Coursera 机器学习笔记(三)
主要为第四周、第五周课程内容:神经网络
神经网络模型引入
之前学习的线性回归还是逻辑回归都有个相同缺点就是:特征太多会导致计算量太大。如100个变量,来构建一个非线性模型。即使只采用两两特征组合,都会有接近5000个组成的特征。这对于普通的线性回归和逻辑回归计算特征量太大了。因此,神经网路孕育而生。
神经网络最初产生的目的是制造能模拟大脑的机器,能很好地解决不同的机器学习问题。模型表示为:
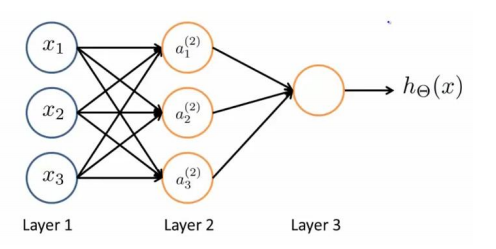
第一层为输入层,最后一层为输出层,中间的层为隐藏层。如把逻辑回归最为神经网络模型的神经元,a(j)I 代表第j层的第i个激活单元,θ(j)表示从第j层映射到第j+1层时的权重矩阵,其尺寸为第j+1层的激活单元数量为行数,第j层的激活单元数+1为列数的矩阵,如θ(1)尺寸为3*4。对于上图所示模型的表达为:
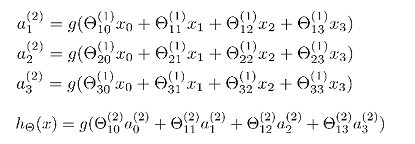
正向传播算法(Forward Propagation)
利用向量化的方法会使计算大为简便。计算上图第二层为例:

这只是针对训练集中一个训练实例所进行的计算。如果我们要对整个训练集进行计算,我们需要将训练集特征矩阵进行转置,使得同一个实例的特征都在同一列里。
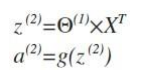
而计算第三层(输出层),可以把第二层看成是输入层,第三层为上述的第二层。

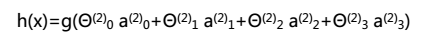
我们可以把 a0,a1,a2,a3看成更为高级的特征值,也就是 x0,x1,x2,x3的进化体,并且它们是由 x 与决定的,因为是梯度下降的,所以 a 是变化的,并且变得越来越厉害,所以这些更高级的特征值远比仅仅将 x 次方厉害,也能更好的预测新数据。
多分类
当我们有不止两种分类时(也就是 y=1,2,3….),比如以下这种情况,该怎么办?如y=4
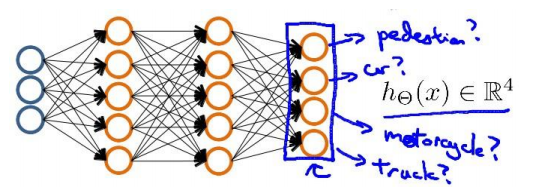
利用one-vs-all思想:神经网络算法的输出结果为四种可能情形之一

