Mapreduce之排序&规约&实战案例
MapReduce 排序和序列化
简单介绍
①序列化 (Serialization) 是指把结构化对象转化为字节流
②反序列化 (Deserialization) 是序列化的逆过程. 把字节流转为结构化对象. 当要在进程间传
递对象或持久化对象的时候, 就需要序列化对象成字节流, 反之当要将接收到或从磁盘读取
的字节流转换为对象, 就要进行反序列化
③Java 的序列化 (Serializable) 是一个重量级序列化框架, 一个对象被序列化后, 会附带很多额
外的信息 (各种校验信息, header, 继承体系等), 不便于在网络中高效传输. 所以, Hadoop
自己开发了一套序列化机制(Writable), 精简高效. 不用像 Java 对象类一样传输多层的父子
关系, 需要哪个属性就传输哪个属性值, 大大的减少网络传输的开销
④Writable 是 Hadoop 的序列化格式, Hadoop 定义了这样一个 Writable 接口. 一个类要支持可
序列化只需实现这个接口即可
⑤另外 Writable 有一个子接口是 WritableComparable, WritableComparable 是既可实现序列
化, 也可以对key进行比较, 我们这里可以通过自定义 Key 实现 WritableComparable 来实现
我们的排序功能
实战案例
数据格式如下

要求:
第一列按照字典顺序进行排列
第一列相同的时候, 第二列按照升序进行排列
解决思路:
将 Map 端输出的 <key,value> 中的 key 和 value 组合成一个新的 key (newKey), value值
不变
这里就变成 <(key,value),value> , 在针对 newKey 排序的时候, 如果 key 相同, 就再对
value进行排序
Step 1. 自定义类型和比较器
package cn.itcast.mapreduce.sort; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; public class SortBean implements WritableComparable<SortBean> {
private String word;
private int num; public String getWord() {
return word;
} public void setWord(String word) {
this.word = word;
} public int getNum() {
return num;
} public void setNum(int num) {
this.num = num;
} @Override
public String toString() {
return word + '\t' + num ;
} //实现比较器,指定排序规则
/*
规则:
第一列:按照字典顺序进行排列
第二列:当第一列相同,num按照升序进行排列
*/
@Override
public int compareTo(SortBean o) {
//先对第一列排序
int result = this.word.compareTo(o.word);
//如果第一列相同,则按照第二列排序
if(result==0)
{
return this.num-o.num;
}
return result;
}
//实现序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(word);
dataOutput.writeInt(num);
} //实现反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
this.word=dataInput.readUTF();
this.num=dataInput.readInt();
}
}
Step 2. Mapper
package cn.itcast.mapreduce.sort; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class SortMapper extends Mapper<LongWritable, Text,SortBean, NullWritable> { /*
将我们的K1和V1转为K2和V2
K1 v1
0 a 3
5 b 7
-----------------
K2 V2
SortBean(a 3) Nullwritable
SortBean(b 7) NullWritable
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.将V1行文本数据拆分,并将数据封装到SortBean对象,就可以得到K2
String[] split = value.toString().split("\t");
SortBean sortBean = new SortBean();
sortBean.setWord(split[0]);
sortBean.setNum(Integer.parseInt(split[1]));
//2.将K2和V2写入上下文中
context.write(sortBean,NullWritable.get());
}
}
Step 3. Reducer
package cn.itcast.mapreduce.sort; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class SortReducer extends Reducer<SortBean, NullWritable,SortBean,NullWritable> { //reduce方法将新的K2和V2转为K3和V3
@Override
protected void reduce(SortBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
Step 4. Main 入口
package cn.itcast.mapreduce.sort; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class JobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
//1.创建job对象
Job job = Job.getInstance(super.getConf(), "mapreduce_sort");
//job.setJarByClass(JobMain.class);
//2.配置job任务(八个步骤) //第一步:设置输入类和路径
job.setInputFormatClass(TextInputFormat.class);
//TextInputFormat.addInputPath(job,new Path("hdfs://hadoop101:8020/input/sort_input"));
TextInputFormat.addInputPath(job,new Path("file:///E:\\input\\sort_input")); //第二步:设置Mapper类型
job.setMapperClass(SortMapper.class);
