浅析MySQL中的Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化
本文出处:http://www.cnblogs.com/wy123/p/7374078.html
(保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错误进行修正或补充,无他)
ICP优化原理
Index Condition Pushdown (ICP),也称为索引条件下推,体现在执行计划的上是会出现Using index condition(Extra列,当然Extra列的信息太多了,只能做简单分析)
ICP原理通俗讲就是,查询过程中,直接在查询引擎层的API获取数据的时候实现"非直接索引"过滤条件的筛选,而不是查询引擎层查询出来之后在Server层筛选。
换句话说就是ICP在获取数据的同时实现了where的次选条件中无法直接使用索引的情况下的筛选,避免了没有ICP优化的时候分两个步骤的实现(获取数据的过程没有做次选条件的过滤)
如果是非ICP优化查询的话,是两步,第一步是获取数据,第二步是获取的数据进行条件筛选。
显然,相比后者,前者可以一步实现索引的查找Seek+filter,效率上更高。
适应的场景:
ICP的优化策略可用于range、ref、eq_ref、ref_or_null 类型的访问数据方法
其实没有实例不太好理解这种优化策略,还是举两个实际列子吧。
ICP优化实例
第一个例子在网上非常多,也非常容易理解.具体表结构见上文(http://www.cnblogs.com/wy123/p/7366486.html)
下面用到的test_orderdetail表的索引为:create index idx_orderid_productname on test_orderdetail(order_id,product_name);
查询语句为:select * from test_orderdetail where order_id = 10900 and product_name like '%00163e0496af%';
显然,order_id = 10900是可以直接进行索引查找的,虽然product_name也包含在复合索引中,但是product_name like '%00163e0496af%'是无法使用索引的
观察其执行计划,发现Extra中是Using index condition。
ICP在这里的优化原理就是,
在利用第一个条件 order_id = 10900 进行索引查找的过程中,同时使用product_name like '%00163e0496af%'这个无法直接使用索引查找的条件进行过滤。
最终一步就可以筛选出来结果。

对比关闭ICP优化的情况
如果关闭ICP优化,执行计划的Extra显示为Using where,
意味着使用order_id = 10900进行索引查找之后,再对结果集进行product_name like '%00163e0496af%'的筛选

第二个例子是后面自己想的,为了验证ICP的出现场景,以及确实优于非ICP优化的情况
这一次使用的表是test_order,test_order上的索引为create index idx_userid_order_id_createdate on test_order(user_id,order_id,create_date);
查询语句为:select * from test_order where user_id = 500 and create_date > '2015-1-1';
与上面的例子一样,第二个筛选条件是无法直接使用索引的
首先看两者的执行计划在ICP优化上的区别

关闭ICP之后的执行计划

然后分别执在打开与关闭ICP的情况下,观察其执行过程中的profile信息
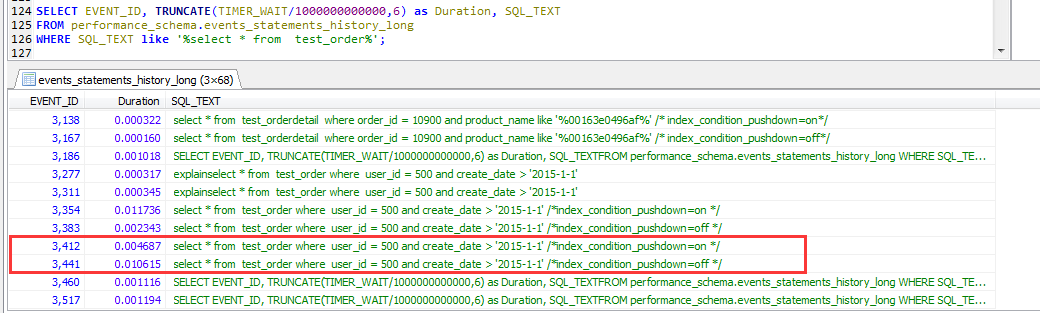
查看两个sql执行的详细信息,也即分别在打开与关闭ICP优化的情况下,如下,在stage/sql/Sending data环节有超过一个数量级的差异。
也就意味着通过ICP机制的优化,server 层和 engine 层之间数据交互的次数减少。
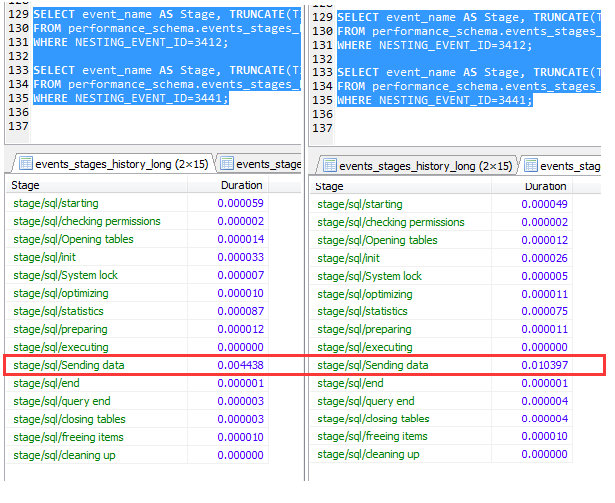
引用MySQL · 特性分析 · Index Condition Pushdown (ICP)中的一句话:
在二级索引是复合索引且前面的条件过滤性较低的情况下,打开 ICP 可以有效的降低 server 层和 engine 层之间交互的次数,从而有效的降低在运行时间。
最后,再思考一个问题,
对于select * from test_orderdetail where order_id = 10900 and product_name like '%00163e0496af%';这个查询,
如果order_id 包含在一个二级索引中,但是product_name 没有包含在这个二级索引中,MySQL会不会采用ICP的方式进行优化?
