简单学习 SQL and NOSql
文章参考链接::https://www.cnblogs.com/xrq730/p/11039384.html
结构化数据、非结构化数据与半结构化数据
文章的开始,聊一下结构化数据、非结构化数据与半结构化数据,因为数据特点的不同,将在技术上直接影响存储引擎的选型。
首先是结构化数据,根据定义结构化数据指的是由二维表结构来逻辑表达和实现的数据,严格遵循数据格式与长度规范,也称作为行数据,特点为:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。例如:

因此关系型数据库完美契合结构化数据的特点,关系型数据库也是关系型数据最主要的存储与管理引擎。
非结构化数据,指的是数据结构不规则或不完整,没有任何预定义的数据模型,不方便用二维逻辑表来表现的数据,例如办公文档(Word)、文本、图片、HTML、各类报表、视频音频等。
介于结构化与非结构化数据之间的数据就是半结构化数据了,它是结构化数据的一种形式,虽然不符合二维逻辑这种数据模型结构,但是包含相关标记,用来分割语义元素以及对记录和字段进行分层。常见的半结构化数据有XML和JSON,例如:
<person>
<name>张三</name>
<age>18</age>
<phone>12345</phone>
</person>
这种结构也被成为自描述的结构。
关系型数据库的优点
- 易理解
因为行 + 列的二维表逻辑是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型更加容易被理解
- 操作方便
通用的SQL语言使得操作关系型数据库非常方便,支持join等复杂查询,Sql + 二维关系是关系型数据库最无可比拟的优点,这种易用性非常贴近开发者
- 数据一致性
支持ACID特性,可以维护数据之间的一致性,这是使用数据库非常重要的一个理由之一,例如同银行转账,张三转给李四100元钱,张三扣100元,李四加100元,而且必须同时成功或者同时失败,否则就会造成用户的资损
- 数据稳定
数据持久化到磁盘,没有丢失数据风险,支持海量数据存储
- 服务稳定
最常用的关系型数据库产品MySql、Oracle服务器性能卓越,服务稳定,通常很少出现宕机异常
关系型数据库的缺点
紧接着的,我们看一下关系型数据库的缺点,也是比较明显的。
- 高并发下IO压力大
数据按行存储,即使只针对其中某一列进行运算,也会将整行数据从存储设备中读入内存,导致IO较高
- 为维护索引付出的代价大
为了提供丰富的查询能力,通常热点表都会有多个二级索引,一旦有了二级索引,数据的新增必然伴随着所有二级索引的新增,数据的更新也必然伴随着所有二级索引的更新,这不可避免地降低了关系型数据库的读写能力,且索引越多读写能力越差。有机会的话可以看一下自己公司的数据库,除了数据文件不可避免地占空间外,索引占的空间其实也并不少
- 为维护数据一致性付出的代价大
