3.mysql小表驱动大表的4种表连接算法
小表驱动大表
1、概念
驱动表的概念是指多表关联查询时,第一个被处理的表,使用此表的记录去关联其他表。驱动表的确定很关键,会直接影响多表连接的关联顺序,也决定了后续关联时的查询性能。
2、原则
驱动表的选择遵循一个原则:
在对最终结果集没影响的前提下,优先选择结果集最小的那张表作为驱动表。改变驱动表就意味着改变连接顺序,只有在不会改变最终输出结果的前提下才可以对驱动表做优化选择。外连接的顺序改变就很可能影响结果。
预估结果集的原则:
- 如果where里没有相应表的筛选条件,无论on里是否有相关条件,默认为全表
- 如果where里有筛选条件,但是不能使用索引来筛选,那么默认为全表
- 如果where里有筛选条件,而且可以使用索引,那么会根据索引来预估返回的记录行数
3、识别
- explain显示结果里排在第一行的就是驱动表
4、嵌套循环算法
(1) 4种算法
- 在使用索引关联的情况下,有Index Nested-Loop join和Batched Key Access join两种算法;
- 在未使用索引关联的情况下,有Simple Nested-Loop join和Block Nested-Loop join两种算法;
(2) Nested-Loop Join Algorithms
一个简单的嵌套循环联接(NLJ)算法,循环从第一个表中依次读取行,取到每行再到联接的下一个表中循环匹配。这个过程会重复多次直到剩余的表都被联接了。通过外循环的行去匹配内循环的行,所以内循环的表会被扫描多次。
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions,
send to client
}
}
}
(3) Block Nested-Loop Join Algorithm
一个块嵌套循环联接(BNL)算法,将外循环的行缓存起来,读取缓存中的行,减少内循环的表被扫描的次数。
MySQL使用联接缓冲区时,会遵循下面这些原则:
join_buffer_size系统变量的值决定了每个联接缓冲区的大小;
