Python+Selenium练习篇之1-摘取网页上全部邮箱
前面已经介绍了Python+Selenium基础篇,通过前面几篇文章的介绍和练习,Selenium+Python的webUI自动化测试算是入门了。接下来,我计划写第二个系列:练习篇,通过一些练习,了解和掌握一些Selenium常用的接口或者方法。
练习场景:在某一个网页上有些字段是我们感兴趣的,我们希望摘取出来,进行其他操作。但是这些字段可能在一个网页的不同地方。例如,我们需要在关于百度页面-联系我们,摘取全部的邮箱。
思路拆分:
1. 首先,需要得到当前页面的source内容,就像,打开一个页面,右键-查看页面源代码。
2. 找出规律,通过正则表达式去摘取匹配的字段,存储到一个字典或者列表。
3. 循环打印字典或列表中内容,Python中用 for 语句实现。
技术角度实现相关方法:
1. 查看页面的源代码,在Selenium中有driver.page_source 这个方法得到
2. Python中利用正则,需要导入re模块
3. for email in emails :
print email
想法技术角度方法都找到,我们新建一个extract_email.py 文件,输入如下代码:
# coding=utf-8
from selenium import webdriver
import re
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("http://home.baidu.com/contact.html")
# 得到页面源代码
doc = driver.page_source
emails = re.findall(r'[\w]+@[\w\.-]+',doc) # 利用正则,找出 xxx@xxx.xxx 的字段,保存到emails列表
# 循环打印匹配的邮箱
for email in emails:
print (email)
解释:
在python正则表达式语法中,Python中字符串前面加上 r 表示原生字符串,用\w表示匹配字母数字及下划线。re模块下findall方法返回的是一个匹配子字符串的列表。
运行结果:
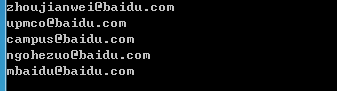
Python+Selenium练习篇之1-摘取网页上全部邮箱的更多相关文章
- Python+Selenium之摘取网页上全部邮箱
本文转载:http://blog.csdn.net/u011541946/article/details/68485981 练习场景:在某一个网页上有些字段是我们感兴趣的,我们希望摘取出来,进行其他操 ...
- Python+Selenium练习篇之18-获取元素上面的文字
本文介绍如何通过Selenium方法来获取某一个元素的text属性值.在很多自动化测试脚本中,需要多次获取元素的text值,拿过来进行对比和匹配.例如,在一个登陆界面,如果不输入用户名和密码,直接点击 ...
- Python+Selenium练习篇之11-浏览器上前进和后退操作
本文来介绍上如何,利用webdriver中的方法来演示浏览器中地址栏旁边的前进和后退功能. 相关脚本代码如下: # coding=utf-8import timefrom selenium impor ...
- Python+Selenium中级篇之8-Python自定义封装一个简单的Log类《转载》
Python+Selenium中级篇之8-Python自定义封装一个简单的Log类: https://blog.csdn.net/u011541946/article/details/70198676
- Python+Selenium基础篇之4-XPath的使用
开始写自动化脚本之前,我们先学习几个概念,在完全掌握了这几个概念之后,有助于我们快速上手,如何去编写自动化测试脚本. 元素,在这个教程系列,我们说的元素之网页元素(web element).在网页上面 ...
- Python+Selenium基础篇之1-环境搭建
Python + Selenium 自动化环境搭建过程 1. 所需组建 1.1 Selenium for python 1.2 Python 1.3 Notepad++ 作为刚初学者,这里不建议使用P ...
- Python——零基础向-四行代码下载网页上的一张图片
一.确保安装了requests模块 还没安装的可以百度一下如何安装,很简单的. 这里简单的说一下方法:win+R,输入cmd,打开命令行窗口,输入命令:pip install requests ,即可 ...
- python+selenium基础篇,网页截图
代码如下: from selenium import webdriver dr=webdriver.Firefox() dr.get("https://www.baidu.com" ...
- Python+Selenium练习篇之2-利用ID定位元素
在前面一篇文章,我们介绍了如何摘取页面字段,通过正则进行匹配符合要求的字段.如果感觉有点困难,不能立马理解,没有关系.把字符串摘取放到第一篇,是因为自动化测试脚本,经常要利用字符串操作,字符串切割,查 ...
随机推荐
- 绿盟网站安全防护服务(vWAF)
平台: linux 类型: 虚拟机镜像 软件包: basic software devops nsfocus security waf 服务优惠价: 按服务商许可协议 云服务器费用:查看费用 立即部署 ...
- Hybris Enterprise Commerce Platform 服务层的设计与实现
Hybris Enterprise Commerce Platform这个系列之前已经由我的同事,SAP成都研究院Hybris开发团队的同事张健(Zhang Jonathan)发布过两篇文章了.这里J ...
- 使用Java+SAP云平台+SAP Cloud Connector调用ABAP On-Premise系统里的函数
最近Jerry接到一个原型开发的任务,需要在微信里调用ABAP On Premise系统(SAP CRM On-Premise)里的某些函数.具体场景和我之前的公众号文章 Cloud for Cust ...
- CSS样式中visited,hover,active , focus这四个分别表示什么意思?
CSS伪类用于向某些选择器添加特殊的效果.CSS又名层叠样式表,所谓层叠,就是后面的样式会覆盖前面的样式,所以在样式表中,各样式排列的顺序很有讲究. :link 与 :visited 在样式文件中的顺 ...
- IOS 获取文本焦点 主动召唤出键盘(becomeFirstResponder) and 失去焦点(退下键盘)
主动召唤出键盘 - (void)viewDidAppear:(BOOL)animated { // 3.主动召唤出键盘 [self.nameField becomeFirstResponder]; / ...
- 题解 P1137 【旅行计划】
传送门 很显然,每个点的答案是它所有前驱节点的答案加1,即f[i]=max(f[i],f[j]+1); 考虑空间复杂度用邻接表存图,在拓扑排序同时DP就好了 #include<iostream& ...
- CUDA:Supercomputing for the Masses (用于大量数据的超级计算)-第四节
了解和使用共享内存(1) Rob Farber 是西北太平洋国家实验室(Pacific Northwest National Laboratory)的高级科研人员.他在多个国家级的实验室进行大型并行运 ...
- 分词,复旦nlp,NLPIR汉语分词系统
http://www.nlpir.org/ http://blog.csdn.net/zhyh1986/article/details/9167593
- package.json字段分析
分析1.必须在包的顶层目录下2.二进制文件应该在bin目录下3.javascipt在lib目录下4.文档在doc目录下 package.json字段分析 name:包的名称,必须是唯一的,由小写英文字 ...
- C++的新特性for-each
C++实验课要求用for each 循环来实现关联容器 map 的输出,一开始完全萌比.查了好久的资料才整理出下面的: C++11新特性之一就是类似java的for each循环: map<in ...