Python实现RNN
一般的前馈神经网络中, 输出的结果只与当前输入有关与历史状态无关, 而递归神经网络(Recurrent Neural Network, RNN)神经元的历史输出参与下一次预测.
本文中我们将尝试使用RNN处理二进制加法问题: 两个加数作为两个序列输入, 从右向左处理加数序列.和的某一位不仅与加数的当前位有关, 还与上一位的进位有关.
词语的含义与上下文有关, 未来的状态不仅与当前相关还与历史状态相关. 因为这种性质, RNN非常适合自然语言处理和时间序列分析等任务.
RNN与前馈神经网络最大的不同在于多了一条反馈回路, 将RNN展开即可得到前馈神经网络.
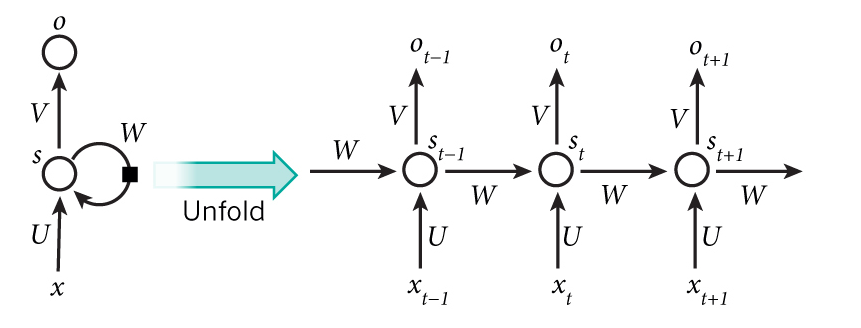
RNN同样采用BP算法进行训练, 误差反向传播时需要逆向通过反馈回路.
定义输出层误差为:
\]
其中, \(O_j\)是预测输出, \(T_j\)是参考输出.
因为隐含层没有参考输出, 采用下一层的误差加权和代替\(T_j - O_j\). 对于隐含层神经元而言这里的下一层可能是输出层, 也可能是其自身.
更多关于BP算法的内容可以参考BP神经网络与Python实现
定义RNN结构
完整的代码可以在rnn.py找到.
因为篇幅原因, 相关工具函数请在完整源码中查看, 文中不再赘述.
这里我们定义一个简单的3层递归神经网络, 隐含层神经元的输出只与当前状态以及上一个状态有关.
定义RNN类:
class RNN:
def __init__(self):
self.input_n = 0
self.hidden_n = 0
self.output_n = 0
self.input_weights = [] # (input, hidden)
self.output_weights = [] # (hidden, output)
self.hidden_weights = [] # (hidden, hidden)
def setup(self, ni, nh, no):
self.input_n = ni
self.hidden_n = nh
self.output_n = no
self.input_weights = make_rand_mat(self.input_n, self.hidden_n)
self.output_weights = make_rand_mat(self.hidden_n, self.output_n)
self.hidden_weights = make_rand_mat(self.hidden_n, self.hidden_n)
这里定义了几个比较重要的矩阵:
input_weights: 输入层和隐含层之间的连接权值矩阵.output_weights: 隐含层和输出层之间的连接权值矩阵hidden_weights: 隐含层反馈回路权值矩阵, 反馈回路从一个隐含层神经元出发到另一个隐含层神经元.
因为本文的RNN只有一阶反馈, 因此只需要一个反馈回路权值矩阵.对于n阶RNN来说需要n个反馈权值矩阵.
定义test()方法作为示例代码的入口:
def test(self):
self.setup(2, 16, 1)
for i in range(20000):
a_int = int(rand(0, 127))
a = int_to_bin(a_int, dim=8)
a = np.array([int(t) for t in a])
b_int = int(rand(0, 127))
b = int_to_bin(b_int, dim=8)
b = np.array([int(t) for t in b])
c_int = a_int + b_int
c = int_to_bin(c_int, dim=8)
c = np.array([int(t) for t in c])
guess, error = self.do_train([a, b], c, dim=8)
if i % 1000 == 0:
print("Predict:" + str(guess))
print("True:" + str(c))
print("Error:" + str(error))
out = 0
for index, x in enumerate(reversed(guess)):
out += x * pow(2, index)
print str(a_int) + " + " + str(b_int) + " = " + str(out)
result = str(self.predict([a, b], dim=8))
print(result)
print "==============="
do_train方法仅进行一次训练, 这里我们生成了20000组训练数据每组数据仅执行一次训练.
predict方法
predict方法执行一次前馈过程, 以给出预测输出序列.
def predict(self, case, dim=0):
guess = np.zeros(dim)
hidden_layer_history = [np.zeros(self.hidden_n)]
for i in range(dim):
x = np.array([[c[dim - i - 1] for c in case]])
hidden_layer = sigmoid(np.dot(x, self.input_weights) + np.dot(hidden_layer_history[-1], self.hidden_weights))
output_layer = sigmoid(np.dot(hidden_layer, self.output_weights))
guess[dim - i - 1] = np.round(output_layer[0][0]) # if you don't like int, change it
hidden_layer_history.append(copy.deepcopy(hidden_layer))
初始化guess向量作为预测输出, hidden_layer_history列表保存隐含层的历史值用于计算反馈的影响.