联接类型为ALL、index、range时(换句话说,联接的过程会扫描索引或数据时),MySQL会使用联接缓冲区;
缓冲区是分配给每一个能被缓冲的联接,所以一个查询可能会使用多个联接缓冲区;
联接缓冲区永远不会分配给第一个表,即使该表的查询类型为ALL或index;
联接缓冲区联接之前分配,查询完成之后释放;
使用到的列才会放到联接缓冲区中,并不是所有的列;
每个join关键字就对应着一个join buffer,也就是驱动表和第二张表用一个join buffer,得到的块结果集与第三章表用一个join buffer
设S是每次存储t1、t2组合的大小,C是组合的数量,则t3被扫描的次数为:
(S * C)/join_buffer_size + 1

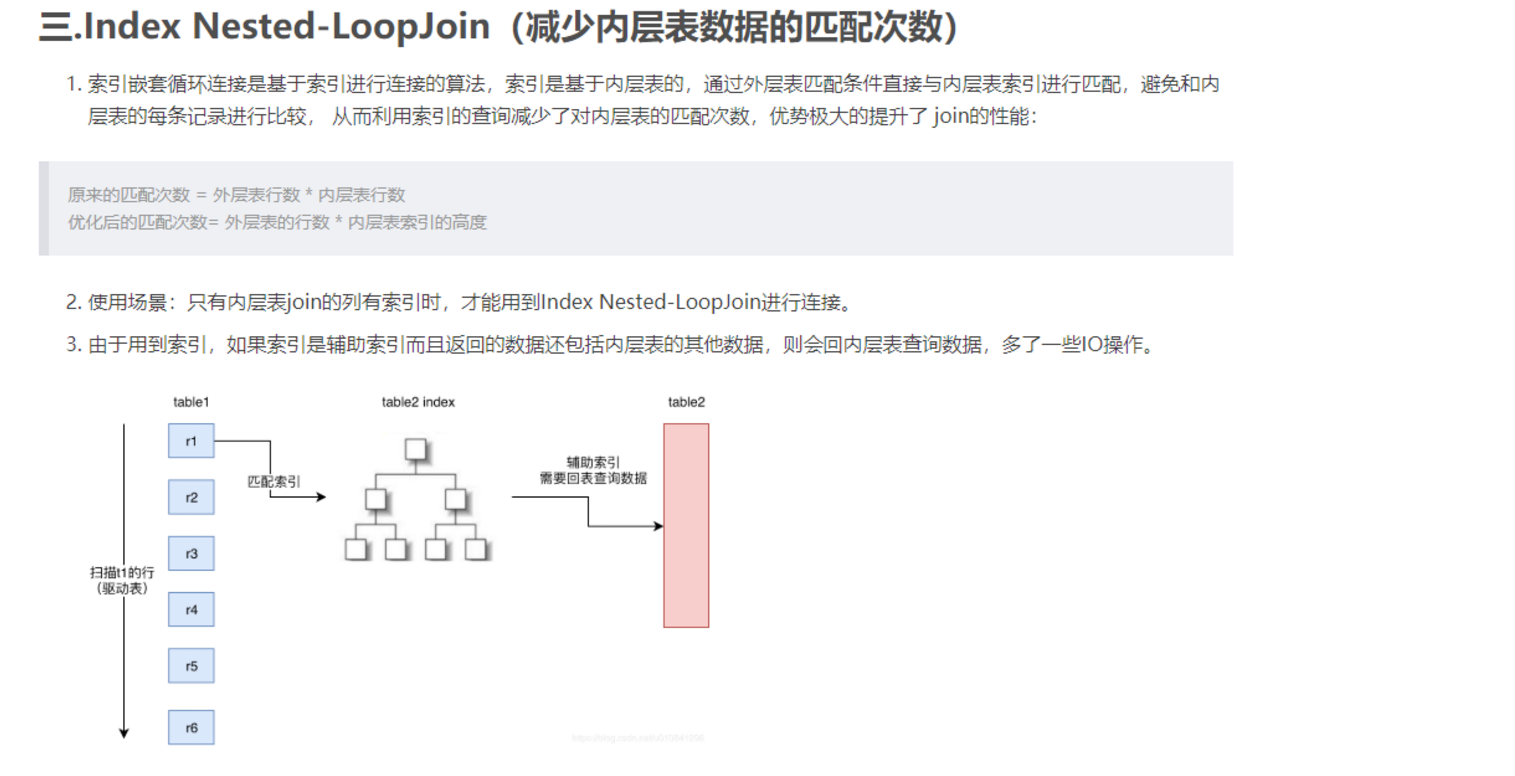
(4) Index Nested-Loop join
通过索引关联被驱动表,使用的是Index Nested-Loop join算法,不会使用msyql的join buffer。根据驱动表的筛选条件逐条地和被驱动表的索引做关联,每匹配到符合的记录,放入net-buffer中,然后继续关联,直到net-buffer满了,返回给client,清空net-buffer,此缓存区由net_buffer_length参数控制
(5) Batched Key Access join
原理:
1、逐条的根据where条件查询驱动表,将符合记录的数据行放入join buffer,然后根据关联的索引获取被驱动表的索引记录,存入read_rnd_buffer。join buffer和read_rnd_buffer都有大小限制,无论哪个到达上限都会停止此批次的数据处理,等处理完清空数据再执行下一批次。也就是驱动表符合条件的数据可能不能够一次处理完,而要分批次处理。
2、当达到批次上限后,对read_rnd_buffer里的被驱动表的索引按主键做递增排序,这样在回表查询时就能够做到近似顺序查询
