MapReduce编程练习(四),统计多个输入文件学生的平均成绩,
问题描述:
在输入文件中,有多个,其中每个输入文件代表一个学生的各科成绩,其中每行的数据形式为<科目,成绩>,你需要将每个文件中的每科目的成绩进行统计,然后求平均值。
输入文件格式:
这里有三个学生:
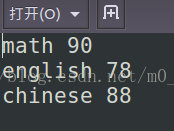
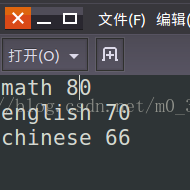
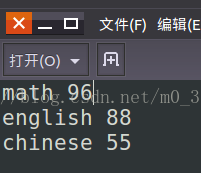
输出文件格式:
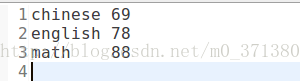
实例代码:
package com.test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class StudentAverage {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
@SuppressWarnings("deprecation")
Job job = new Job(new Configuration(), "StudentAverage");
job.setJarByClass(StudentAverage.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/Student/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/Student/output"));
job.waitForCompletion(true);
System.out.println("运行结束!");
}
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable>{
protected void map(LongWritable key, Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws java.io.IOException, InterruptedException {
String[] data = value.toString().split(" ");
context.write(new Text(data[0]), new IntWritable(Integer.parseInt(data[1])));
};
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text key, java.lang.Iterable<IntWritable> values, Context context)
throws java.io.IOException, InterruptedException {
int average = 0;
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
average = sum / 3;
context.write(new Text(key), new IntWritable(average));
};
}
}
MapReduce编程练习(四),统计多个输入文件学生的平均成绩,的更多相关文章
- YTU 2626: B 统计程序设计基础课程学生的平均成绩
2626: B 统计程序设计基础课程学生的平均成绩 时间限制: 1 Sec 内存限制: 128 MB 提交: 427 解决: 143 题目描述 程序设计基础课程的学生成绩出来了,老师需要统计出学生 ...
- 问题 C: B 统计程序设计基础课程学生的平均成绩
题目描述 程序设计基础课程的学生成绩出来了,老师需要统计出学生个数和平均成绩.学生信息的输入如下: 学号(num) 学生姓名(name) ...
- MapReduce编程:词频统计
首先在项目的src文件中需要加入以下文件,log4j的内容为: log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j ...
- MapReduce编程实例4
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- MapReduce编程实例2
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- MapReduce编程实例6
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例5
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例3
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- 假期学习【五】RDD编程实验四
今天完成了实验四的第二问和第三问 第二题 对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其 中重复的内容,得到一个新文件 C.下面是输入文件和输出文件的一个样 ...
随机推荐
- java数组之binarySearch查找
/** * 1.如果找到目标对象则返回<code>[公式:-插入点-1]</code> * 插入点:第一个大与查找对象的元素在数组中的位置,如果数组中的所有元素都小于要查找的对 ...
- 再看C语言-算法
通常一个程序包括算法.数据结构.程序设计方法及语言工具和环境这四个方面.其中算法是核心,算法就是解决"做什么"和"如何做"的问题.算法是程序的灵魂,项目中如果接 ...
- 10. C++对象模型和 this 指针
1. 成员变量和成员函数分开存储 在C++中,类内的成员变量和成员函数分开存储,只有非静态成员变量才属于类的对象上 空对象占用内存空间为:1 ----> C++编译器会给每个空对象也分配一个字节 ...
- 风炫安全WEB安全学习第十九节课 XSS的漏洞基础知识和原理讲解
风炫安全WEB安全学习第十九节课 XSS的漏洞基础知识和原理讲解 跨站脚本攻击(Cross-site scripting,通常简称为XSS) 反射型XSS原理与演示 交互的数据不会存储在数据库里,一次 ...
- 查找linux系统下的端口被占用进程的两种方法 【转】
在linux下开发时,你的软件可能要使用某一个端口,或者想查找某一个端口是否被占用.需要怎么做呢??这的确是一个比较烦恼的问题,我也此为这个苦恼过.但是通过查找man手册,还是同事的交流.总结出来两种 ...
- 【C++】《Effective C++》第二章
第二章 构造/析构/赋值运算 条款05:了解C++默默编写并调用哪些函数 默认函数 一般情况下,编译器会为类默认合成以下函数:default构造函数.copy构造函数.non-virtual析构函数. ...
- Docker学习笔记之向服务器部署应用程序
部署的应用仅仅是简单应用程序,使用的是node管理的web应用,具体我也不是很会,当然也可以配置tomcat服务器.这里主要是学习docker.需要客户机和服务机,其中服务机必须要为Linux操作系统 ...
- L(kali)A(apache)M(mysql)P(php)环境+wordpress站点搭建
一:LAMP环境配置 首先LAMP(linux+apache+mysql+php)即为本次搭建网站所需的环境,由于本次使用的debian衍生版kali版本自带lamp,因此只要在服务器上启动相应服务既 ...
- 【Vue】Vue框架常用知识点 Vue的模板语法、计算属性与侦听器、条件渲染、列表渲染、Class与Style绑定介绍与基本的用法
Vue框架常用知识点 文章目录 Vue框架常用知识点 知识点解释 第一个vue应用 模板语法 计算属性与侦听器 条件渲染.列表渲染.Class与Style绑定 知识点解释 vue框架知识体系 [1]基 ...
- zabbix自动发现主机并注册