情,该用什么来写Python程序呢,该用什么来执行Python ...
- Python基础学习笔记(一)python发展史与优缺点,岗位与薪资
相信有好多朋友们都是第一次了解python吧,可能大家也听过或接触过这个编程语言.那么到底什么是python呢?它在什么机缘巧合下诞生的呢?又为什么在短短十几年时间内就流行开来呢?就请大家带着疑问,让 ...
- pandas基础学习一
生成对象 用值列表生成 Series 时,Pandas 默认自动生成整数索引: In [3]: s = pd.Series([1, 3, 5, np.nan, 6, 8]) In [4]: s Out ...
- Python零基础学习系列之四--Python程序设计思想
前面我们把Python环境安装成功,同时也选择了自己合适的IDE工具来开启自己的编程之旅. 那么今天来说说怎么编程,程序设计需要什么步骤,我们应该怎么做才能编写自己的程序. 1-1.程序设计方法: I ...
- Pandas 基础学习
加载数据 Fun:pandas.read_csv >>> import pandas >>> food_info = pandas.read_csv("f ...
- numpy+pandas 基础学习
#-*- coding:utf-8 -*- import numpy as np; data1=[1,2,3,4,5] array1=np.array(data1) #创建数组/矩阵 # 使用nump ...
- pandas基础学习
1.导入两个数据分析重要的模块import numpy as npimport pandas as pd2.创建一个时间索引,所谓的索引(index)就是每一行数据的id,可以标识每一行的唯一值dat ...
- Python 读取UCI iris数据集分析、numpy基础学习
python基础.numpy使用.io读取数据集.数据处理转换与简单分析.读取UCI iris数据集中鸢尾花的萼片.花瓣长度数据,进行数据清理,去重,排序,并求出和.累积和.均值.标准差.方差.最大值 ...
- Python入门基础学习 三
Python入门基础学习 三 数据类型 Python区分整型和浮点型依靠的是小数点,有小数点就是浮点型. e记法:e就是10的意思,是一种科学的计数法,15000=1.5e4 布尔类型是一种特殊的整形 ...
随机推荐
- 解决无线网络连接出现黄色感叹号---win10
今天使用公司的电脑,这个电脑是另一位同事用过的,然后到我这里就连不上网了.然后把自己解决的方法记录一下: 开始运行输入以下命令来重置IP. 打开运行输入:cmd 在命令窗口中输入:ipconfig / ...
- 自带win10的笔记本电脑如何装win7
网上那么多的装机教程,还有必要专门写一篇装机攻略么?有的,非常必要的!因为真的有很多未知的坑要趟!首先,win10好不好?除了正版,其他没什么好的...如果没有SSD,经常要卡死于磁盘读写.当然,你可 ...
- python函数(2):函数进阶
昨天说了函数的一些最基本的定义,今天我们继续研究函数.今天主要研究的是函数的命名空间.作用域.函数名的本质.闭包等等 预习: 1.写函数,用户传入修改的文件名,与要修改的内容,执行函数,完成整个文件的 ...
- IPSP问题
场景:接触IPSP项目是个学习的过程,在此记录一些自己的认知,让自己更能全面的理解项目! 1 总结 1.1 日志追踪 IPSP工程所在的服务器有GW和Server之分,GW是连接外部服务器和serve ...
- ORA-12516: TNS: 监听程序找不到符合协议堆栈要求的可用处理程”的异常
简单说明:我们开发时多人开发,会频繁访问服务器数据库,结果当连接数大的时候,就会报ora-12516的错误,ORA-12516: TNS: 监听程序找不到符合协议堆栈要求的可用处理程"的异常 ...
- 初学 Python(十四)——生成器
初学 Python(十四)--生成器 初学 Python,主要整理一些学习到的知识点,这次是生成器. # -*- coding:utf-8 -*- ''''' 生成式的作用: 减少内存占有,不用一次性 ...
- TypeScript02 方法特性【参数种类、参数个数】、generate方法、析构表达式、箭头表达式、循环
1 方法的参数 1.1 必选参数 调用方法时实参的个数必须和定义方法时形参在数量和类型上匹配 /** * Created by Administrator on 2017/8/2 0002. */ f ...
- C++写#pragma warning(disable 4786)的作用
C++编程时,在使用STL(C++标准模板库)的时候经常引发类似的错误,尤其是vector,map这类模板类,模板中套模板,一不小心就很长了. 当命名超过C++规定范围255字符时,就会产生这个名为d ...
- Swift4 Json
swift4 带来了原生的json解析,它们分别是 JSONDecoder和JSONEncoder,使用起来还算方便,不过为了更方便,我把它们又进行了简单的封装: class JsonHelper { ...
- 关于Django的理解
Django的理解 Django的核心是中间件, 所有的请求和响应都会经过中间件 中间件是一个钩子框架, 它们可以介入请求的响应处理过程, 它用于在全局修改Django的输入和输出 Django有以下 ...