答案是否定的。
因为ICP的前提两个查询条件包被索引覆盖,但是次选条件无法直接使用索引查找,如果次选条件没有被索引覆盖,是无法得知次选条件的值的,也就无从 索引条件下推优化了。
Multi-Range Read(MRR)
非MRR优化下存在的问题:
首先了解一点背景知识:MySQL的Innodb表都是聚集索引表,没有显式指定聚集索引的情况下,会自动生成一个聚集索引。
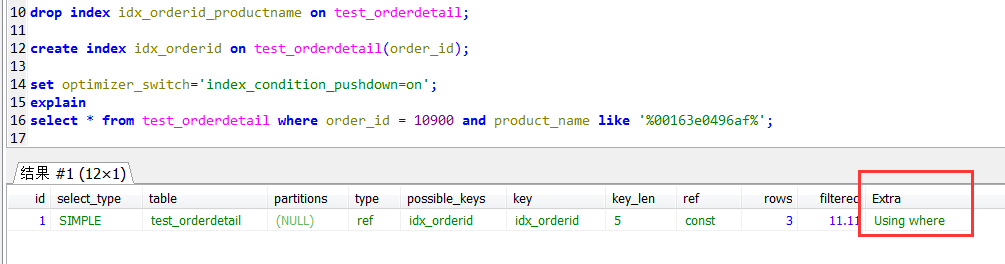
在使用二级索引(或者说是非聚集索引)进行范围查询的条件下,二级索引会根据其B树结构的叶子节点存储的聚集索引进行数据的查找(回表操作),
但是符合条件的数据(二级索引超找的数据)有可能是随机分布在聚集索引B树的任何一个部分,这样就可能存在表上过多的随机IO。
当表非常大的时候,每一行的查找过程都需要在磁盘上随机进行,可能会对性能造成影响。
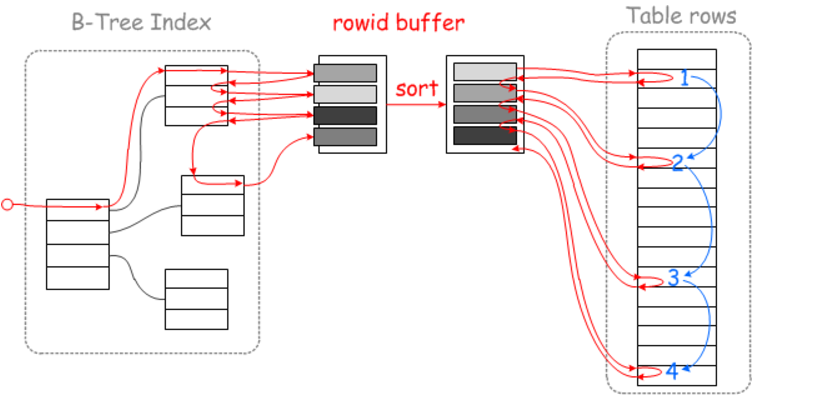
举个例子,
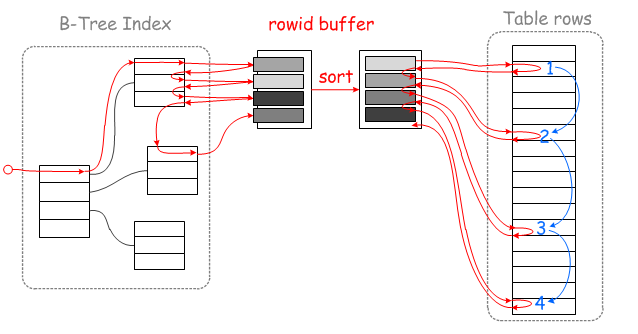
如下图,参考蓝线的移动轨迹,二级索引查找到的目标数据行的物理位置为1,2,3,4(主要的是以何种顺序去获取这四个位置的数据,可以随机的方式获取,也可以顺序的方式获取,讲究就在这一点)
在查找这四个位置的数据的时候,如果直接按照二级索引对应的聚集索引的顺序查找,
由于二级索引排序的情况下,其对应的聚集索引的顺序可能是随机的,那么其对应的数据的物理位置也就是随机的了
如果按照二级索引的顺去回表超找对应的数据行,那么这个过程就需要随机IO查找。
这种查询方式的缺点,可以理解为在查询这四行数据的过程中,在物理位置差异较大的情况下,需要磁头来回摆臂来实现(随机IO读取)。
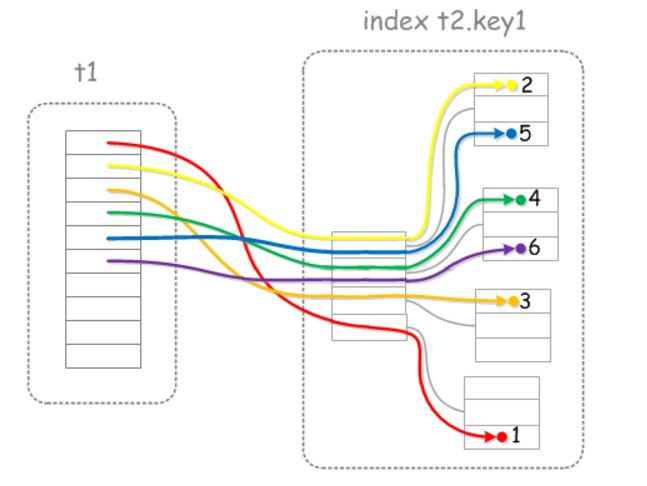
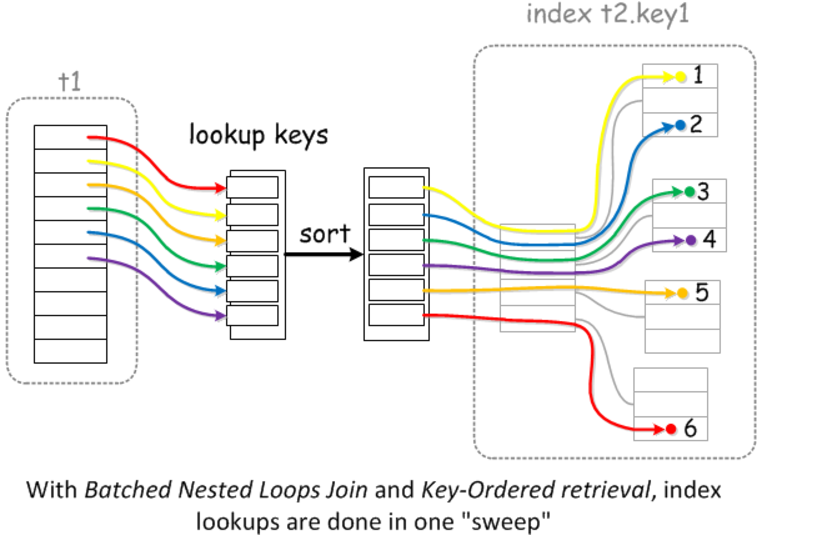
