Kafka分布式消息队列
基本架构
Kafka分布式消息队列的作用:
解耦:将消息生产阶段和处理阶段拆分开,两个阶段互相独立各自实现自己的处理逻辑,通过Kafka提供的消息写入和消费接口实现对消息的连接处理。降低开发复杂度,提高系统稳定性。
高吞吐率:kafka通过顺序读写磁盘提供可以和内存随机读写相匹敌的读写速度,灵活的客户端API设计,利用Linux操作系统提供“零拷贝”特性减少消息网络传输时间,提供端到端的消息压缩传输,对同一主题下的消息采用分区存储。 kafka通过诸多良好的特性利用廉价的机器就可以实现高吞吐率。
高容错、高可用:kafka允许用户对分区配置多副本,kafka将副本均匀地分配到名broker存储,保证同现代战争分区的副本不会在同一台机器上存储(集群模式下),多副本之间采用leader-follower机制同步消息,只有leader对外提供读写服务,当leader意外失败、broker进程关闭、服务pdsm等情况导致数据不可用时,kafka会从Follower中选择一个Leader继续提供读写服务。
可扩展:理论上Kafka的性能随着Broker的增多而增加,增加一个Broker只需要为新增加的Broker设置一个唯一编号,编写好配置文件后,Kafka通过Zookeeper就能发现新的Broker。
峰值处理:例如秒杀系统、双十一等促销活动的爆发式集中支付系统、推荐系统等都需要消息队列的介入,这类系统在某个时间点数据爆发式增长,后台处理系统不能够及时处理峰值请求,如果没有消息队列的介入就会千万后台系统处理不及时,请求数据严重挤压,如此恶性循环最终导致系统崩溃。Kafka的接入能够使数据进行冗余存储,并保证消息顺序读写,相当于给系统接入了一个大的缓冲区,既能接收持续暴增的请求,又能根据后台系统的处理能力提供数据服务,进而提高各业务系统的峰值处理能力。
kafka的架构如下:
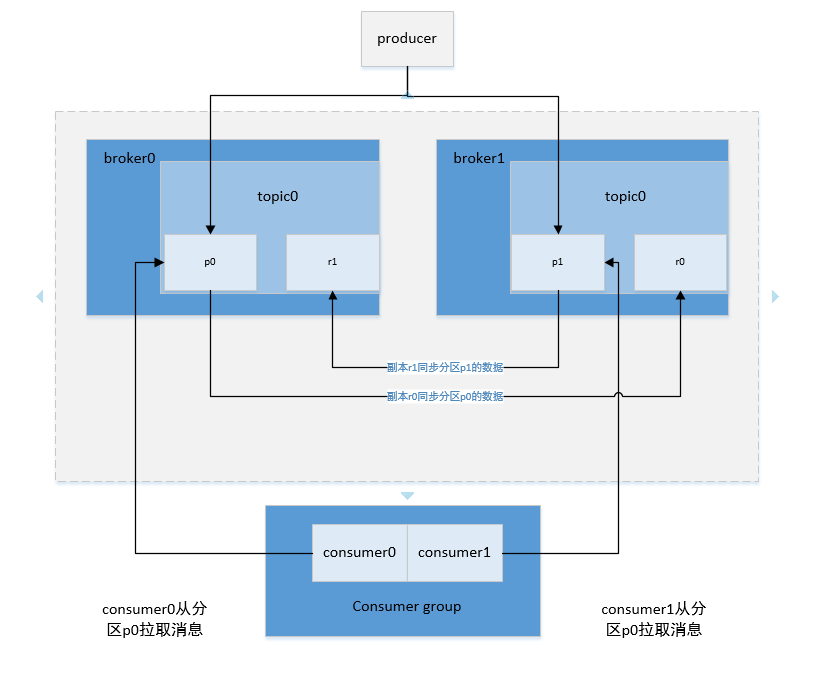
Broker:启动kafka的一个实例就是一个broker,默认端口9092。一个kafka集群可以启动多个broker同时对外提供服务,borker不保存任何producer和consumer相关的信息。
Topic:主题,kafka中同一种类型数据集的名称,相当于数据库中的表,producer将同一类型的数据写入同一个topic下,consumer从同一个topic消费同一类型的数据。逻辑上同一个数据集只有一个topic,如果设置一个topic有多个
partition和多个partition,在物理上同一个topic下的数据集会被分成多份存储到不同的物理机上。
Partition:分区,一个topic可以设置多个分区,相当于反一个数据集分成多份分别放到不同的分区中存储。一个topic可以有一个或者多个分区,在创建topic的时候可以设置topic的partition数,如果不设置默认为1.理论上partiion数据越多,系统的整体吞吐率就越高,但是在实际应用中并不是partiition越多越好,反而过多的partition在broker宕机需要重新对partition选主,在这个过程中耗时太久会导致partition暂时无法提供服务,千万写入消息失败。分区命名规则是topicname-index(比如testtopic-0、testtopic-2等)。
Segment:段文件,kafka中最小数据存储单位,kafka可以存储多个topic,各个topic之间隔离没有影响,一个topic包含一个或者多个partition,每个partition在物理结构上是一个文件夹,文件夹名称以topic名称加partition索引的方式命名,一个partition包含多个segment,每个segment以message在partition中的起始偏移量命名以log结尾的文件,producer向topic中发布消息会被顺序写入对应的segment文件中。kafka为了提高写入和查询速度,在partition文件夹下每一个segment log文件都有一个同名的索引文件,索引文件以index结尾。
Offset:消息在分区中偏移量,用来在分区中唯一地标识这个消息。
Replication:副本,一个partition可以设置一个或者多个副本,副本主要保证系统能够持续不丢失地对外提供服务。在创建topic的时候可以设置partition的replication数。
Producer:消息生产者,负责向kafka中发布消息。
Consumer Group:消费者所属组,一个consumer group可以包含一个或者多个consumer,当一个topic被一个consumer group消费的时候,consumer group内只能有一个consumer消费同一条消息,不会再现同一个consumer group
中多个consumer同时消费一条消息千万一个消息被一个consumer group 消费多次的情况。
Consumer:消息消费者,consumer从kafka指定的主题中拉取消息,如果一个topic有多个分区,kafka只能保证一个分区内消息的有序性,在不同的分区之间无法保证。
Zookeeper:Zookeeper在kafka集群中主要用于协调管理,主要作用:
1)kafka将元数据信息保存在Zookeeper中。
2)通过Zookeeper的协调管理来实现整个kafka集群的动态扩展。
3)实现整个集群的负载均衡。
4)producer通过 Zookeeper感知partition的Leader。
5)Consumer消费的负载均衡。
6)保存consumer消费的状态信息。
Kafka0.9版本之前Consumer消费消息的偏移量记录在Zookeeper中,0.9版本之后 则由kafka自己维护consumer消费消息的偏移量。
摘自《企业大数据处理》
Kafka分布式消息队列的更多相关文章
- 【转】快速理解Kafka分布式消息队列框架
from:http://blog.csdn.net/colorant/article/details/12081909 快速理解Kafka分布式消息队列框架 标签: kafkamessage que ...
