学习ActiveMQ(八):activemq消息的持久化
1. 持久化方式介绍
前面我们也简单提到了activemq提供的插件式的消息存储,在这里再提一下,主要有以下几种方式:
AMQ消息存储-基于文件的存储方式,是activemq开始的版本默认的消息存储方式;
KahaDB消息存储-提供了容量的提升和恢复能力,是现在的默认存储方式;
JDBC消息存储-消息基于JDBC存储的;
Memory消息存储-基于内存的消息存储,由于内存不属于持久化范畴,而且如果使用内存队列,可以考虑使用更合适的产品,如ZeroMQ。所以内存存储不在讨论范围内。
上面几种消息存储方式对于消息存储的逻辑来说并没有什么区别,只是在性能以及存储方式上来说有所不同。但是对于消息发送的方式来说,p2p和Pub/Sub两种类型的消息他们的持久化方式却是不同的:
对于点对点的消息一旦消费者完成消费这条消息将从broker上删除;对于发布订阅类型的消息,即使所有的订阅者都完成了消费,Broker也不一定会马上删除无用消息,而是保留推送历史,之后会异步清除无用消息。而每个订阅者消费到了哪条消息的offset会记录在Broker,以免下次重复消费。因为消息是顺序消费,先进先出,所以只需要记录上次消息消费到哪里就可以了。
因为AMQ现在已经被不再使用被KahaDB所替代,所以我们就讲KahaDB,JDBC消息存储在许多对可靠性要求高而对性能要求低一些的大公司还是经常使用的,下面我们就这两种持久化方式的使用做一节专题。
2. Kahadb
说到Kahadb之前我们还是得提到他的前身AMQ,AMQ是一种文件存储形式,他具有写入速度快和容易恢复的特点,消息存储在一个个的文件里,文件默认大小为32M,超过这个大小的消息将会存入下一个文件。当一个文件中的消息已经全部消费,那么这个文件将被标志我可删除,在下一个清除阶段这个文件将被删除。
如果需要使用持久化,则需要在前文中的配置文件applicationContext-ActiveMQ.xml中增加如下配置:
<persistenceAdapter>
<kahaDB directory="activemq-data"journalMaxFileLength="32mb"/>
</persistenceAdapter>
KahaDB的属性件如下
属性名称 属性值 描述
directory activemq-data 消息文件和日志的存储目录
indexWriteBatchSize 1000 一批索引的大小,当要更新的索引量到达这个值时,更新到消息文件中
indexCacheSize 1000 内存中,索引的页大小
enableIndexWriteAsync false 索引是否异步写到消息文件中
journalMaxFileLength 32mb 一个消息文件的大小
enableJournalDiskSyncs true 是否讲非事务的消息同步写入到磁盘
cleanupInterval 30000 清除操作周期,单位ms
checkpointInterval 5000 索引写入到消息文件的周期,单位ms
ignoreMissingJournalfiles false 忽略丢失的消息文件,false,当丢失了消息文件,启动异常
checkForCorruptJournalFiles false 检查消息文件是否损坏,true,检查发现损坏会尝试修复
checksumJournalFiles false 产生一个checksum,以便能够检测journal文件是否损坏。
5.4版本之后有效的属性:
archiveDataLogs false 当为true时,归档的消息文件被移到directoryArchive,而不是直接删除
directoryArchive null 存储被归档的消息文件目录
databaseLockedWaitDelay 10000 在使用负载时,等待获得文件锁的延迟时间,单位ms
maxAsyncJobs 10000 同个生产者产生等待写入的异步消息最大量
concurrentStoreAndDispatchTopics false 当写入消息的时候,是否转发主题消息
concurrentStoreAndDispatchQueues true 当写入消息的时候,是否转发队列消息
5.6版本之后有效的属性:
archiveCorruptedIndex false 是否归档错误的索引
由于在ActiveMQ V5.4+的版本中,KahaDB是默认的持久化存储方案。所以即使你不配置任何的KahaDB参数信息,ActiveMQ也会启动KahaDB。这种情况下,KahaDB文件所在位置是你的ActiveMQ安装路径下的/data/broker.Name/KahaDB子目录。其中broker.Name/KahaDB子目录。其中{broker.Name}代表这个ActiveMQ服务节点的名称。下面我把刚启动服务并发送了消息之后的activemq安装目录打开给大家看看:
正式的生产环境还是建议在主配置文件中明确设置KahaDB的工作参数:
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="broker" persistent="true" useShutdownHook="false">
...
