A Deep Learning-Based System for Vulnerability Detection
本篇文献作者提出了一种基于深度学习来检测软件漏洞的方案。
摘要:作者开始基于深度学习的漏洞检测研究,是为了减轻专家手工定义特性的繁琐任务,需要制定一些指导性原则来适用于深度学习去进行漏洞探测。出于这个目的,作者用代码 gadgets 来代表程序,然后把它们转化为向量,其中代码gadget是一些彼此语义相关的代码行。基于这设计了评估系统VulDeePecker,作者为深度学习方法提供了最初始的漏洞数据集,实验结果表明:与其他方法相比,系统能够实现更少的误报,将系统用于Xen,Seamonkey和Libav这3个软件产品检测到了4个未报告的漏洞。
现有的漏洞检测的解决方案有两个主要缺陷:强制执行繁重的体力劳动和导致较高的误报率。在本文中作者针对以下漏洞检测提出了一个解决方案,同时考虑到这些局限性:给定目标程序的源代码,如何确定目标程序是否脆弱,如果是,漏洞在哪里。
基于以上,作者做了三部分工作:(1)开始利用深度学习进行漏洞检测的研究。这种方法具有很大的潜力,因为深度学习不需要人工定义特性,这意味着漏洞的检测可以自动化。当然深度学习的有一些指导性的初步原则,包括使深度学习应用于漏洞检测的软件程序的表示,基于深度学习的漏洞检测的粒度的确定以及漏洞检测的特定神经网络的选择。建议使用代码小部件来表示程序,代码小部件是一些(不一定是连续的)代码行,它们在语义上相互关联,可以向量化为深度学习的输入。(2)介绍了一种基于深度学习的漏洞检测系统的设计与实现,该系统被称为漏洞深度学习识别系统(VulDeePecker).有效性体现在能识别多种类型的漏洞,这就解释了VulDeePecker使用漏洞模式(作为深度神经网络学习)来检测漏洞。(3)提供了第一个用于评估VulDeePecker和其他基于深度学习的漏洞检测系统的数据集,该数据集来自美国国家标准与技术研究所(NIST)维护的两个数据源NVD[10]和软件保证参考数据集(SARD)项目[12]。数据集包含61638个代码小部件,包括17725个易受攻击的代码小部件和43913个不易受攻击的代码小部件。在17725个易受攻击的代码小部件中,10440个代码小部件对应于缓冲区错误漏洞(CWE-119),其余7285个代码小部件对应于资源管理错误漏洞(CWE-399),作者已经在https://github.com/CGCL-codes/VulDeePecker上提供了数据集。
接下来主要研究基于深度学习的漏洞检测的一些初步指导原则和VulDeePecker的设计。
一.深度学习检测漏洞的初步原则,其核心是回答三个问题(1)如何表示基于深度学习的漏洞检测程序?(2)深度学习漏洞检测的适当粒度是多少?(3)如何选择特定的神经网络进行漏洞检测?
如何表示软件程序?
由于深度学习或神经网络以向量作为输入,需要将程序表示为具有语义意义的向量,即需要将程序编码成向量,这些向量是深度学习所需要的输入。指导原则1.程序可以首先转换成某种中间表示,称为代码gadget。术语“代码小部件”的灵感来自代码重用攻击上下文中的术语"小部件"[18],代码小部件是少量(不一定是连续的)代码行。
什么是适当的粒度?
由于不仅需要检测程序是否易受攻击,而且还需要确定漏洞的位置,因此需要更细的粒度来进行基于深度学习的漏洞检测。这意味着漏洞检测不应该在程序或函数级别进行,这是非常粗粒度的,因为程序或函数可能有很多行代码,确定其漏洞位置本身就是一项困难的任务。指导原则2.为了帮助Pin定位漏洞位置,程序应该被表示为更细的粒度,而不是函数或者程序级别的。代码小部件适用于指导原则2。
如何选择神经网络?