job.setMapOutputKeyClass(SortBean.class);
job.setMapOutputValueClass(NullWritable.class);
//第三,四,五,六,排序不需要设置,只要制定好排序规则即可 //第七步:设置Reducer类和类型
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(SortBean.class);
job.setOutputValueClass(NullWritable.class); //第八步:设置输出类和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
//TextOutputFormat.setOutputPath(job,new Path("hdfs://hadoop101:8020/out/sort_out"));
TextOutputFormat.setOutputPath(job,new Path("file:///E:\\out\\sort_out")); //3.等待任务结束
boolean b = job.waitForCompletion(true);
return b?0:1;
} public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
} }
输出结果:

规约Combiner
概念
每一个 map 都可能会产生大量的本地输出,Combiner 的作用就是对 map 端的输出先做一次
合并,以减少在 map 和 reduce 节点之间的数据传输量,以提高网络IO 性能,是 MapReduce
的一种优化手段之一
- combiner 是 MR 程序中 Mapper 和 Reducer 之外的一种组件
- combiner 组件的父类就是 Reducer
- combiner 和 reducer 的区别在于运行的位置
- Combiner 是在每一个 maptask 所在的节点运行
- Reducer 是接收全局所有 Mapper 的输出结果
- combiner 的意义就是对每一个 maptask 的输出进行局部汇总,以减小网络传输量
实现步骤
1. 自定义一个 combiner 继承 Reducer,重写 reduce 方法
2. 在 job 中设置 job.setCombinerClass(CustomCombiner.class)
combiner 能够应用的前提是不能影响最终的业务逻辑,而且,combiner 的输出 kv 应该跟
reducer 的输入 kv 类型要对应起来
统计单词的出现次数:
MyCombiner类:
package cn.itcast.mapreduce.combiner; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class MyCombiner extends Reducer<Text, LongWritable,Text,LongWritable> { @Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//1.便利结合,将集合中的数字相加,得到V3
long count=0;
for (LongWritable value : values) {
count+=value.get();
}
//2.将K3和V3写入上下文中
context.write(key,new LongWritable(count));
}
}
无Combiner:

有Combiner:

实战案例
案例一
统计每个手机号的上行数据包总和,下行数据包总和,上行总流量之和,下行总流量之和 分
析:以手机号码作为key值,上行流量,下行流量,上行总流量,下行总流量四个字段作为
value值,然后以这个key,和value作为map阶段的输出,reduce阶段的输入
Step 1: 自定义map的输出value对象FlowBean
package cn.itcast.mapreduce.floow_count_demo1; import org.apache.hadoop.io.Writable; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; public class FloowBean implements Writable { private Integer upFloow;//上行数据包数
private Integer downFlow;
private Integer upCountFlow;//上行流量总和
private Integer downCountFlow; public FloowBean(Integer upFloow, Integer downFlow, Integer upCountFlow, Integer downCountFlow) {
this.upFloow = upFloow;
this.downFlow = downFlow;
this.upCountFlow = upCountFlow;
this.downCountFlow = downCountFlow;
} public FloowBean() { } public Integer getUpFloow() {
return upFloow;
} public void setUpFloow(Integer upFloow) {
this.upFloow = upFloow;
} public Integer getDownFlow() {
return downFlow;
} public void setDownFlow(Integer downFlow) {
this.downFlow = downFlow;
} public Integer getUpCountFlow() {
return upCountFlow;
} public void setUpCountFlow(Integer upCountFlow) {
this.upCountFlow = upCountFlow;
} public Integer getDownCountFlow() {
return downCountFlow;
} public void setDownCountFlow(Integer downCountFlow) {
this.downCountFlow = downCountFlow;
} @Override
public String toString() {
return upFloow +
"\t" + downFlow +
"\t" + upCountFlow +
"\t" + downCountFlow;
}
//序列化方法
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(upFloow);
dataOutput.writeInt(downFlow);
dataOutput.writeInt(upCountFlow);
dataOutput.writeInt(downCountFlow);
}
//反序列化方法
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFloow=dataInput.readInt();