<persistenceAdapter>
<kahaDB directory="activemq-data"
journalMaxFileLength="32mb"
concurrentStoreAndDispatchQueues="false"
concurrentStoreAndDispatchTopics="false"
/>
</persistenceAdapter>
</broker>
3.持久化到数据库
步骤1:需要将mysql的驱动包放置到ActiveMQ的lib目录下(mysql-connector-java-5.1.30.jar)
步骤2:修改activeMQ的配置文件如下:两处地方
<persistenceAdapter>
<!--<kahaDB directory="${activemq.base}/data/kahadb"/>-->
<jdbcPersistenceAdapter dataDirectory="${activemq.base}/data" dataSource="#mysql-ds" useDatabaseLock="false" createTablesOnStartup="false"/>
</persistenceAdapter>
在配置文件中的broker节点外( </broker>下方)增加:
<!-- MySql DataSource Sample Setup -->
<bean id="mysql-ds" class="org.apache.commons.dbcp2.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/activemqdb?relaxAutoCommit=true"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
<property name="poolPreparedStatements" value="true"/>
</bean> <!-- Oracle DataSource Sample Setup
<bean id="db2-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.ibm.db2.jcc.DB2Driver"/>
<property name="url" value="jdbc:db2://hndb02.bf.ctc.com:50002/activemq"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
<property name="maxActive" value="200"/>
<property name="poolPreparedStatements" value="true"/>
</bean> -->
从配置中可以看出数据库的名称是activemq,你需要手动在MySql中增加这个库,这个数据库要先存在。然后重新启动activeMQ(启动建议启动activemq.bat方式,报错信息可以在命令行看到),会发现activemq多了三张表:从配置中可以看出数据库的名称是activemq,需要手动在MySql中建立这个数据库。(一下三张图是我在别人那里看到,画的很详细,特此感谢博主:技术宅home)
activemq_acks:用于存储订阅关系。如果是持久化Topic,订阅者和服务器的订阅关系在这个表保存
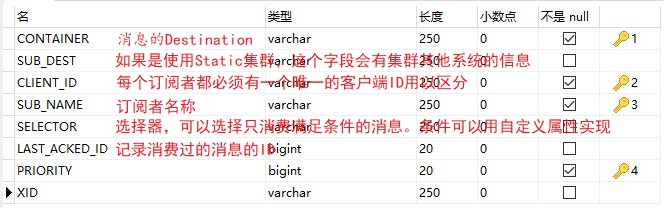
activemq_lock:在集群环境中才有用,只有一个Broker可以获得消息,称为Master Broker

activemq_msgs:用于存储消息,Queue和Topic都存储在这个表中
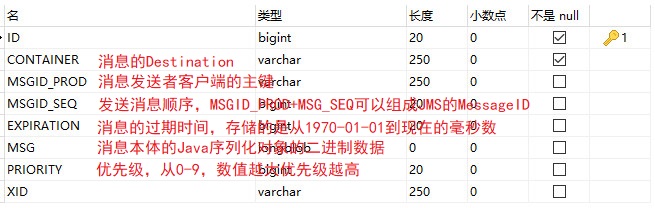
感兴趣的可以去验证一下,启动一个点对点模式的生产者,不要启动消费者,否则会被马上接收,来不及持久化。会发现数据库消息表中有一条消息了

然后启动消费者,会发现表中的数据就会删除了。

持久化表中最后没有被的数据一般是死亡队列中消息和在消息队列中等待被消费确认的消息。
学习ActiveMQ(八):activemq消息的持久化的更多相关文章
- JMS学习(五)--ActiveMQ中的消息的持久化和非持久化 以及 持久订阅者 和 非持久订阅者之间的区别与联系
一,消息的持久化和非持久化 ①DeliveryMode 这是传输模式.ActiveMQ支持两种传输模式:持久传输和非持久传输(persistent and non-persistent deliver ...
- SpringCloud学习(八)消息总线(Spring Cloud Bus)(Finchley版本)
Spring Cloud Bus 将分布式的节点用轻量的消息代理连接起来.它可以用于广播配置文件的更改或者服务之间的通讯,也可以用于监控.本文要讲述的是用Spring Cloud Bus实现通知微服务 ...
- JMS学习九(ActiveMQ的消息持久化到Mysql数据库)
1.将连接Mysql数据库的jar文件,放到ActiveMQ的lib目录下 2.修改ActiveMQ的conf目录下的active.xml文件,修改数据持久化的方式 2.1 修改原来的kshadb的 ...