神经网络在图像处理,语音识别,自然语言处理([21][30][40])等不同于漏洞检测的领域非常成功。这意味着许多神经网络可能不适合漏洞检测,需要一些原则来指导选择适合漏洞检测的神经网络。指导原则3.因为一行代码是否包含漏洞可能取决于上下文,能够处理上下文的神经网络可能适用于漏洞检测。这一原理表明,用于自然语言处理的神经网络可能适用于漏洞检测,因为上下文在自然语言处理[33]中很重要。将上下文的概念引入到本文的设置中,观察到程序函数调用的参数经常是受到程序中较早操作的影响,也可能受到程序中较晚操作的影响。
由于自然语言处理有许多神经网络,首先从递归神经网络(RNNs)[51][53]开始,这些神经网络在处理顺序数据方面是有效的,并且确实被用于程序分析(但不是漏洞检测的目的)[20][48][56][57].然而RNNs存在消失梯度(VG)问题,导致模型训练[16]失效。注意,VG问题是由RNNs的双向变体(BRNNs[47])继承的。
VG问题可以通过将记忆细胞植入RNNs来解决,包括长期记忆(LSTM)细胞和门控循环单元(GRU)细胞[17][22]。由于GRU在语言建模[27]上没有超过LSTM,所以作者选择LSTM进行漏洞检测。由于程序函数调用的参数可能受到程序中较早的语句影响,也有可能受到较晚的语句影响,这说明单向LSTM可能还不够,应该使用双向LSTM(BLSTM)进行漏洞检测。BLSTM神经网络图如下:
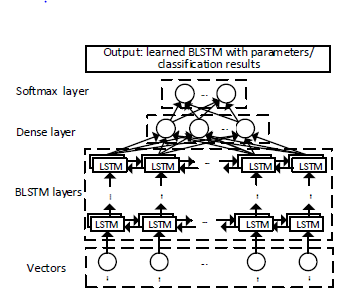 、
、
有多个BLSTM层,一个Dense层和一个Softmax层。学习过程的输入是一个确定的表示向量,BLSTM层有两个方向,向前和向后。Dense层减少了从BLSTM层接收到的向量维数,Softmax层以Dense层接收到的低维向量作为输入,负责表示和格式化结果,为学习阶段更新神经网络参数提供反馈。学习阶段的输出是一个调好模型参数的BLSTM神经网络,检测阶段的输出就是分类结果。
二.VulDeePecker的设计
A.定义代码小部件
为了用适合神经网络输入的向量表示程序,提出了将程序转换为代码小部件的表示,其定义如下:代码小部件是由许多程序语句组成的(例如,这些代码行),它们在数据依赖关系或控制关系方面在语义上彼此相关。为了生成代码小部件,提出了从关键点的启发式概念,来从特定的角度表示程序。关键点在缓冲区溢出漏洞中可以是:库/API函数调用,数组和指针。本文中,将重点讨论如何使用库/API函数调用的特定关键点来证明它在基于深度学习的漏洞检测中的有效性。
与库/API函数调用相同的关键点对应,代码小部件可以通过数据流或者程序控制流分析的方式生成,其中著名的[23]算法,[50]算法和Checkmax[2]等易于使用的商业产品。
B.VulDeePecker的概述
系统有两个阶段:学习训练阶段和检测阶段。学习阶段的输入是带有脆弱和不脆弱的大量训练项目,所谓脆弱指的是包含已知的漏洞。学习阶段的输出为被编码成BLSTM神经网络的漏洞模式。
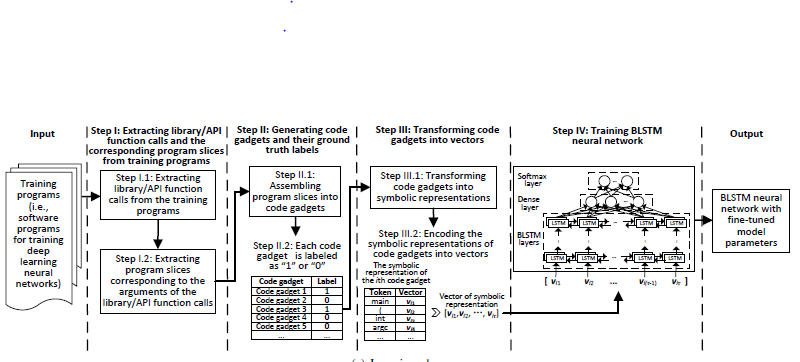
学习阶段有4个步骤:
Step 1:提取库/API函数调用和相关的的程序片段
1.1从训练程序中库/API函数的调用,同时注意VulDeePecker有关库/API函数调用的关键点。
1.2为在步骤1.1中提取的库/API函数调用的每个参数(或者变量)提取一个或多个程序片段。
Step 2:生成训练程序的代码小部件及其标定好的真实数据
2.1将步骤2.2中获得的程序片段组装为代码小片段,每一个库/API函数调用对应一个代码小部件。代码小部件不一定对应某些连续的代码行,相反,它是由多行语义相关的代码组成。
