2. RDD(弹性分布式数据集Resilient Distributed dataset)
*以下内容由《Spark快速大数据分析》整理所得。
读书笔记的第二部分是讲RDD。RDD 其实就是分布式的元素集合。在 Spark 中,对数据的所有操作不外乎创建RDD、转化已有RDD以及调用RDD操作进行求值。而在这一切背后,Spark 会自动将RDD中的数据分发到集群上,并将操作并行化执行。
一、创建RDD
二、操作RDD
1. 普通RDD转化操作
2. Pair RDD转化操作
3. 普通RDD行动操作
4. Pair RDD行动操作
一、创建RDD
创建RDD两种方式:
(1) 读取外部数据集:例如读取字符串 lines=sc.textFile("/path/to/README.md")
(2) 在驱动器程序中对一个集合进行并行化(适用于开发原型和测试,用的不多,因为会将数据先存入内存中): lines=sc.parallelize(["pandas","i like pandas"])
二、操作RDD
RDD支持两种类型的操作:转化操作(transformation)和行动操作(action)。
- 转化操作:由一个RDD生成一个新的RDD。
- 行动操作:对RDD计算出结果。
转化出的RDD是惰性求值的,只有在行动操作中用到这些RDD才会被计算。
为了更好解释RDD操作,我们先走一遍Spark程序或shell会话就行了:
# step1: 从外部数据创建出输入RDD
lines = sc.textFile("README.md")
# step2: 使用如filter()这样的转化操作对RDD进行转化,以定义新的RDD
pythonLines = lines.filter(lambda line: "Python" in line)
# step3: 告诉Spark对需要被重用的中间结果RDD执行persist()操作
# 注:RDD.persist():让Spark把这个RDD缓存下来,使得在多个行动操作中能重用同一个RDD。
pythonLines.persist()
# step4: 使用行动操作(如count()和first()等)来触发一次并行计算,Spark会对计算进行优化后再执行。
pythonLines.count()
或
pythonLines.first()
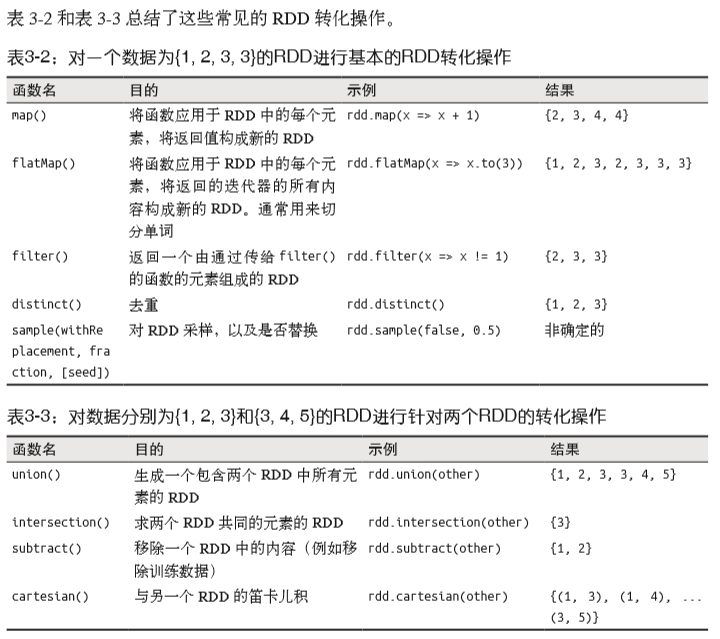
1. 普通RDD转化操作:
(1.1) map: 用于RDD每个函数,返回结果作为RDD中对应的值。
# 计算RDD中各值的平方
nums = sc.parallelize([1,2,3,4]) # 创建一个RDD
squared = nums.map(lambda x: x * x).collect() # 获得所有计算平方值的结果