- Kafka 分布式消息队列介绍
Kafka 分布式消息队列 类似产品有JBoss.MQ 一.由Linkedln 开源,使用scala开发,有如下几个特点: (1)高吞吐 (2)分布式 (3)支持多语言客户端 (C++.Java) 二 ...
- 快速理解Kafka分布式消息队列框架
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ ==是什么 == 简单的说,K ...
- kafka分布式消息队列介绍以及集群安装
简介 首先简单说下对kafka的理解: 1.kafka是一个分布式的消息缓存系统: 2.kafka集群中的服务器节点都被称作broker 3.kafka的客户端分为:一是producer(消息生产者) ...
- [转载] 快速理解Kafka分布式消息队列框架
转载自http://blog.csdn.net/xiaolang85/article/details/18048631 ==是什么 == 简单的说,Kafka是由Linkedin开发的一个分布式的消息 ...
- kafka分布式消息队列 — 基本概念介绍
[http://www.inter12.org/archives/818] 这个应该算是之前比较火热的词了,一直没时间抽出来看看.一个新东西出来,肯定是为了解决某些问题,不然不会有它的市场.先简单看下 ...
- Apache Kafka 分布式消息队列中间件安装与配置 转载
bin/zkServer.sh start /home/guym/down/kafka_2.8.0-0.8.0/config/zookeeper.properties& bin/kafka-s ...
- 在Centos 7上安装配置 Apche Kafka 分布式消息系统集群
Apache Kafka是一种颇受欢迎的分布式消息代理系统,旨在有效地处理大量的实时数据.Kafka集群不仅具有高度可扩展性和容错性,而且与其他消息代理(如ActiveMQ和RabbitMQ)相比,还 ...
- 分布式消息队列 Kafka
分布式消息队列 Kafka 2016-02-25 杜亦舒 Kafka是一个高吞吐量的.分布式的消息系统,由Linkedin开发,开发语言为scala具有高吞吐.可扩展.分布式等特点 适用场景 活动数据 ...
随机推荐
- MySQL复制表-SELECT INTO FROM
基础Table: mysql> select * from staff; +----+----------+-------+ | id | name | slary | +----+------ ...
- VC GDI 像素转厘米(英寸)[转发]
[转载]http://blog.sina.com.cn/s/blog_638dd78201018663.html 函数原型:int GetDeviceCaps(int nIndex); 常用的参数有( ...
- 第一次使用eclipse出现的问题
最近开始学习java,在一系列操作下安装好了eclipse后,按照书上的问题写了一个小程序 问题: 用户从键盘只能输入整数,程序输出这些整数的乘积. 看到这个问题后就感觉和c语言蛮像的,首先去ecli ...
- ubuntu学习笔记
Linux操作系统 locale –a查看支持语言 ls查看目录 ls .l / 查看根目录 apt-get –h 安装软件看帮助信息 sudo apt-get inatall packge 安装包 ...
- Java的实例化
实例化是什么 1.在Java中,使用已经定义好的类,创建该类对象的过程称为"实例化". 2.实例化就是在堆中分配内存的过程,分配的内存即对象. 3.只有实例化后的对象,才能访问到类 ...
- [转载]使用IEDriverServer.exe驱动IE11,实现自动化测试
转自:https://www.cnblogs.com/feiquan/p/8531618.html 下载地址: http://dl.pconline.com.cn/download/771640-1. ...
- _spellmod_aura_on_classmask
-- 修改职业所有技能,公共冷却时间.冷却时间等--小技巧: 根据职业107,108来修改(近期会有改动) `aura` 技能光环ID `spellfamily` 职业代码 `type1` 百分比还是 ...
- OpenGL.Tutorial文章转载
ZC:本来以为没有中文版的,原来有中文版,网址为: ZC: OpenGL3.0教程 _ 泰然网.html(http://www.tairan.com/archives/6126/) ZC: OpenG ...
- Android人脸识别Demo竖屏YUV方向调整和图片保存
本博客包含三个常用方法,用于盛开Android版人脸识别Demo中竖屏使用时送入yuv数据,但一直无法识别的情况. 1.首先可以尝试顺时针旋转90°或270°,然后送入识别SDK. 2.旋转方向后依然 ...
- web 后台返回json格式数据的方式(status 406)
1.在类上使用注解 @RestController public class HttpComentInterface { } 2.在方法是使用注解 @ResponseBody @RequestMap ...