2.2对代码小部件标记真实数据。这个步骤将每个代码小部件标记为1(或0不是脆弱的),代码小部件的真实数据标签是可用的,因为我们知道训练程序是否脆弱,如果脆弱,我们就知道了脆弱的位置。
Step 3:将代码小部件转换为向量表示
3.1将代码小部件转换为特定的符号表示,稍后将对此进行详细说明。这个步骤的目的在于保存一些训练程序的语义信息。
3.2对3.1步骤中的符号表示的代码小部件进行编码为向量,这向量作为训练BLSTM神经网络的输入。
Step 4:训练BLSTM神经网络
4.1将编码小部件编码成向量并获得其标定好的真实数据后,这种训练过程对于学习BLSTM神经网络是标准的。
检测阶段是给定一个或者多个目标程序,从它们中提取库/API函数调用以及相应的程序片段,这些程序片段组装成代码小部件。这些代码小部件被转化成符号表示,然后编码成向量作为训练后的BLSTM神经网络的输入。网络输出哪些向量,因此哪些代码小部件是脆弱的("1")或者是不脆弱的("0"),如果一个代码小部件很脆弱,它会确定目标程序中漏洞的位置。如图所示:

检测阶段有2个步骤:
Step 5:将目标程序转换为代码小部件和向量
5.1从目标程序提取库/API函数调用(类似步骤1.1)
5.2根据库/API函数调用的参数提取程序片段(类似步骤1.2)
5.3将程序片段组成为代码小部件(类似步骤2.1)
5.4将代码小部件转换为它们的符号表示(类似步骤3.1)
5.5将代码小部件的符号表示编码为向量(类似步骤3.2)
Step 6:检测。这个使用学习到的BLSTM神经网络对从目标程序中提取的代码小部件相关的向量进行分类。当这个向量被分类为“1”,意味着相关的代码小部件是脆弱的,并且确定了漏洞的位置。否则队对应的相关代码小部件不是脆弱的("0")。
具体每个步骤的实现,由于时间和篇幅关系,下一节进行探讨。
A Deep Learning-Based System for Vulnerability Detection的更多相关文章
- 【RS】Deep Learning based Recommender System: A Survey and New Perspectives - 基于深度学习的推荐系统:调查与新视角
[论文标题]Deep Learning based Recommender System: A Survey and New Perspectives ( ACM Computing Surveys ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- Predicting effects of noncoding variants with deep learning–based sequence model | 基于深度学习的序列模型预测非编码区变异的影响
Predicting effects of noncoding variants with deep learning–based sequence model PDF Interpreting no ...
- 论文翻译:2021_Towards model compression for deep learning based speech enhancement
论文地址:面向基于深度学习的语音增强模型压缩 论文代码:没开源,鼓励大家去向作者要呀,作者是中国人,在语音增强领域 深耕多年 引用格式:Tan K, Wang D L. Towards model c ...
