Random Forest总结
一、简介

RF = Bagging + Decision Tree
随机:数据采样随机,特征选择随机
森林:多个决策树并行放在一起

几个误区:
- 不是每棵树随机选择特征,而是每一个结点都随机选择固定数目的特征
- 采样。样本数量为N,采样数量也为N,但是采取的是有放回的采样(bootstrap)。
- 组合算法。训练结束之后,对新数据进行预测的时候,会让新数据在所有得到的M个决策树上进行预测,最后对结果进行平均或者进行投票。最早的算法是投票:每个树对每一类投票,sklearn的算法是对各个树进行了平均取结果。
- 分类和回归。随机森林可以做分类,也可以做回归,但是很显然(实践上也是),做回归有点不靠谱,所以研究随机森林回归意思不大。
- 假设总共有1-6个特征,如果第一个节点随机选出了1、2、3这三个特征,然后根据信息增益保留了1;然后第二个节点随机选择特征是在2-6选择还是1-6中选择呢?答案还是从1-6中选择增益最大的特征
1.RF的算法的流程?

Bagging和Decison Tree算法各自有一个很重要的特点。Bagging具有减少不同gt的方差variance的特点。这是因为Bagging采用投票的形式,将所有gt uniform结合起来,起到了求平均的作用,从而降低variance。而Decision Tree具有增大不同gt的方差variance的特点。这是因为Decision Tree每次切割的方式不同,而且分支包含的样本数在逐渐减少,所以它对不同的资料D会比较敏感一些,从而不同的D会得到比较大的variance。
所以说,Bagging能减小variance,而Decision Tree能增大variance。如果把两者结合起来,能否发挥各自的优势,起到优势互补的作用呢?这就是我们接下来将要讨论的aggregation of aggregation,即使用Bagging的方式把众多的Decision Tree进行uniform结合起来。这种算法就叫做随机森林(Random Forest),它将完全长成的C&RT决策树通过bagging的形式结合起来,最终得到一个庞大的决策模型。


(1)随机抽取资料
(2)随机抽取特征
【1】随机抽取特征

所以说,这种增强的Random Forest算法增加了random-subspace。

【2】组合特征
上面我们讲的是随机抽取特征,除此之外,还可以将现有的特征x,通过数组p进行线性组合,来保持多样性:


所以,这里的Random Forest算法又有增强,由原来的random-subspace变成了random-combination。顺便提一下,这里的random-combination类似于perceptron模型。

2.Out-of-Bag Estimate
上一部分我们已经介绍了Random Forest算法,而Random Forest算法重要的一点就是Bagging。接下来将继续探讨bagging中的bootstrap机制到底蕴含了哪些可以为我们所用的东西。
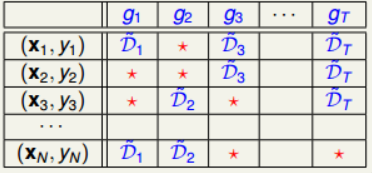
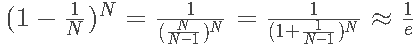
其中,e是自然对数,N是原样本集的数量。由上述推导可得,每个gt中,OOB数目大约是1/e*N ,即大约有三分之一的样本没有在bootstrap中被抽到。
然后,我们将OOB与之前介绍的Validation进行对比:




3.RF如何选择特征 ?

特征选择的优点是:
- 提高效率,特征越少,模型越简单
- 正则化,防止特征过多出现过拟合
- 去除无关特征,保留相关性大的特征,解释性强
同时,特征选择的缺点是:
- 筛选特征的计算量较大
- 不同特征组合,也容易发生过拟合
- 容易选到无关特征,解释性差
(1)线性模型
值得一提的是,在decision tree中,我们使用的decision stump切割方式也是一种feature selection。那么,如何对许多维特征进行筛选呢?我们可以通过计算出每个特征的重要性(即权重),然后再根据重要性的排序进行选择即可。


(2)非线性模型
RF中,特征选择的核心思想是random test。random test的做法是对于某个特征,如果用另外一个随机值替代它之后的表现比之前更差,则表明该特征比较重要,所占的权重应该较大,不能用一个随机值替代。相反,如果随机值替代后的表现没有太大差别,则表明该特征不那么重要,可有可无。所以,通过比较某特征被随机值替代前后的表现,就能推断出该特征的权重和重要性。
那么random test中的随机值如何选择呢?通常有两种方法:一是使用uniform或者gaussian抽取随机值替换原特征;一是通过permutation的方式将原来的所有N个样本的第i个特征值重新打乱分布(相当于重新洗牌)。比较而言,第二种方法更加科学,保证了特征替代值与原特征的分布是近似的(只是重新洗牌而已)。这种方法叫做permutation test(随机排序测试),即在计算第i个特征的重要性的时候,将N个样本的第i个特征重新洗牌,然后比较D和D^(p)表现的差异性。如果差异很大,则表明第i个特征是重要的。