自右向左遍历序列, 对每个元素进行一次前馈.
hidden_layer = sigmoid(np.dot(x, self.input_weights) + np.dot(hidden_layer_history[-1], self.hidden_weights))
上面这行代码是前馈的核心, 隐含层的输入由两部分组成:
来自输入层的输入
np.dot(x, self.input_weights).来自上一个状态的反馈
np.dot(hidden_layer_history[-1], self.hidden_weights).
output_layer = sigmoid(np.dot(hidden_layer, self.output_weights))
guess[dim - position - 1] = np.round(output_layer[0][0])
上面这行代码执行输出层的计算, 因为二进制加法的原因这里对输出结果进行了取整.
train方法
定义train方法来控制迭代过程:
def train(self, cases, labels, dim=0, learn=0.1, limit=1000):
for i in range(limit):
for j in range(len(cases)):
case = cases[j]
label = labels[j]
self.do_train(case, label, dim=dim, learn=learn)
do_train方法实现了具体的训练逻辑:
def do_train(self, case, label, dim=0, learn=0.1):
input_updates = np.zeros_like(self.input_weights)
output_updates = np.zeros_like(self.output_weights)
hidden_updates = np.zeros_like(self.hidden_weights)
guess = np.zeros_like(label)
error = 0
output_deltas = []
hidden_layer_history = [np.zeros(self.hidden_n)]
for i in range(dim):
x = np.array([[c[dim - i - 1] for c in case]])
y = np.array([[label[dim - i - 1]]]).T
hidden_layer = sigmoid(np.dot(x, self.input_weights) + np.dot(hidden_layer_history[-1], self.hidden_weights))
output_layer = sigmoid(np.dot(hidden_layer, self.output_weights))
output_error = y - output_layer
output_deltas.append(output_error * sigmoid_derivative(output_layer))
error += np.abs(output_error[0])
guess[dim - i - 1] = np.round(output_layer[0][0])
hidden_layer_history.append(copy.deepcopy(hidden_layer))
future_hidden_layer_delta = np.zeros(self.hidden_n)
for i in range(dim):
x = np.array([[c[i] for c in case]])
hidden_layer = hidden_layer_history[-i - 1]
prev_hidden_layer = hidden_layer_history[-i - 2]
output_delta = output_deltas[-i - 1]
hidden_delta = (future_hidden_layer_delta.dot(self.hidden_weights.T) +
output_delta.dot(self.output_weights.T)) * sigmoid_derivative(hidden_layer)
output_updates += np.atleast_2d(hidden_layer).T.dot(output_delta)
hidden_updates += np.atleast_2d(prev_hidden_layer).T.dot(hidden_delta)
input_updates += x.T.dot(hidden_delta)
future_hidden_layer_delta = hidden_delta
self.input_weights += input_updates * learn
self.output_weights += output_updates * learn
self.hidden_weights += hidden_updates * learn
return guess, error
训练逻辑中两次遍历序列, 第一次遍历执行前馈过程并计算输出层误差.
第二次遍历计算隐含层误差, 下列代码是计算隐含层误差的核心:
hidden_delta = (future_hidden_layer_delta.dot(self.hidden_weights.T) +
output_delta.dot(self.output_weights.T)) * sigmoid_derivative(hidden_layer)
因为隐含层在前馈过程中参与了两次, 所以会有两层神经元反向传播误差:
- 输出层传递的误差加权和
output_delta.dot(self.output_weights.T) - 反馈回路中下一层隐含神经元传递的误差加权和
future_hidden_layer_delta.dot(self.hidden_weights.T)
将两部分误差求和然后乘自身输出的sigmoid导数sigmoid_derivative(hidden_layer)即为隐含层误差, 这里与普通前馈网络中的BP算法是一致的.
测试结果
执行test()方法可以看到测试结果:
Predict:[1 0 0 0 1 0 1 0]
True:[1 0 0 0 1 0 1 0]
123 + 15 = 138
===============
Error:[ 0.22207356]
Predict:[1 0 0 0 1 1 1 1]
True:[1 0 0 0 1 1 1 1]
72 + 71 = 143
===============
Error:[ 0.3532948]
Predict:[1 1 0 1 0 1 0 0]
True:[1 1 0 1 0 1 0 0]
118 + 94 = 212
===============
Error:[ 0.35634191]
Predict:[0 1 0 0 0 0 0 0]
True:[0 1 0 0 0 0 0 0]
41 + 23 = 64
预测精度还是很令人满意的.