- 个性探测综述阅读笔记——Recent trends in deep learning based personality detection
目录 abstract 1. introduction 1.1 个性衡量方法 1.2 应用前景 1.3 伦理道德 2. Related works 3. Baseline methods 3.1 文本 ...
- Paper Reading——LEMNA:Explaining Deep Learning based Security Applications
Motivation: The lack of transparency of the deep learning models creates key barriers to establishi ...
- A Deep Learning-Based System for Vulnerability Detection(二)
接着上一篇,这篇研究实验和结果. A.用于评估漏洞检测系统的指标 TP:为正确检测到漏洞的样本数量 FP:为检测到虚假漏洞样本的数量(误报) FN:为未检真实漏洞的样本数量(漏报) TN:未检测到漏洞 ...
- A Deep Learning-Based System for Vulnerability Detection(一)
接着上一篇,讨论讨论具体步骤实现方法.步骤1-3分别在下面进行阐述,步骤4,6都是标准的,步骤5类似于步骤1-3. 结合这个图进行讨论详细步骤: 步骤1:提取库/API函数调用和程序片段 1.1将库/ ...
- (转) Deep Learning Resources
转自:http://www.jeremydjacksonphd.com/category/deep-learning/ Deep Learning Resources Posted on May 13 ...
随机推荐
- Spring Boot 2.0 教程 | @ModelAttribute 注解
欢迎关注微信公众号: 小哈学Java 文章首发于个人网站: https://www.exception.site/springboot/spring-boot-model-attribute Spri ...
- How does the vuejs add the query and walk the object?
让这个老实返回的页面添加特殊路由,这个页面常常都是登录注册.这次我们根据登录举例. 省略 { path:'/login?url=:url', name:'loginfirst', component: ...
- C++可变参数模板实现输出
C++11 tuple&可变参数模板 template void Print(T value) { std::cout << value << std::endl; } ...
- Zookeeper知识点
Zookeeper是一个分布式协调服务 Zookeeper服务器的角色 Leader: 所有的写操作必须要经过Leader完成,在广播给其它服务器.心跳检测.集群中只有一个Leader. Follow ...
- 关于ML.NET v1.0 RC的发布说明
ML.NET是面向.NET开发人员的开源和跨平台机器学习框架(Windows,Linux,macOS).使用ML.NET,开发人员可以利用他们现有的工具和技能组,通过为情感分析,推荐,图像分类等常见场 ...
- 使用ML.NET实现NBA得分预测
使用ML.NET实现NBA得分预测 导读:ML.NET系列文章 ML.NET已经发布了v0.2版本,新增了聚类训练器,执行性能进一步增强.本文将介绍一种特殊的回归--泊松回归,并以NBA比赛得分预测的 ...
- Android下实现数据绑定功能
在编写Android应用的时候经常需要做的事情就是对View的数据进行设置,在Android下设置控件相对.net来说是件麻烦的事情,首先根据ID从view把控件找出来然后才能设置相应属性值:如果数据 ...
- TCP/IP 三次握手
网络连接状态 网络连接状态(11种)非常重要这里既包含三次握手中的也包括四次断开中的,所以要熟悉. LISTEN 被动打开,首先服务器需要打开一个socket进行监听,监听来自远方TCP端口的连接请求 ...
- springboot+mybatis+dubbo+aop日志第二篇
本篇主要介绍dubbo-demo-api接口层和dubbo-demo-service层,以及如何通过dubbo把服务发布出去,介绍代码前,咱们先来回顾一下整个demo工程的结构,如下图所示: 1.du ...
- flume 1.8.0 开发基础
本文由云+社区发表 作者:皮皮熊 概述 Apache Flume是一个用于高效地从大量异构数据源收集.聚合.传输到一个集中式数据存储的分布式.高可靠.高可用的系统. Apache Flume是Apac ...