数据一致性是关系型数据库的核心,但是同样为了维护数据一致性的代价也是非常大的。我们都知道SQL标准为事务定义了不同的隔离级别,从低到高依次是读未提交、读已提交、可重复度、串行化,事务隔离级别越低,可能出现的并发异常越多,但是通常而言能提供的并发能力越强。那么为了保证事务一致性,数据库就需要提供并发控制与故障恢复两种技术,前者用于减少并发异常,后者可以在系统异常的时候保证事务与数据库状态不会被破坏。对于并发控制,其核心思想就是加锁,无论是乐观锁还是悲观锁,只要提供的隔离级别越高,那么读写性能必然越差
- 水平扩展后带来的种种问题难处理
前文提过,随着企业规模扩大,一种方式是对数据库做分库,做了分库之后,数据迁移(1个库的数据按照一定规则打到2个库中)、跨库join(订单数据里有用户数据,两条数据不在同一个库中)、分布式事务处理都是需要考虑的问题,尤其是分布式事务处理,业界当前都没有特别好的解决方案
- 表结构扩展不方便
由于数据库存储的是结构化数据,因此表结构schema是固定的,扩展不方便,如果需要修改表结构,需要执行DDL(data definition language)语句修改,修改期间会导致锁表,部分服务不可用
- 全文搜索功能弱
例如like "%中国真伟大%",只能搜索到"2019年中国真伟大,爱祖国",无法搜索到"中国真是太伟大了"这样的文本,即不具备分词能力,且like查询在"%中国真伟大"这样的搜索条件下,无法命中索引,将会导致查询效率大大降低
写了这么多,我的理解核心还是前三点,它反映出的一个问题是关系型数据库在高并发下的能力是有瓶颈的,尤其是写入/更新频繁的情况下,出现瓶颈的结果就是数据库CPU高、Sql执行慢、客户端报数据库连接池不够等错误,因此例如万人秒杀这种场景,我们绝对不可能通过数据库直接去扣减库存。
可能有朋友说,数据库在高并发下的能力有瓶颈,我公司有钱,加CPU、换固态硬盘、继续买服务器加数据库做分库不就好了,问题是这是一种性价比非常低的方式,花1000万达到的效果,换其他方式可能100万就达到了,不考虑人员、服务器投入产出比的Leader就是个不合格的Leader,且关系型数据库的方式,受限于它本身的特点,可能花了钱都未必能达到想要的效果。至于什么是花100万就能达到花1000万效果的方式呢?可以继续往下看,这就是我们要说的NoSql。
像上文分析的,数据库作为一种关系型数据的存储引擎,存储的是关系型数据,它有优点,同时也有明显的缺点,因此通常在企业规模不断扩大的情况下,不会一味指望通过增强数据库的能力来解决数据存储问题,而是会引入其他存储,也就是我们说的NoSql。
NoSql的全称为Not Only SQL,泛指非关系型数据库,是对关系型数据库的一种补充,特别注意补充这两个字,这意味着NoSql与关系型数据库并不是对立关系,二者各有优劣,取长补短,在合适的场景下选择合适的存储引擎才是正确的做法。
比较简单的NoSql就是缓存:

针对那些读远多于写的数据,引入一层缓存,每次读从缓存中读取,缓存中读取不到,再去数据库中取,取完之后再写入到缓存,对数据做好失效机制通常就没有大问题了。通常来说,缓存是性能优化的第一选择也是见效最明显的方案。
但是,缓存通常都是KV型存储且容量有限(基于内存),无法解决所有问题,于是再进一步的优化,我们继续引入其他NoSql:

数据库、缓存与其他NoSql并行工作,充分发挥每种NoSql的特点。当然NoSql在性能方面大大优于关系挺数据库的同时,往往也伴随着一些特性的缺失,比较常见的就是事务功能的缺失。