this.downFlow=dataInput.readInt();
this.upCountFlow=dataInput.readInt();
this.downCountFlow=dataInput.readInt();
}
}
Step 2: 定义FlowMapper类
package cn.itcast.mapreduce.floow_count_demo1; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class FloowCountMapper extends Mapper<LongWritable, Text,Text,FloowBean> { /*
将K1和V1转为K2和V2
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.拆分行文本数据,得到手机号-->K2
String[] split = value.toString().split("\t");
String phoneNumber=split[1];
//2.创建FloowBean对象,并从行文数据中拆分流量的四个阶段,并将四个流量的字段值赋值给FlowBean对象
FloowBean floowBean=new FloowBean();
floowBean.setUpFloow(Integer.parseInt(split[6]));
floowBean.setDownFlow(Integer.parseInt(split[7]));
floowBean.setUpCountFlow(Integer.parseInt(split[8]));
floowBean.setDownCountFlow(Integer.parseInt(split[9]));
//3.将K2和V2写入上下文中
context.write(new Text(phoneNumber),floowBean);
}
}
Step 3: 定义FlowReducer类
package cn.itcast.mapreduce.floow_count_demo1; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class FloowCountReducer extends Reducer<Text,FloowBean,Text,FloowBean> { @Override
protected void reduce(Text key, Iterable<FloowBean> values, Context context) throws IOException, InterruptedException {
//1.遍历集合,并将集合中对应的四个字段累加
Integer upFloow=0;//上行数据包数
Integer downFlow=0;
Integer upCountFlow=0;//上行流量总和
Integer downCountFlow=0;
for (FloowBean value : values) {
upFloow+=value.getUpFloow();
downFlow+=value.getDownFlow();
upCountFlow+=value.getUpCountFlow();
downCountFlow+=value.getDownCountFlow();
}
//2.创建FloowBean对象,并给对象赋值
FloowBean floowBean = new FloowBean(upFloow,downFlow,upCountFlow,downCountFlow);
//3.将K3和V3写入上下文中
context.write(key,floowBean);
}
}
Step 4: 程序main函数入口FlowMain
package cn.itcast.mapreduce.floow_count_demo1; import cn.itcast.mapreduce.combiner.MyCombiner;
import cn.itcast.mapreduce.combiner.WordCountMapper;
import cn.itcast.mapreduce.combiner.WordCountReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class JobMain extends Configured implements Tool { //该方法用于指定一个job任务
@Override
public int run(String[] strings) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(),"mapreduce_floowcount");
//2.配置job任务对象(八个步骤) //打包jar路径主类
job.setJarByClass(JobMain.class); //第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class);
//TextInputFormat.addInputPath(job,new Path("hdfs://hadoop101:8020/wordcount"));
//本地测试元数据
TextInputFormat.addInputPath(job,new Path("file:///E:\\input\\flowcount_input"));
//第二步:指定map阶段的处理方式和数据类型
job.setMapperClass(FloowCountMapper.class);
//设置Map阶段K2的类型
job.setMapOutputKeyClass(Text.class);
//设置Map阶段V2的类型
job.setMapOutputValueClass(FloowBean.class);
//第三<分区>,四(排序)
//第五步(规约)
// 第六步默认(分组)
//第七步:指定reduce阶段的处理方式和数据类型
job.setReducerClass(FloowCountReducer.class);
//设置K3的类型
job.setOutputKeyClass(Text.class);
//设置V3的类型
job.setOutputValueClass(FloowBean.class); //第八步:设置输出类型
job.setOutputFormatClass(TextOutputFormat.class); //本地测试输出
TextOutputFormat.setOutputPath(job,new Path("file:///E:\\out\\flowcount_out")); //等待任务结束
boolean bl=job.waitForCompletion(true); return bl?0:1;
} public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//1.启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run); }
}
输出:

案例二
需求二: 上行流量倒序排序(递减排序)
分析,以需求一的输出数据作为排序的输入数据,自定义FlowBean,以FlowBean为map输出的