Python实现RNN的更多相关文章
- Windows64 系统下Python、NumPy与matplotlib 安装方法
今下午想用Python跑RNN网络,结果代码在导入包numpy时并没有报错,但是在用里面的函数时报错,因小编也是新手,只学习了Python的基础语法,并没有使用过第三方包,安装了一下午还没弄好,本以为 ...
- tensorflow dynamic rnn源码分析
python3.6,tensorflow1.11 测试代码: tensorflow在eager模式下进行测试,方便调试,查看中间结果 import tensorflow as tf tf.enable ...
- Caffe、TensorFlow、MXnet三个开源库对比
库名称 开发语言 支持接口 安装难度(ubuntu) 文档风格 示例 支持模型 上手难易 Caffe c++/cuda c++/python/matlab *** * *** CNN ** MXNet ...
- Caffe、TensorFlow、MXnet三个开源库对比+主流分类模型对比
库名称 开发语言 支持接口 安装难度(ubuntu) 文档风格 示例 支持模型 上手难易 Caffe c++/cuda c++/python/matlab *** * *** CNN ** MXNet ...
- tensorflow代码中的一个bug
tensorflow-gpu版本号 pip show tensorflow-gpu Name: tensorflow-gpu Version: 1.11.0 Summary: TensorFlow i ...
- tensorflow BasicRNNCell调试
运行以下代码,进入~/anaconda3/lib/python3.5/site-packages/tensorflow/python/ops/rnn.py和~/anaconda3/lib/python ...
- Tensorflow.nn 核心模块详解
看过前面的例子,会发现实现深度神经网络需要使用 tensorflow.nn 这个核心模块.我们通过源码来一探究竟. # Copyright 2015 Google Inc. All Rights Re ...
- Recurrent Neural Network系列2--利用Python,Theano实现RNN
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- IMPLEMENTING A GRU/LSTM RNN WITH PYTHON AND THEANO - 学习笔记
catalogue . 引言 . LSTM NETWORKS . LSTM 的变体 . GRUs (Gated Recurrent Units) . IMPLEMENTATION GRUs 0. 引言 ...
随机推荐
- oracle学习 笔记(2)
题记:在使用Oracle数据库的时候,发现Oracle是没有自动增长列来实现主键的,所以在此记录学习.(PS:如果哪里有错误或者不足的地方还请大家帮忙指出来) 二.序列(自动增长列) 为此问题博主也是 ...
- 《C++之那些年踩过的坑(三)》
C++之那些年踩过的坑(三) 作者:刘俊延(Alinshans) 本系列文章针对我在写C++代码的过程中,尤其是做自己的项目时,踩过的各种坑.以此作为给自己的警惕. [版权声明]转载请注明原文来自:h ...
- js面向对象-原型链
var Person = function (name) { this.name = name; } Person.prototype.say = function () { console.log( ...
- linux系统各种乱码问题
linux系统乱码问题 最近使用ubuntu操作系统(客户端)在ssh连接linux服务器的时候发现乱码问题,但是本机查看中文显示中文没有问题,只是在使用终端more查看本地或远端gbk之类中文编码的 ...
- bootstrap-dialog插件的使用
官网文档:http://nakupanda.github.io/bootstrap3-dialog BootstrapDialog.show({ message: 'Hi Apple!', messa ...
- python 之分发包
setuptools python包的根目录设置setup.py from setuptools import setup, find_packages setup( name = 'm' versi ...
- React-native 初始化项目很慢
我是在Mac环境下,利用facebook开源的react-native创建原生app项目缓慢的问题 一:确定自己的环境配置是否有问题 二:打开终端,输入命令行 brew install wget 点击 ...
- Linux常用命令整理
1.常用命令:cd 进入 ls(list)查看当前目录下的文件 pwd 查看目录的路径 who an i 查看当前用户 clear 清除屏幕 2.绝对路径:从根目录开始\ 相对路径:上一层.下一层 ...
- 解析新浪微博表情包的一套js代码
本文出自本人原创,转载请注明出处 /** * Created by Lemon on 2017/4/6. *//** * return 解析后的值 * analysis 参数 * obj.value: ...
- word-wrap: break-word;与word-break: break-all;文本自动换行
word-break:break-all和word-wrap:break-word都是能使其容器如DIV的内容自动换行它们的区别就在于:1,word-break:break-all 例如div宽200 ...