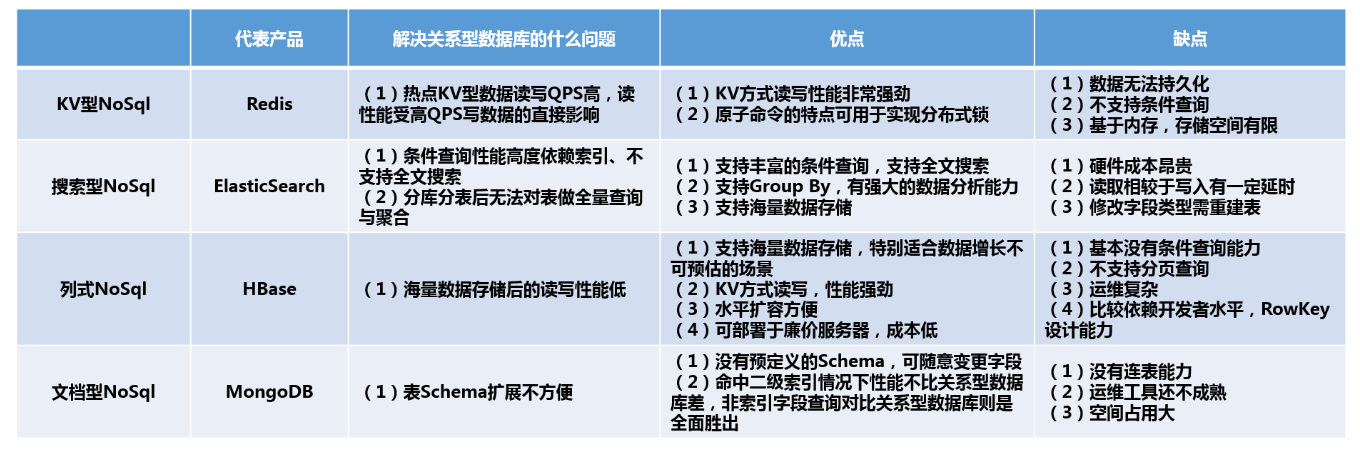
下面看一下常用的NoSql及他们的代表产品,并对每种NoSql的优缺点和适用场景做一下分析,便于熟悉每种NoSql的特点,方便技术选型。
KV型NoSql(代表----Redis)
KV型NoSql顾名思义就是以键值对形式存储的非关系型数据库,是最简单、最容易理解也是大家最熟悉的一种NoSql,因此比较快地带过。Redis、MemCache是其中的代表,Redis又是KV型NoSql中应用最广泛的NoSql,KV型数据库以Redis为例,最大的优点我总结下来就两点:
- 数据基于内存,读写效率高
- KV型数据,时间复杂度为O(1),查询速度快
因此,KV型NoSql最大的优点就是高性能,利用Redis自带的BenchMark做基准测试,TPS可达到10万的级别,性能非常强劲。同样的Redis也有所有KV型NoSql都有的比较明显的缺点:
- 只能根据K查V,无法根据V查K
- 查询方式单一,只有KV的方式,不支持条件查询,多条件查询唯一的做法就是数据冗余,但这会极大的浪费存储空间
- 内存是有限的,无法支持海量数据存储
- 同样的,由于KV型NoSql的存储是基于内存的,会有丢失数据的风险
综上所述,KV型NoSql最合适的场景就是缓存的场景:
- 读远多于写
- 读取能力强
- 没有持久化的需求,可以容忍数据丢失,反正丢了再查询一把写入就是了
例如根据用户id查询用户信息,每次根据用户id去缓存中查询一把,查到数据直接返回,查不到去关系型数据库里面根据id查询一把数据写到缓存中去。
简单学习 SQL and NOSql的更多相关文章
- 大数据学习资料之SQL与NOSQL数据库
这几年的大数据热潮带动了一激活了一大批hadoop学习爱好者.有自学hadoop的,有报名培训班学习的.所有接触过hadoop的人都知道,单独搭建hadoop里每个组建都需要运行环境.修改配置文件测试 ...
- 简单的SQL注入学习
引贴: http://blog.163.com/lucia_gagaga/blog/static/26476801920168184648754/ 首先需要编写一个php页面,讲php页面放入/opt ...
- Sql Or NoSql,看完这一篇你就懂了
前言 你是否在为系统的数据库来一波大流量就几乎打满CPU,日常CPU居高不下烦恼?你是否在各种NoSql间纠结不定,到底该选用那种最好?今天的你就是昨天的我,这也是写这篇文章的初衷. 这篇文章是我好几 ...
- Sql Or NoSql,看完这一篇你就懂了(转五月的仓颉)
前言 你是否在为系统的数据库来一波大流量就几乎打满CPU,日常CPU居高不下烦恼?你是否在各种NoSql间纠结不定,到底该选用那种最好?今天的你就是昨天的我,这也是写这篇文章的初衷. 这篇文章是我好几 ...
- SQL vs NoSQL 没有硝烟的战争!
声明:本文译自SQL vs NoSQL The Differences,如需转载请注明出处. SQL(结构化查询语言)数据库作为一个主要的数据存储机制已经超过40个年头了.随着web应用和像MySQL ...
