Hbase Rowkey设计原则
Hbase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这三个维度可以对HBase中的数据进行快速定位。
Hbase中Rowkey可以唯一标识一行记录,在Hbase查询的时候,有以下几种方式:
1、通过get方式,指定rowkey获取唯一一条记录
2、通过scan方式,设置StartRow和EndRow参数进行范围匹配
3、全表扫描,即直接扫描整张表中所有行记录
Rowkey长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度 64kb ,实际应用中一般为10-100bytes,以 byte[] 形式保存,一般设计成定长。
建议越短越好,不要超过16个字节,原因如下:
- 数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
- MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
- 目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
rowkey散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
什么是热点
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
常见的避免热点的方法以及它们的优缺点:
1、盐析
在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
2、哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
3、反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
4、时间戳反转
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到key的末尾,例如 [key][reverse_timestamp] , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。
比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计
[userId反转][Long.Max_Value - timestamp],在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是[userId反转][000000000000],stopRow是[userId反转][Long.Max_Value - timestamp]
如果需要查询某段时间的操作记录,startRow是[user反转][Long.Max_Value - 起始时间],stopRow是[userId反转][Long.Max_Value - 结束时间]
5、建表时进行预分区处理
默认情况下,在创建Hbase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个Region写数据,知道这个Region足够大了才进行切分。我们通过预先创建一些空的Regions,这样当数据写入Hbase时,会按照region分区情况,在集群内做数据的负载均衡。
1、命令方式:
# create table with specific split points
hbase>create 'table1','f1',SPLITS => ['\x10\x00', '\x20\x00', '\x30\x00', '\x40\x00']
# create table with four regions based on random bytes keys
hbase>create 'table2','f1', { NUMREGIONS => 8 , SPLITALGO => 'UniformSplit' }
# create table with five regions based on hex keys
hbase>create 'table3','f1', { NUMREGIONS => 10, SPLITALGO => 'HexStringSplit' }
2、API方式
hbase org.apache.hadoop.hbase.util.RegionSplitter test_table HexStringSplit -c 10 -f info hbase org.apache.hadoop.hbase.util.RegionSplitter splitTable HexStringSplit -c 10 -f info
参数:
test_table 是表名
HexStringSplit 是split 方式
-c 是分 10 个 region
-f 是 family
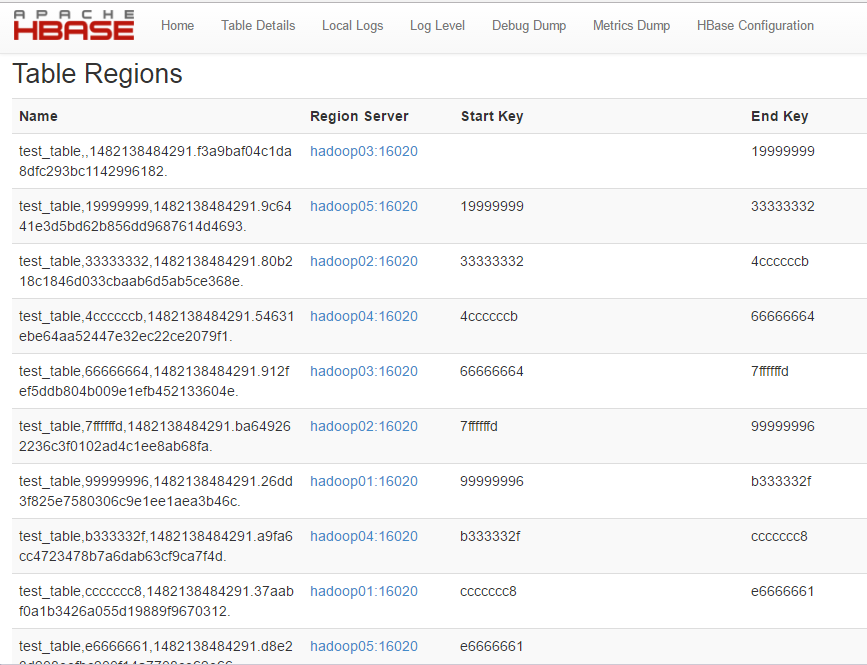
这样就可以将表预先分为 10 个区,减少数据达到 storefile 大小的时候自动分区的时间 消耗,并且还有以一个优势,就是合理设计 rowkey 能让各个 region 的并发请求平均分配(趋 于均匀) 使 IO 效率达到最高,但是预分区需要将 filesize 设置一个较大的值,设置哪个参数 呢 hbase.hregion.max.filesize 这个值默认是 10G 也就是说单个 region 默认大小是 10G
这个参数的默认值在 0.90 到 0.92 到 0.94.3 各版本的变化:256M--1G--10G
但是如果 MapReduce Input 类型为 TableInputFormat 使用 hbase 作为输入的时候,就要注意 了,每个 region 一个 map,如果数据小于 10G 那只会启用一个 map 造成很大的资源浪费, 这时候可以考虑适当调小该参数的值,或者采用预分配 region 的方式,并将检测如果达到 这个值,再手动分配 region。
Hbase Rowkey设计原则的更多相关文章
- Hadoop生态圈-Hbase的rowKey设计原则
Hadoop生态圈-Hbase的rowKey设计原则 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hbase rowkey设计+布隆过滤器+STORE FILE & HFILE结构
Rowkey设计 Rowkey设计原则 Rowkey设计应遵循以下原则: 1.Rowkey的唯一原则 必须在设计上保证其唯一性.由于在HBase中数据存储是Key-Value形式,若HBase中同一表 ...