3、因为mysql的InnoDB引擎的数据是按聚集索引来排列的,当对非聚集索引按照主键来排序后,再用主键去查询就使得随机查询变为顺序查询,而计算机的顺序查询有预读机制,在读取一页数据时,会向后额外多读取最多1M数据。此时顺序读取就能排上用场。
以下示例均以此为基础数据:
create table a(a1 int primary key, a2 int ,index(a2)); --双字段都有索引
create table c(c1 int primary key, c2 int ,index(c2), c3 int); --双字段都有索引
create table b(b1 int primary key, b2 int); --有主键索引
create table d(d1 int, d2 int); --没有索引
insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
insert into b values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
insert into c values(1,1,1),(2,4,4),(3,6,6),(4,5,5),(5,3,3),(6,3,3),(7,2,2),(8,8,8),(9,5,5),(10,3,3);
insert into d values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
sql如下:
select a.*,c.* from a join c on a.a2=c.c2 where a.a1>4;(下图应为a1>4)
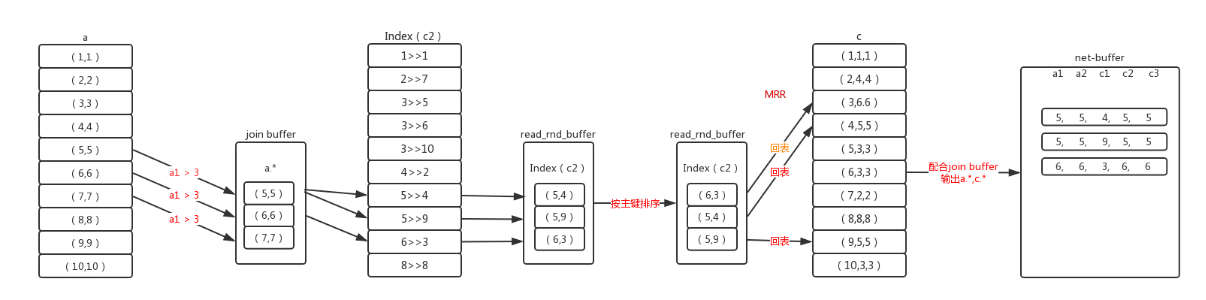
使用:
BKA算法在需要对被驱动表回表的情况下能够优化执行逻辑,如果不需要会表,那么自然不需要BKA算法
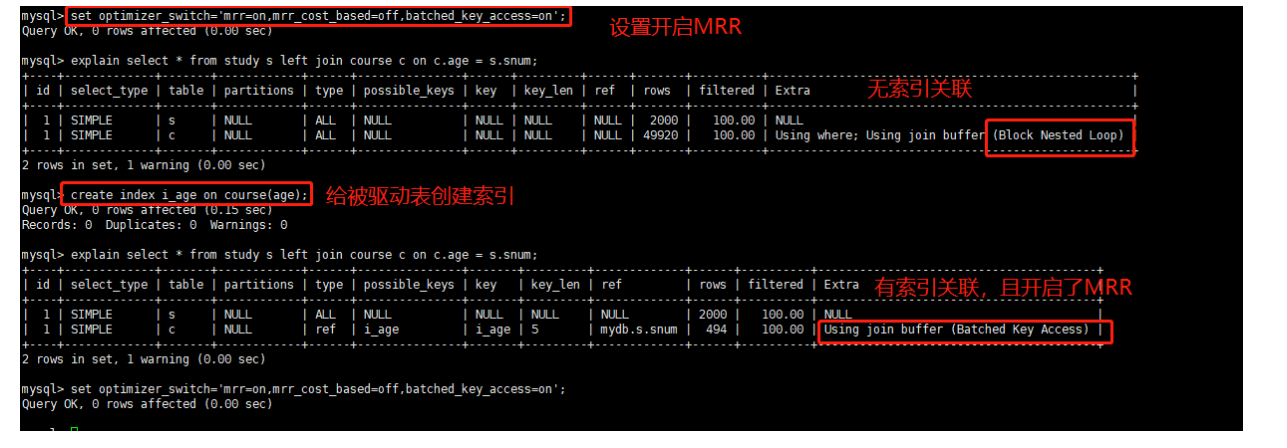
如果要使用 BKA 优化算法的话,你需要在执行 SQL 语句之前先设置:
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
前两个参数的作用是要启用 MRR(Multi-Range Read)。这么做的原因是,BKA 算法的优化需要依赖于MRR,官方文档的说法,是现在的优化器策略,判断消耗的时候,会更倾向于不使用 MRR,把 mrr_cost_based 设置为 off,就是固定使用 MRR 了。)
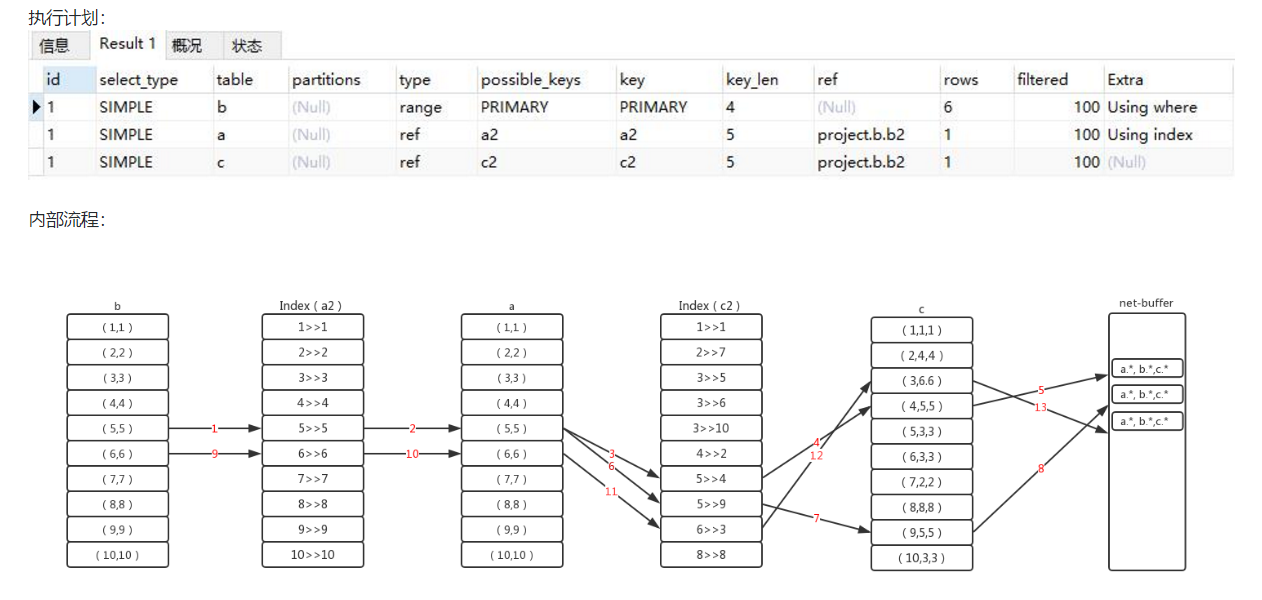
(6)嵌套循环的执行过程
多表连接如何执行?是先两表连接的结果集然后关联第三张表,还是一条记录贯穿全局?
sql如下:
select a.*,b.*,c.* from a join c on a.a2=c.c2 join b on c.c2=b.b2 where b.b1>4;
(7) 根据关联索引选择算法
3.mysql小表驱动大表的4种表连接算法的更多相关文章
- MySQL高级知识(十六)——小表驱动大表
前言:本来小表驱动大表的知识应该在前面就讲解的,但是由于之前并没有学习数据批量插入,因此将其放在这里.在查询的优化中永远小表驱动大表. 1.为什么要小表驱动大表呢 类似循环嵌套 for(int i=5 ...
- 了解MySQL联表查询中的驱动表,优化查询,以小表驱动大表
一.为什么要用小表驱动大表 1.驱动表的定义 当进行多表连接查询时, [驱动表] 的定义为: 1)指定了联接条件时,满足查询条件的记录行数少的表为[驱动表] 2)未指定联接条件时,行数少的表为[驱动表 ...
- Mysql优化原则_小表驱动大表IN和EXISTS的合理利用
//假设一个for循环 ; $i < ; $i++) { ; $i < ; $j++) { } } ; $i < ; $i++) { ; $i < ; $j++) { } } ...
- MySql 小表驱动大表
在了解之前要先了解对应语法 in 与 exist. IN: select * from A where A.id in (select B.id from B) in后的括号的表达式结果要求之输出一列 ...