for num in squared:
print "%i " % (num)
(1.2) flapMap: 将返回的迭代器”拍扁“。
# 将行数据切分为单词:
lines = sc.parallelize(["hello world", "hi"])
words = lines.map(lambda line: line.split(" "))
word.first() # 返回["hello", "world"]
words = lines.flapMap(lambda line: line.split(" "))
word.first() # 返回"hello"
(1.3) 集合操作:有 distinct(), union(), intersection(), subtract() ,笛卡尔积 cartesian() 。
2. Pair RDD转化操作
Pair RDD转化操作:pair RDD是键值对类型的RDD - 由(键,值)二元组组成。

(2.1) 聚合操作:
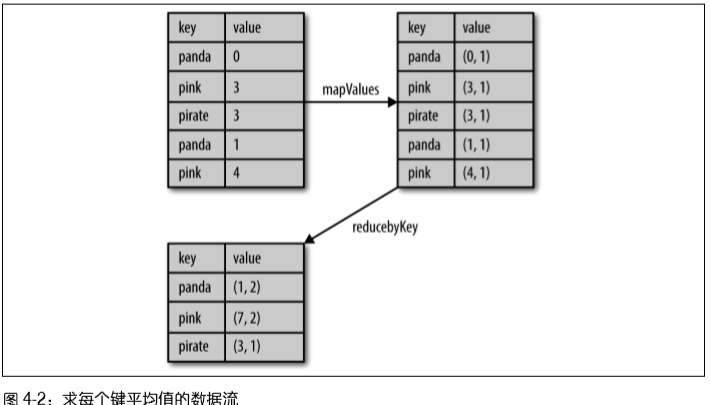
例子1 - 图4-2:计算每个键对应的平均值方法1:用reduceByKey()和mapValues()
rdd.mapValues(lambda x: (x, 1)).reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))
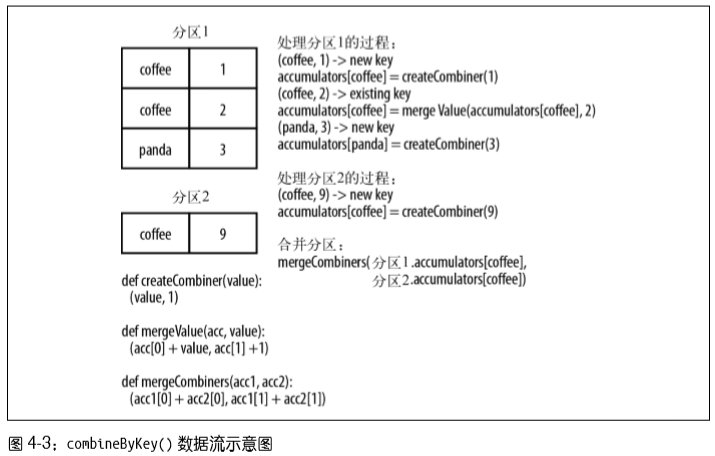
例子2 - 图4-3:计算每个键对应的平均值方法2:用combineByKey()
sumCount = nums.combineByKey((lambda x: (x, 1)),
(lambda x, y: (x[0] + y, x[1] + 1)),
(lambda x, y: (x[0] + y[0], x[1] + y[1])))
sumCount.map(lambda key, xy: (key, xy[0]/xy[1])).collectAsMap()
例子3:单词计数方法1
rdd = sc.textFile("s3://...")
words = rdd.flatMap(lambda x: x.split(" "))
result = words.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
例子4:单词计数方法2
result= rdd.flatMap(lambda x: x.split(" ")).countByValue()
(2.2) 数据分组:
- groupByKey() : 使用RDD的键对数据进行分组。对于一个有类型K的键和类型V的值组成的RDD,所得结果RDD类型会是[K, Iterable[V]].