key,以手机号作为Map输出的value,因为MapReduce程序会对Map阶段输出的key进行排序
Step 1: 定义FlowBean实现WritableComparable实现比较排序
Java 的 compareTo 方法说明:
- compareTo 方法用于将当前对象与方法的参数进行比较。
- 如果指定的数与参数相等返回 0。
- 如果指定的数小于参数返回 -1。
- 如果指定的数大于参数返回 1。
package cn.itcast.mapreduce.flow_sort_demo2; import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; public class FlowBean implements WritableComparable<FlowBean> { private Integer upFloow;//上行数据包数
private Integer downFlow;
private Integer upCountFlow;//上行流量总和
private Integer downCountFlow; public FlowBean(Integer upFloow, Integer downFlow, Integer upCountFlow, Integer downCountFlow) {
this.upFloow = upFloow;
this.downFlow = downFlow;
this.upCountFlow = upCountFlow;
this.downCountFlow = downCountFlow;
} public FlowBean() { } public Integer getUpFloow() {
return upFloow;
} public void setUpFloow(Integer upFloow) {
this.upFloow = upFloow;
} public Integer getDownFlow() {
return downFlow;
} public void setDownFlow(Integer downFlow) {
this.downFlow = downFlow;
} public Integer getUpCountFlow() {
return upCountFlow;
} public void setUpCountFlow(Integer upCountFlow) {
this.upCountFlow = upCountFlow;
} public Integer getDownCountFlow() {
return downCountFlow;
} public void setDownCountFlow(Integer downCountFlow) {
this.downCountFlow = downCountFlow;
} @Override
public String toString() {
return upFloow +
"\t" + downFlow +
"\t" + upCountFlow +
"\t" + downCountFlow;
}
//序列化方法
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(upFloow);
dataOutput.writeInt(downFlow);
dataOutput.writeInt(upCountFlow);
dataOutput.writeInt(downCountFlow);
}
//反序列化方法
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFloow=dataInput.readInt();
this.downFlow=dataInput.readInt();
this.upCountFlow=dataInput.readInt();
this.downCountFlow=dataInput.readInt();
}
//指定排序规则
@Override
public int compareTo(FlowBean o) {
return o.upFloow-this.upFloow;
}
}
Step 2: 定义FlowMapper
package cn.itcast.mapreduce.flow_sort_demo2; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class FlowSortMapper extends Mapper<LongWritable, Text,FlowBean,Text> { @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
String phoneNumber=split[0];
FlowBean flowBean = new FlowBean(Integer.parseInt(split[1]),Integer.parseInt(split[2]),Integer.parseInt(split[3]),Integer.valueOf(split[4]));
context.write(flowBean,new Text(phoneNumber));
}
}
Step 3: 定义FlowReducer
package cn.itcast.mapreduce.flow_sort_demo2; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class FlowSortReducer extends Reducer<FlowBean, Text,Text,FlowBean> { @Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value,key);
}
}
}
Step 4: 程序main函数入口
package cn.itcast.mapreduce.flow_sort_demo2; import cn.itcast.mapreduce.floow_count_demo1.FloowBean;
import cn.itcast.mapreduce.floow_count_demo1.FloowCountMapper;
import cn.itcast.mapreduce.floow_count_demo1.FloowCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class JobMain extends Configured implements Tool { //该方法用于指定一个job任务
@Override
public int run(String[] strings) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(),"mapreduce_flowsort");
//2.配置job任务对象(八个步骤) //打包jar路径主类
job.setJarByClass(JobMain.class); //第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class);