代价函数
引入标记表示方法:
- L代表神经网络的层数
- Si代表第i层的处理单元(包括偏见单元)的个数
- SL代表最后一层中的处理单元的个数
- K代表希望分类的个数,与SL相等
逻辑回归中的代价函数为:
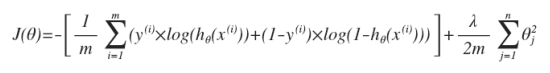
逻辑回归中只有一个输出变量,而在神经网络中有很多输出变量,h(x) 是个一个维度为K的向量,因此因变量也是一个维度为K的向量。神经网络相应的代价函数为:
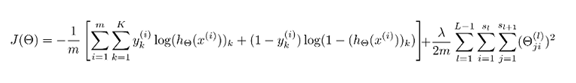
反向传播算法
综合
网络结构:
第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多少个单元。
- 第一层的单元数即我们训练集的特征数量
- 最后一层的单元数是我们训练集的结果的类的数量
- ,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好
我们真正要决定的是隐藏层的层数和每个中间层的单元数。
训练神经网络:
1. 参数的随机初始化
2. 利用正向传播方法计算所有的 hθ(x)
3. 编写计算代价函数 J 的代码
4. 利用反向传播方法计算所有偏导数
5. 利用数值检验方法检验这些偏导数
6. 使用优化算法来最小化代价函数
Coursera 机器学习笔记(三)的更多相关文章
- coursera机器学习笔记-建议,系统设计
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-多元线性回归,normal equation
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-机器学习概论,梯度下降法
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-神经网络,学习篇
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-神经网络,初识篇
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- Coursera 机器学习笔记(八)
主要为第十周内容:大规模机器学习.案例.总结 (一)随机梯度下降法 如果有一个大规模的训练集,普通的批量梯度下降法需要计算整个训练集的误差的平方和,如果学习方法需要迭代20次,这已经是非常大的计算代价 ...
- Coursera 机器学习笔记(六)
主要为第八周内容:聚类(Clustering).降维 聚类是非监督学习中的重要的一类算法.相比之前监督学习中的有标签数据,非监督学习中的是无标签数据.非监督学习的任务是对这些无标签数据根据特征找到内在 ...
- Coursera 机器学习笔记(四)
主要为第六周内容机器学习应用建议以及系统设计. 下一步做什么 当训练好一个模型,预测未知数据,发现结果不如人意,该如何提高呢? 1.获得更多的训练实例 2.尝试减少特征的数量 3.尝试获得更多的特征 ...
- Coursera 机器学习笔记(七)
主要为第九周内容:异常检测.推荐系统 (一)异常检测(DENSITY ESTIMATION) 核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非 ...
随机推荐
- CF #CROC 2016 - Elimination Round D. Robot Rapping Results Report 二分+拓扑排序
题目链接:http://codeforces.com/contest/655/problem/D 大意是给若干对偏序,问最少需要前多少对关系,可以确定所有的大小关系. 解法是二分答案,利用拓扑排序看是 ...
- es6面试问题——Promise
话说刚换工作一个月有余,在上家公司干的实在是不开心,然后就出来抱着试试的心态出来面了几家公司,大多数公司问的前端问题也就那么多,其中有个面试问题让我记忆犹新,只因为没有答上来,哈哈! 当时面试官问我怎 ...
- .NET 二维码生成(ThoughtWorks.QRCode)【转发jiangys】
.NET 二维码生成(ThoughtWorks.QRCode) 2015-06-21 22:19 by jiangys, 3790 阅读, 8 评论, 收藏, 编辑 引用ThoughtWorks.QR ...
- Javascript一道面试题
实现一个函数,运算结果可以满足如下预期结果: add(1)(2) // 3add(1, 2, 3)(10) // 16 add(1)(2)(3)(4)(5) // 15 function add () ...
- Oracle数据泵(上)
导出 (以导出表空间为例) 1.给用户创建密码 alter user system identified by 00000000; 2.创建导出目录 create or replace dire ...
- JQuery 中关于插入新元素的方法
关于JQuery插入新内容的方法: append() - 在被选元素的结尾插入内容 prepend() - 在被选元素的开头插入内容 after() - 在被选元素之后插入内容 before() - ...
- http工具类
/** * 发送post请求工具方法 * * @Methods Name HttpPost * @Create In 2014年10月28日 By wangfei * @param url * @pa ...
- Git总结笔记3-把本地仓库推送到github
说明:此笔记在centos 7 上完成 1.配置公钥 [root@kangvcar ~]# ssh-keygen -t rsa -C "kangvcar@126.com" [roo ...
- java内存模型1
并发编程模型的分类 在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体).通信是指线程之间以何种机制来交换信息.在命令式编程中,线程之间的通信 ...
- VR全景加盟-全景智慧城市携万千创业者决战BAT
在所谓互联网思维走到末路.可穿戴设备基本昙花一现的大环境下,很多互联网人员转战VR市场,自然喜欢用互联网思维来考虑.笔者认识一些投资界人士,在谈到投资时,他们经常就问以下几句话:2B还是2C?将来有多 ...