- cogroup() : 对多个共享同一个键的RDD进行分组,对两个键的类型均为K,而值的类型分别为V和W的RDD进行cogroup(),得到结果是[K, (Iterable[V], Iterable[W])]。
(2.3) 连接
支持右外连接、左外连接、交叉连接以及内连接: leftOuterJoin(), rightOuterJoin() 和 join() 。
(2.4) 排序
例:以字符串顺序对整数进行自定义升序排序
rdd.sortByKey(ascending=True, numPartitions=None, keyfunc=lambda x: str(x))
3. 普通RDD行动操作
- count() :返回计数结果。
- take() : 收集RDD中的一些元素,然后方便在本地遍历这些元素。
- collect() : 获取整个RDD中的数据,前提是整个数据集在放的进内存,不建议在大规模数据上使用。
例子:
print "Input had " + badLinesRDD.count() + " concerning lines"
print "Here are 10 examples:"
for line in badLinesRDD.take(10):
print line
4. Pair RDD行动操作

2. RDD(弹性分布式数据集Resilient Distributed dataset)的更多相关文章
- RDD(弹性分布式数据集)及常用算子
RDD(弹性分布式数据集)及常用算子 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据 处理模型.代码中是一个抽象类,它代表一个 ...
- RDD弹性分布式数据集的基本操作
RDD的中文解释是弹性分布式数据集.构造的数据集的时候用的是List(链表)或者Array数组类型/* 使用makeRDD创建RDD */ /* List */ val rdd01 = sc.make ...
- 第1章 RDD概念 弹性分布式数据集
第1章 RDD概念 弹性分布式数据集 1.1 RDD为什么会产生 RDD是Spark的基石,是实现Spark数据处理的核心抽象.那么RDD为什么会产生呢? Hadoop的MapReduce是一种基于 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- Scala当中什么是RDD(Resilient Distributed Datasets)弹性分布式数据集
RDD(Resilient Distributed Datasets)弹性分布式数据集.你不好理解的话,可以把RDD就可以看成是一个简单的"动态数组"(比如ArrayList),对 ...
- Spark - RDD(弹性分布式数据集)
org.apache.spark.rddRDDabstract class RDD[T] extends Serializable with Logging A Resilient Distribut ...
- Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
http://blog.csdn.net/pipisorry/article/details/53257188 弹性分布式数据集RDD(Resilient Distributed Dataset) 术 ...
随机推荐
- postgresql 和 mysql 数据库备份恢复以及时区问题
概要 postgesql 12 备份/恢复脚本 时区设置 mysql 5.6 备份/恢复脚本 时区设置 概要 postgresql 和 mysql 是最常用的 2 种开源关系数据库, 很多项目也会优先 ...
- 多测师讲解selenium_iframe框定位_高级讲师肖sir
iframe 框定位方法: 查看iframe框 京东点击登录定位元素 定位qq: qq登录定位的元素 查找iframe框 定位iframe框 from selenium import webdrive ...
- 多测师讲解htm_L标题标签001_高级讲师 肖sir
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>百 ...
- IdentityServer 3.1.x 迁移到 4.x
一.前言 IdentityServer4 4.x已经正式发布了,根据官方的 Release Note,3.1.x 到 4.x 的变更也是非常多,今天在将代码迁移到 4.x 遇到了一些问题在此记录下来, ...
- 《Kafka笔记》1、Kafka初识
目录 一.初识Kafka 1 apache kafka简介 2 消息中间件kafka的使用场景 2.1 订阅与发布队列 2.2 流处理 3 kafka对数据的管理形式 4 kafka基础架构 5 Ka ...
- Windows Server 2003 Enterprise Edition SP2
SN: MPQ6X-3MCCF-47H9T-TKC2F-T69WM
- Spring 缓存抽象
Spring从3.1开始定义了org.springframework.cache.Cache和org.springframework.cache.CacheManager接口来统一不同的缓存技术:并支 ...
- 没事学些KVM(三)虚拟机基础管理
创建完成虚拟机后,需要对虚拟机进行基础管理学习 virsh list #查看虚拟机列表 改命令只能查看正在运行或挂起的虚拟机 如果需要查看所有的虚拟机需要添加--all 参数 virsh start ...
- ssm整合之springmvc.xml文件
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.spr ...
- RestTemplate+Ribbon实现服务调用
一,通过LoadBalancerClient取得uri,然后RestTemplate 调用 1, 注入LoadBalancerClient @Autowired LoadBalancerClient ...