//TextInputFormat.addInputPath(job,new Path("hdfs://hadoop101:8020/wordcount"));
//本地测试元数据
TextInputFormat.addInputPath(job,new Path("file:///E:\\out\\flowcount_out"));
//第二步:指定map阶段的处理方式和数据类型
job.setMapperClass(FlowSortMapper.class);
//设置Map阶段K2的类型
job.setMapOutputKeyClass(FlowBean.class);
//设置Map阶段V2的类型
job.setMapOutputValueClass(Text.class);
//第三<分区>,四(排序)
//第五步(规约)
// 第六步默认(分组)
//第七步:指定reduce阶段的处理方式和数据类型
job.setReducerClass(FlowSortReducer.class);
//设置K3的类型
job.setOutputKeyClass(Text.class);
//设置V3的类型
job.setOutputValueClass(FlowBean.class); //第八步:设置输出类型
job.setOutputFormatClass(TextOutputFormat.class); //本地测试输出
TextOutputFormat.setOutputPath(job,new Path("file:///E:\\out\\flowsort_out")); //等待任务结束
boolean bl=job.waitForCompletion(true); return bl?0:1;
} public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//1.启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run); }
}
输出:
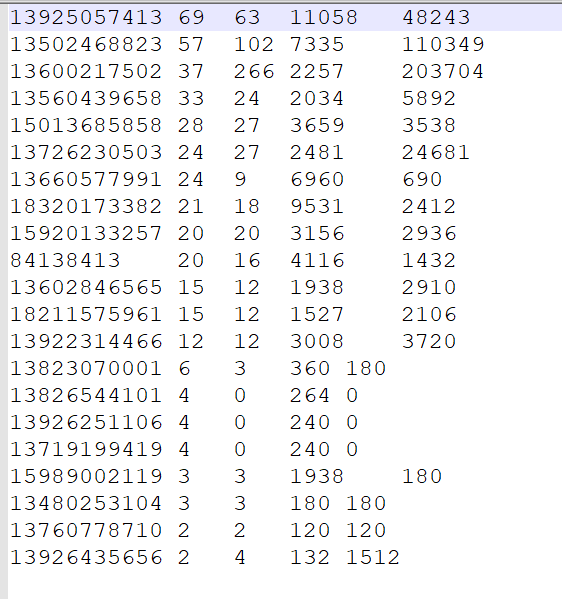
案列三
在需求一的基础上,继续完善,将不同的手机号分到不同的数据文件的当中去,需要自定义
分区来实现,这里我们自定义来模拟分区,将以下数字开头的手机号进行分开
- 135 开头数据到一个分区文件
- 136 开头数据到一个分区文件
- 137 开头数据到一个分区文件
- 其他分区
自定义分区
package cn.itcast.mapreduce.flow_count_sort_partition; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; public class FlowCountPartition extends Partitioner<Text,FloowBean> { @Override
public int getPartition(Text text, FloowBean floowBean, int i) {
String s = text.toString();
if(s.startsWith("135"))
return 0;
else if(s.startsWith("136"))
return 1;
else if(s.startsWith("137"))
return 2;
else
return 3;
}
}
程序main函数入口,设置排序的Partition和reducetask个数
package cn.itcast.mapreduce.flow_count_sort_partition; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class JobMain extends Configured implements Tool { //该方法用于指定一个job任务
@Override
public int run(String[] strings) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(),"mapreduce_flow_partition");
//2.配置job任务对象(八个步骤) //打包jar路径主类
job.setJarByClass(JobMain.class); //第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class);
//TextInputFormat.addInputPath(job,new Path("hdfs://hadoop101:8020/wordcount"));
//本地测试元数据
TextInputFormat.addInputPath(job,new Path("file:///E:\\input\\flowpartition_input"));
//第二步:指定map阶段的处理方式和数据类型
job.setMapperClass(FloowCountMapper.class);
//设置Map阶段K2的类型
job.setMapOutputKeyClass(Text.class);
//设置Map阶段V2的类型
job.setMapOutputValueClass(FloowBean.class);
//第三<分区>,四(排序)
job.setPartitionerClass(FlowCountPartition.class); //第五步(规约)
// 第六步默认(分组)
//第七步:指定reduce阶段的处理方式和数据类型
job.setReducerClass(FloowCountReducer.class);
//设置K3的类型
job.setOutputKeyClass(Text.class);
//设置V3的类型
job.setOutputValueClass(FloowBean.class); //设置reduce个数
job.setNumReduceTasks(4); //第八步:设置输出类型
job.setOutputFormatClass(TextOutputFormat.class); //本地测试输出
TextOutputFormat.setOutputPath(job,new Path("file:///E:\\out\\flowpartition_out")); //等待任务结束
boolean bl=job.waitForCompletion(true); return bl?0:1;
} public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//1.启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run); }
}
输出:
135分区

136分区

137分区

其他分区
Mapreduce之排序&规约&实战案例的更多相关文章
- hadoop笔记之MapReduce的应用案例(利用MapReduce进行排序)
MapReduce的应用案例(利用MapReduce进行排序) MapReduce的应用案例(利用MapReduce进行排序) 思路: Reduce之后直接进行结果合并 具体样例: 程序名:Sort. ...