- JMS学习三(ActiveMQ消息的可靠性)
下面我们来学习一下消息接受确认和发送持久化消息.消息的过期.消息的选择器和消息的优先级. 一.消息接收确认 1.jms消息只有在被确认之后才认为成功消费了这条消息.消息的成功消费通常包括三个步骤:(1 ...
- JMS学习六(ActiveMQ消息传送模型)
ActiveMQ 支持两种截然不同的消息传送模型:PTP(即点对点模型)和Pub/Sub(即发布 /订阅模型),分别称作:PTP Domain 和Pub/Sub Domain. 一.PTP消息传送模型 ...
- ActiveMQ(3)---ActiveMQ原理分析之消息持久化
持久化消息和非持久化消息的存储原理 正常情况下,非持久化消息是存储在内存中的,持久化消息是存储在文件中的.能够存储的最大消息数据在${ActiveMQ_HOME}/conf/activemq.xml文 ...
- ActiveMQ消息的持久化策略
持久化消息和非持久化消息的存储原理: 正常情况下,非持久化消息是存储在内存中的,持久化消息是存储在文件中的.能够存储的最大消息数据在${ActiveMQ_HOME}/conf/activemq.xml ...
- JMS服务器ActiveMQ的初体验并持久化消息到MySQL数据库中
JMS服务器ActiveMQ的初体验并持久化消息到MySQL数据库中 一.JMS的理解JMS(Java Message Service)是jcp组织02-03年定义了jsr914规范(http://j ...
- 消息中间件-activemq实战之消息持久化(六)
对于activemq消息的持久化我们在第二节的时候就简单介绍过,今天我们详细的来分析一下activemq的持久化过程以及持久化插件.在生产环境中为确保消息的可靠性,我们肯定的面临持久化消息的问题,今天 ...
- AMQP学习 & RabbitMQ 与 ActiveMQ、ZeroMQ以及Kafka的比较
之前写了一篇文章关于Active以及消息队列推拉模式的文章,可以参考:link 关于 Active 与 RabbitMQ以及其他的比较,有如下记录: 这篇文章 link 提到: 基本介绍RabbitM ...
随机推荐
- HTTP协议08-请求首部字段
请求首部字段 请求首部字段是从客户端往服务器端发送请求报文中所使用的字段,用于补充请求的附加信息.客户端信息,对响应内容相关的优先级等内容 1)Accept 通知服务器,用户代理能够处理的媒体类型及媒 ...
- 【easy】367. Valid Perfect Square 判断是不是平方数
class Solution { public: bool isPerfectSquare(int num) { /* //方法一:蜜汁超时…… if (num < 0) return fals ...
- Python--可迭代对象,迭代器,生成器
记得在刚开始学Python的时候,看到可迭代对象(iterable).迭代器(iterator)和生成器(generator)这三个名词时,完全懵逼了,根本就不知道是啥意识.现在以自己的理解来详解下这 ...
- SpringBoot整合mybatis多数据源,支持分布式事务
编码工具:IDEA SpringBoot版本:2.0.1 JDK版本:1.8 1.使用IDEA构建一个Maven工程 ,添加依赖: <?xml version="1.0" e ...
- Redis在CentOS和Windows安装过程
redis是一种key-value高效的内存数据库. key-value是什么?json懂吧?字典懂吧?这些都是key-value结构的数据,每个key对应1个value. 那这个数据库和我们网站在使 ...
- 使用OpenCV训练好的级联分类器识别人脸
一.使用OpenCV训练好的级联分类器来识别图像中的人脸 当然还有很多其他的分类器,例如表情识别,鼻子等,具体可在这里下载: OpenCV分类器 import cv2 # 矩形颜色和描边 color ...
- [原创]SVN使用
在企业中,SVN环境,由企业已经搭建好,并提供相关技术支持.对于个人,如果想在个人PC上实现版本管理,亦可以实现.安装Visual SVN及其相关工具 如何使用,可见下链接 http://www.cn ...
- Kafka(二)CentOS7.5搭建Kafka2.11-1.1.0集群与简单测试
一.下载 下载地址: http://kafka.apache.org/downloads.html 我这里下载的是Scala 2.11对应的 kafka_2.11-1.1.0.tgz 二.kaf ...
- html_基础标签
块级标签: 默认情况会占位一整行行内(内联)标签:默认只有自己的大小 块级标签如: <div>我是字</div> <h1>标题1</h1> < ...
- Mysql数据实时同步
企业运维的数据库最常见的是 mysql;但是 mysql 有个缺陷:当数据量达到千万条的时候,mysql 的相关操作会变的非常迟缓; 如果这个时候有需求需要实时展示数据;对于 mysql 来说是一种灾 ...