- HBase的RowKey设计原则
HBase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这个三个维度可以对HBase中的数据进行快速定 ...
- Hbase Rowkey设计
转自:http://www.bcmeng.com/hbase-rowkey/ 建立Schema Hbase 模式建立或更新可以通过 Hbase shell 工具或者使用Hbase Java API 中 ...
- rowkey设计原则和方法
rowkey设计首先应当遵循三大原则: 1.rowkey长度原则 rowkey是一个二进制码流,可以为任意字符串,最大长度为64kb,实际应用中一般为10-100bytes,它以byte[]形式保存, ...
- HBase Rowkey 设计指南
为什么Rowkey这么重要 RowKey 到底是什么 我们常说看一张 HBase 表设计的好不好,就看它的 RowKey 设计的好不好.可见 RowKey 在 HBase 中的地位.那么 RowKey ...
- Hbase rowkey设计一
转自 http://blog.csdn.net/lifuxiangcaohui/article/details/40621067 hbase所谓的三维有序存储的三维是指:rowkey(行主键),col ...
- HBase总结(十八)Hbase rowkey设计一
hbase所谓的三维有序存储的三维是指:rowkey(行主键),column key(columnFamily+qualifier),timestamp(时间戳)三部分组成的三维有序存储. 1.row ...
- hbase rowkey 设计
HBase中的rowkey是按字典顺序排序的,通过rowkey查询可以对千万级的数据实现毫秒级响应.然而,如果rowkey设计不合理的话经常会出现一个很普遍的问题----热点.当大量client的请求 ...
随机推荐
- PyQt学习随笔:Model/View设计中支持视图中数据修改的方法及步骤
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 要支持视图中的数据可以修改,需要两个步骤: 1. 在视图中设置editTriggers属性支持在视图 ...
- 凌乱的与ctf无关的小知识点
(1)在网页中一般不要用记住密码.否则想要知道你的密码很简单. 例子:看样子很安全,别人无法通过这些来获得你的其他密码(尤其是想我这样密码强度不高的人),但是知道要修改前端的选项,你的密码就会被暴露. ...
- 【Kubernetes学习笔记】-kubeadm 手动搭建kubernetes 集群
目录 K8S 组件构成 环境准备 (以ubuntu系统为例) 1. kubernetes集群机器 2. 安装 docker. kubeadm.kubelet.kubectl 2.1 在每台机器上安装 ...
- Scrum 冲刺 第四篇
Scrum 冲刺 第四篇 每日会议照片 昨天已完成工作 队员 昨日完成任务 黄梓浩 初步完成app项目架构搭建 黄清山 完成部分个人界面模块数据库的接口 邓富荣 完成部分后台首页模块数据库的接口 钟俊 ...
- 全国11省市出台区块链专项政策,Panda Global发现 "区块链+政务"被寄予厚望!
2020年已经过半,回顾2020年的上半年,不难发现其实区块链的变化非常大,今天Panda Global就给大家回顾下上半年全国关于区块链政策的发布情况.今年上半年,全国已有11个省市出台区块链专项政 ...
- 【Codeforces 809E】Surprise me!(莫比乌斯反演 & 虚树)
Description 给定一颗 \(n\) 个顶点的树,顶点 \(i\) 的权值为 \(a_i\).求: \[\frac{1}{n(n-1)}\sum_{i=1}^n\sum_{j=1}^n\var ...
- 解压版mysql+免破解版Navicat,好用!
解压版mysql安装流程 获取mysql压缩包 获取地址: 链接:https://pan.baidu.com/s/1HqdFDQn_6ccPM0gOftApIg 提取码:n19t 获取压缩包后可安装压 ...
- VMware 虚拟机网卡设置与外网访问
1 查看虚拟机网卡设置,查看虚拟机网关. 2 然后,设置本地机器VMnet8网卡的IP地址和子网掩码.切记,IP地址不能与虚拟机网卡IP地址相同. 3 配置虚拟机Centos的ens33网卡 TYPE ...
- C++异常之四 异常类型的生命周期
异常类型的生命周期 1. throw 基本类型: int.float.char 这三种类型的抛出和函数的返回传值类似,为参数拷贝的值传递. 1 int test_1(int num) throw (i ...
- PHP代码审计学习-PHP-Audit-Labs-day1
0x01 前言 偶然间看到红日团队的PHP代码审计教程,想起之前立的flag,随决定赶紧搞起来.要不以后怎么跟00后竞争呢.虽然现在PHP代码审计不吃香,但是php代码好歹能看懂,CTF中也经常遇到, ...