MRR多范围读取优化的目的是通过对记录的读取请求进行排序,然后再读取数据行的时候以顺序IO的方式进行,避免随机IO
究竟是对哪个字段排序?个人认为可以理解成二级索引范围查找到的对应的聚集索引的key值进行排序。
有序扫描的过程可以认为是:
(1)通过非聚集索引找到目标数据的聚集索引的key值
(2)对通过二级索引找到的目标数据的聚集索引的key值排序,此时聚集索引与物理位置一一对应。
(3)(回表的过程)通过二级索引对应的有序的聚集索引,执行一个有序的磁盘扫描来获取数据,从而来加快读取数据的速度。
顺序读磁盘通常会更快,当然也不是说这种方式的效率总是较高的,凡事有利必有弊,也有例外的情况
1,如果扫描的是一个较小的数据范围,并且目标数据已经在磁盘的缓存当中,MRR的唯一影响是为了缓冲/排序额外的增加了一些CPU开销。
2,order by *** LIMIT n查询,当n值比较小的时候,可能会变的更慢,
原因是 MRR试图通过顺序读盘的方式(来或取数据),可能一开始读取到的数据并非总是排在(order by ***)符合前N条的。
3,MRR是一个实现过程,个人理解,极端情况下,如果MySQL不知道目标数据的行数,
如果仅仅只有一行,依然要进行排序操作,然后回表读取数据行,这种情况下也是得不偿失的。
打开MRR优化
set global optimizer_switch = 'mrr=on,mrr_cost_based=off';
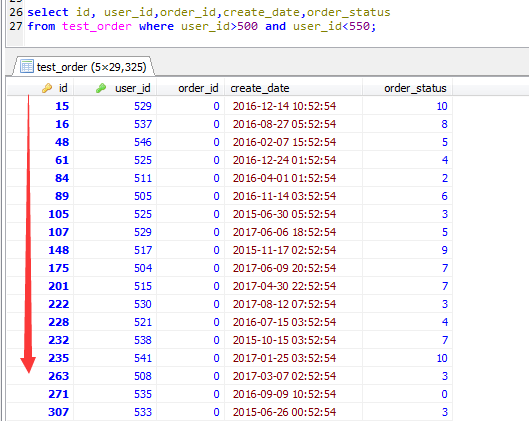
启用MRR优化的前提是要进行书签超找,也即要回表,如果不需要回表的话,二级索引本身就可以查询出来需要的字段了,没有随机IO的机会

如下截图,如果去掉order_status,也就意味着无需回表查询,那么久不会出现MRR优化了

同时,一旦出现MRR优化,查询出来的结果的顺序,必然是按照聚集索引来排序的,这个原理应该是不难理解的。
当然MRR优化也有在表关联情况下的优化措施,原理大同小异。