- 查询优化--小表驱动大表(In,Exists区别)
Mysql 系列文章主页 =============== 本文将以真实例子来讲解小表驱动大表(In,Exists区别) 1 准备数据 1.1 创建表.函数.存储过程 参照 这篇(调用函数和存储过程批 ...
- 6.2 小表驱动大表(exists的应用)
1. 优化原则:小表驱动大表,即小数据集驱动大数据集. select * from A where id in (select id from B) 等价于: for select id from B ...
- 小表驱动大表, 兼论exists和in
给出两个表,A和B,A和B表的数据量, 当A小于B时,用exists select * from A where exists (select * from B where A.id=B.id) ex ...
- WRI$_ADV_OBJECTS表过大,导致PDB的SYSAUX表空间不足
现象监控发现sysaux表空间使用不断增加,导致表空间不足 查看过程 查看版本: SQL> select * from v$version; BANNER CON_ID ------------ ...
- (原创)c++11改进我们的模式之改进表驱动模式
所谓表驱动法(Table-Driven Approach),简单讲是指用查表的方法获取值.表驱动是将一些通过较为复杂逻辑语句来得到数据信息的方式,通过查询表的方式来实现,将数据信息存放在表里.对于消除 ...
随机推荐
- IDEA集成Docker插件后出现日志乱码的解决办法
修改IDEA的vmoptions文件 找到IDEA安装目录的bin目录,在idea.exe.vmoptions和idea64.exe.vmoptions文件中追加以下内容: -Dfile.encodi ...
- Razorpay支付对接,JAVA对接篇
Razorpay 作为印度本土的一家支付公司,类似中国的支付宝 微信,本篇记录一下对接印度第三方支付公司 准备工作: 注册公司 申请Razorpay账号 申请正式环境 Razorpay工作台: 获取k ...
- 基于ARM64的Qemu/KVM学习环境搭建
作者:pengdonglin137@163.com 在没有aarch64架构的开发板的情况下,可以使用Qemu来模拟一个支持KVM的AArch64位的host,然后再在其上运行一个开启KVM加速的Qe ...
- redis集群管理--sentinel
什么是sentinel? Sentinel(哨兵)是用于监控redis集群中Master状态的工具,是Redis 的高可用性解决方案,sentinel哨兵模式已经被集成在redis2.4之后的版本中. ...
- Pentaho Report Designer 报表系统 - 入门详解
目录 简介 安装与配置 环境要求 运行方式 使用教学 数据源配置与原始数据获取 报表布局设计与格式化 布局设计 模块结构 控件 示例 报表预览与发布 报表访问与获取 参考材料 简介 Pentaho ...
- JAVA课堂题目--递归来判断回数
package class20190923; import java.util.Scanner; public class Classtext { private static int n=0; pr ...
- web移动端点击穿透问题
在移动端开发的时候,我们有时候会遇到这样一个bug:点击关闭遮罩层的时候,遮罩层下面的带有点击的元素也会被触发,给人一种击穿了页面的感觉,这是为什么呢?主要是因为用户touch事件关闭按钮的时候,触发 ...
- 【题解】The Last Hole! [CF274C]
[题解]The Last Hole! [CF274C] 传送门:\(\text{The Last Hole!}\) \(\text{[CF274C]}\) [题目描述] 给出平面上 \(n\) 个圆的 ...
- Springboot — 用更优雅的方式发HTTP请求:RestTemplate
RestTemplate是Spring提供的用于访问Rest服务的客户端,RestTemplate提供了多种便捷访问远程Http服务的方法,能够大大提高客户端的编写效率. 我之前的HTTP开发是用ap ...
- Mysql为什么使用b+树,而不是b树、AVL树或红黑树?
首先,我们应该考虑一个问题,数据库在磁盘中是怎样存储的?(答案写在下一篇文章中) b树.b+树.AVL树.红黑树的区别很大.虽然都可以提高搜索性能,但是作用方式不同. 通常文件和数据库都存储在磁盘,如 ...