- 3.awk数组详解及企业实战案例
awk数组详解及企业实战案例 3.打印数组: [root@nfs-server test]# awk 'BEGIN{array[1]="zhurui";array[2]=" ...
- 企业Shell面试题及企业运维实战案例(三)
1.企业Shell面试题1:批量生成随机字符文件名案例 使用for循环在/oldboy目录下批量创建10个html文件,其中每个文件需要包含10个随机小写字母加固定字符串oldboy,名称示例如下: ...
- 015_[小插曲]看黄老师《炼数成金Hadoop应用开发实战案例》笔记
1.大数据金字塔结构 Data Source-->Data Warehouses/Data Marts-->data exploration-->Data Mining-->D ...
- (转)awk数组详解及企业实战案例
awk数组详解及企业实战案例 原文:http://www.cnblogs.com/hackerer/p/5365967.html#_label03.打印数组:1. [root@nfs-server t ...
- Linux操作系统的日志管理之rsyslog实战案例
Linux操作系统的日志管理之rsyslog实战案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.日志介绍 1>.什么是日志 历史事件: 时间,地点,人物,事件 日志级 ...
- Flume实战案例运维篇
Flume实战案例运维篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Flume概述 1>.什么是Flume Flume是一个分布式.可靠.高可用的海量日志聚合系统,支 ...
- 面向对象-static关键字实战案例
面向对象-static关键字实战案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.static关键字概述 1>.static的功能 static关键字用于修饰成员变量和 ...
- 【Redis3.0.x】实战案例
Redis3.0.x 实战案例 简介 <Redis实战>的学习笔记和总结. 书籍链接 初识 Redis Redis 简介 Redis 是一个速度非常快的键值对存储数据库,它可以存储键和五种 ...
随机推荐
- Python编程之美:最佳实践指南PDF高清完整版免费下载|百度云盘|Python新手到进阶
百度云盘:Python编程之美:最佳实践指南PDF高清完整版免费下载 提取码:1py6 内容简介 <Python编程之美:最佳实践指南>是Python用户的一本百科式学习指南,由Pytho ...
- JavaScript运算符与流程控制
JavaScript运算符与流程控制 运算符 赋值运算符 使用=进行变量或常量的赋值. <script> let username = "YunYa"; < ...
- Java面试必问:ThreadLocal终极篇 淦!
点赞再看,养成习惯,微信搜一搜[敖丙]关注这个互联网苟且偷生的程序员. 本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试完整考点.资料以及我的系列 ...
- 递归-N皇后问题
// // #include <stdio.h> /*可以用回溯,但是我已经不太熟悉回溯了!!!!!!!!呜呜呜 * */ #include <iostream> #inclu ...
- IPython magic命令
- 十进制转换为其他进制(不使用format)
base = [str(x) for x in range(10)] + [chr(x) for x in range(ord('A'), ord('A') + 6)] # ['0', '1', '2 ...
- PHP xml_parser_free() 函数
定义和用法 xml_parser_free() 函数释放 XML 解析器.高佣联盟 www.cgewang.com 如果成功,该函数则返回 TRUE.如果失败,则返回 FALSE. 语法 xml_pa ...
- CF掉分日记 6.6 6.8
---恢复内容开始--- 写的效果依旧不好 还没写完前四题比赛就结束了 而且这些普及组的题目 我大多还是缺少简单算法的灵性 总是把问题搞复杂化. 6.5 A 第一道题非常水 简单分析发现是一个快速幂的 ...
- 获取判断IE版本 TypeError: Cannot read property 'msie' of undefined
注意:以下方法只适用于IE11 以下: TypeError: Cannot read property 'msie' of undefined jquery1.9去掉了 $.browser 所以报错 ...
- Use SQL to Query Data from CDS and Dynamics 365 CE
from : https://powerobjects.com/2020/05/20/use-sql-to-query-data-from-cds-and-dynamics-365-ce/ Have ...