总结:
Index Condition Pushdown(索引条件下推)和Multi-Range Read(多范围读)都是MySQL为了提高查询优化而备用的选项,属于MySQL5.6里面的新特性。
无奈楼主接触MySQL不久,见识不够,很是觉得新鲜,高手勿喷。
两者的共同的特点都是在使用索引超找(或者索引范围扫描)的过程中的一些优化措施。
这些优化措施可以在二级索引查找(索引范围扫描)的过程中优化查询动作的行为,
当然这些优化措施并非总是万能的,允许用户显式打开或者关闭,给用户充分的自由,然而自由也并非完全没有问题,这也要求用户在做相关优化的时候需要进行充分的权衡和考虑。
参考:
https://mariadb.com/kb/en/mariadb/multi-range-read-optimization/
http://blog.itpub.net/22664653/viewspace-1673682/
http://blog.itpub.net/22664653/viewspace-1678779/
http://mysql.taobao.org/monthly/2015/12/08/
以及各种网上搜索……
最后,mariadb官方这几张图非常赞,对理解问题很有帮助,先盗下来,备用(无耻一笑,O(∩_∩)O~)
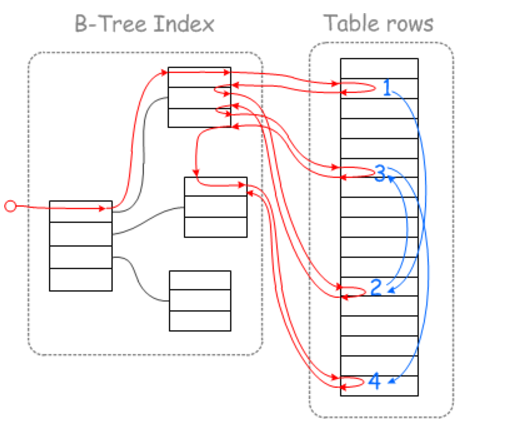
浅析MySQL中的Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化的更多相关文章
- MySQL 中Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化
一.ICP优化原理 Index Condition Pushdown (ICP),也称为索引条件下推,体现在执行计划的上是会出现Using index condition(Extra列,当然Extra ...