- SQL与NoSQL(关系型与非关系型)数据库的区别
永远正确的经典答案依然是:具体问题具体分析. 数据表VS.数据集 关系型和非关系型数据库的主要差异是数据存储的方式.关系型数据天然就是表格式的,因此存储在数据表的行和列中.数据表可以彼此关联协作存储, ...
- 转:如何学习SQL(第一部分:SQL基础)
转自:http://blog.163.com/mig3719@126/blog/static/285720652010950712271/ 1. 为什么学习SQL 自人类社会形成之日起,社会的运转就在 ...
- SQL和NOSQL有区别吗?
在大数据高速发展的今天,数据量在不断的增加,传统的数据库可能不能满足人们的需求了,这个时候新霸哥注意到了NOSQL出现了可以解决这个问题.我们知道sql数据库可以存储数据和处理数据,但是NOSQL最大 ...
- SQL VS NoSQL 如何选择数据库
在前一篇文章中我们主要的讨论了SQL与NoSQL数据库之间的主要的差别.接下来,我们将会利用上一篇中的知识来确定在特定的场景中如何确定比较好的选择. 首先我们先来总结一下: SQL数据库: 使用表存 ...
随机推荐
- RayFire的下载与安装方法
RayFire的下载与安装方法 发布时间:2020/10/12 近几年,电影中融入了越来越多的动画元素,其中的爆炸场景更是十分吸引眼球.小编不禁好奇,什么样的插件能做出来如此好玩的特效,上网搜索一番发 ...
- 下载器Folx专业版有没有iTunes整合功能
对于使用Mac系统的用户来说,相信对iTunes都不陌生.Folx专业版提供的iTunes整合功能,能将下载的音频.电影等文件自动同步到iTunes. 该功能将会有助于用户的音频.视频整合,对于喜欢听 ...
- 「CSP-S 2019」Emiya 家今天的饭
description loj 3211 solution 看到题目中要求每种主要食材至多在一半的菜中被使用,容易想到补集转换. 即\(ans=\)总方案数-存在某一种食材在一半以上的菜中被使用的方案 ...
- 【PYTEST】第四章Fixture
知识点: 利用fixture共享数据 conftest.py共享fixture 使用多个fixture fixture作用范围 usefixture 重命名 1. 利用fixture共享数据 test ...
- Python多线程join和setDaemon区别与用法
一直没有太搞清楚join和setDaemon有什么区别,总是对于它们两个的概念很模糊,需要做个实验然后记录一下. 先说结论: join: 子线程合并到主线程上来的作用,就是当主线程中有子线程join的 ...
- C语言讲义——注释
注释 什么是注释? --注释写在代码中的文字,不参与代码编译,不影响运行结果. 为什么要注释?--让代码可读性更强. C语言有两种注释: 单行注释 // 多行注释 /* */ 多行注释可以只有一行, ...
- 【Usaco 2009 Silver】JZOJ2020年9月19日提高B组T1 音乐节拍
[Usaco 2009 Silver]JZOJ2020年9月19日提高B组T1 音乐节拍 题目 Description FJ准备教他的奶牛弹奏一首歌曲,歌曲由N(1<=N<=50,000) ...
- Arcgis100.4 加载天地图不显示--备注一哈
Arcgis100.4 默认添加了请求referer 值,天地图会拒绝请求,替换为http://map.tianditu.gov.cn/ 可正常显示.(arcgis 降级到100.1也可正常显示) R ...
- 微服务注册到Nacos的IP私网172.x.x.x网段无法访问的问题
解决方案一 显示声明注册服务实例的外网IP,默认就是使用私网的IP造成无法访问的,配置如下: spring: cloud: nacos: discovery: ip: 101.37.6.8 解决方案二 ...
- 第4.2节 神秘而强大的Python生成器精讲
一. 生成器(generator)概念 生成器是一个特殊的迭代器,它保存的是算法,每次调用next()或send()就计算出下一个元素的值,直到计算出最后一个元素,没有更多的元素时,抛出StopIte ...