- MySQL 之 Index Condition Pushdown(ICP)
简介 Index Condition Pushdown (ICP)是MySQL 5.6 版本中的新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式. 当关闭ICP时,index 仅仅是data ...
- 【mysql】关于Index Condition Pushdown特性
ICP简介 Index Condition Pushdown (ICP) is an optimization for the case where MySQL retrieves rows from ...
- 8.2.1.5 Engine Condition Pushdown Optimization 引擎条件下推优化
8.2.1.5 Engine Condition Pushdown Optimization 引擎条件下推优化 这种优化改善了直接比较在一个非索引列和一个常量比较的效率. 在这种情况下, 条件是 下推 ...
- MySQL 5.6 Index Condition Pushdown
ICP(index condition pushdown)是mysql利用索引(二级索引)元组和筛字段在索引中的where条件从表中提取数据记录的一种优化操作.ICP的思想是:存储引擎在访问索引的时候 ...
- MySQL5.6之Index Condition Pushdown(ICP,索引条件下推)-Using index condition
http://blog.itpub.net/22664653/viewspace-1210844/ -- 这篇博客写的更细,以后看 ICP(index condition pushdown)是mysq ...
- MySQL中Index Condition Pushdown(ICP)优化
在MySQL 5.6开始支持的一种根据索引进行查询的优化方式.之前的MySQL数据库版本不支持ICP,当进行索引查询是,首先根据索引来查找记录,然后在根据WHERE条件来过滤记录.在支持ICP后,My ...
- MySQL Index Condition Pushdown(ICP) 优化
本文是作者留下的一个坑,他去上茅坑了.茅坑是谁?你猜.
- MySQL ICP(Index Condition Pushdown)特性
一.SQL的where条件提取规则 在ICP(Index Condition Pushdown,索引条件下推)特性之前,必须先搞明白根据何登成大神总结出一套放置于所有SQL语句而皆准的where查询条 ...
随机推荐
- 自己编写的 C++ 超轻量级日志类
[自己编写的 C++ 超轻量级日志类(兼容vc++6.0.vs2010.vs2015)] 先来看效果: [测试文件:test.cpp] /* 作者:闫文山 时间:2017/07/02 介绍: 本日志类 ...
- Spring Security Filter详解
Spring Security Filter详解 汇总 Filter 作用 DelegatingFilterProxy Spring Security基于这个Filter建立拦截机制 Abstract ...
- C# 中关于接口实现、显示实现接口以及继承
先列出我写的代码: 接口以及抽象类.实现类 public interface IA { void H(); } public interface IB { void H(); } public abs ...
- asp.net core新特性(1):TagHelper
进步,才是人应该有的现象.-- 雨果 今天开始,我就来说说asp.net core的新特性,今天就说说TagHelper标签助手.虽然学习.net,最有帮助的就是microsoft的官方说明文档了,里 ...
- Java自学手记——struts2
struts2框架 struts2是一种基于MVC模式的框架,是在struts1的基础上融合了xwork的功能. struts2框架预处理了一些功能: >请求数据自动封装, >文件上传的功 ...
- 学习java应该了解一些html超文本标记语言(前端)
在自己学习的过程中遇到一些内容,怕忘记所以借助博客加深印象也方便查找! html超文本标记语言中,分行级元素和块级元素. 行级元素的含义:行级元素不独占一行,相邻的行级元素在一行排列:行级元素可以控制 ...
- 使用css3实现小菊花加载效果
使用css3实现小菊花加载效果 最常见的就是我们用到的加载动画.加载动画的效果处理的好,会给页面带来画龙点睛的作用,而使用户愿意去等待.而页面中最常用的做法是把动画做成gif格式,当做背景图或是img ...
- PHP基础知识1
Php的变量和基本语法 1.变量/常量 2.Php数据类型和基本语法 基本语法 1. html和php混编 2. 一个语句以:(分号)结束 3. 如何定义一个变量.和变量的使用 4. ...
- java面向对象浅析
1.(了解) 面向对象 vs 面向过程 例子:人开门:把大象装冰箱 2.面向对象的编程关注于类的设计!1)一个项目或工程,不管多庞大,一定是有一个一个类构成的.2)类是抽象的,好比是制造汽车的图纸. ...
- MongoDB安全及身份认证
前面的话 本文将详细介绍MongoDB安全相关的内容 概述 MongoDB安全主要包括以下4个方面 1.物理隔离 系统不论设计的多么完善,在实施过程中,总会存在一些漏洞.如果能够把不安全的使用方与Mo ...