 也就是说,在训练的时候仍然使用D,但是在OOB验证的时候,将所有的OOB样本的第i个特征重新洗牌,验证G的表现。这种做法大大简化了计算复杂度,在RF的feature selection中应用广泛。
也就是说,在训练的时候仍然使用D,但是在OOB验证的时候,将所有的OOB样本的第i个特征重新洗牌,验证G的表现。这种做法大大简化了计算复杂度,在RF的feature selection中应用广泛。
4.RF的参数有哪些,如何调参 ?
(1)n_estimators是森林里树的数量,通常数量越大,效果越好,但是计算时间也会随之增加。 此外要注意,当树的数量超过一个临界值之后,算法的效果并不会很显著地变好。
(2)max_features是分割节点时考虑的特征的随机子集的大小。 这个值越低,方差减小得越多,但是偏差的增大也越多。
- 回归问题中使用 max_features = n_features
- 分类问题使用 max_features = sqrt(n_features )(其中 n_features 是特征的个数)是比较好的默认值。 max_depth = None 和 min_samples_split = 2 结合通常会有不错的效果(即生成完全的树)。
(3)warm_start=False:热启动,决定是否使用上次调用该类的结果然后增加新的。
进行预测可以有几种形式:
predict(x):直接给出预测结果。内部还是调用的predict_proba(),根据概率的结果看哪个类型的预测值最高就是哪个类型。
predict_log_proba(x):和predict_proba基本上一样,只是把结果给做了log()处理。
默认参数下模型复杂度是:O(M*N*log(N)) , 其中 M 是树的数目, N 是样本数。 可以通过设置以下参数来降低模型复杂度: min_samples_split , min_samples_leaf , max_leaf_nodes`` 和 ``max_depth 。
5.RF的优缺点 ?
优点:
- 不同决策树可以由不同主机并行训练生成,效率很高;
- 随机森林算法继承了CART的优点;
- 将所有的决策树通过bagging的形式结合起来,避免了单个决策树造成过拟合的问题。
缺点:
- 当我们需要推断超出范围的独立变量或非独立变量,随机森林做得并不好,我们最好使用如 MARS 那样的算法。
- 随机森林算法在训练和预测时都比较慢。
- 如果需要区分的类别十分多,随机森林的表现并不会很好。
参考文献:
【1】林轩田机器学习技法课程学习笔记10 — Random Forest
Random Forest总结的更多相关文章
- [Machine Learning & Algorithm] 随机森林(Random Forest)
1 什么是随机森林? 作为新兴起的.高度灵活的一种机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应用前景,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来 ...
- paper 85:机器统计学习方法——CART, Bagging, Random Forest, Boosting
本文从统计学角度讲解了CART(Classification And Regression Tree), Bagging(bootstrap aggregation), Random Forest B ...
- paper 56 :机器学习中的算法:决策树模型组合之随机森林(Random Forest)
周五的组会如约而至,讨论了一个比较感兴趣的话题,就是使用SVM和随机森林来训练图像,这样的目的就是 在图像特征之间建立内在的联系,这个model的训练,着实需要好好的研究一下,下面是我们需要准备的入门 ...
- 多分类问题中,实现不同分类区域颜色填充的MATLAB代码(demo:Random Forest)
之前建立了一个SVM-based Ordinal regression模型,一种特殊的多分类模型,就想通过可视化的方式展示模型分类的效果,对各个分类区域用不同颜色表示.可是,也看了很多代码,但基本都是 ...
- Ensemble Learning 之 Bagging 与 Random Forest
Bagging 全称是 Boostrap Aggregation,是除 Boosting 之外另一种集成学习的方式,之前在已经介绍过关与 Ensemble Learning 的内容与评价标准,其中“多 ...
- Aggregation(1):Blending、Bagging、Random Forest
假设我们有很多机器学习算法(可以是前面学过的任何一个),我们能不能同时使用它们来提高算法的性能?也即:三个臭皮匠赛过诸葛亮. 有这么几种aggregation的方式: 一些性能不太好的机器学习算法(弱 ...
- Plotting trees from Random Forest models with ggraph
Today, I want to show how I use Thomas Lin Pederson's awesome ggraph package to plot decision trees ...
- Random Forest Classification of Mushrooms
There is a plethora of classification algorithms available to people who have a bit of coding experi ...
- 统计学习方法——CART, Bagging, Random Forest, Boosting
本文从统计学角度讲解了CART(Classification And Regression Tree), Bagging(bootstrap aggregation), Random Forest B ...
- 机器学习 数据挖掘 推荐系统机器学习-Random Forest算法简介
Random Forest是加州大学伯克利分校的Breiman Leo和Adele Cutler于2001年发表的论文中提到的新的机器学习算法,可以用来做分类,聚类,回归,和生存分析,这里只简单介绍该 ...
随机推荐
- JavaScript我学之七数组
本文是金旭亮老师网易云课堂的课程笔记,记录下来,以供备忘. 数组是“多态数组" ,啥都可以放 //JavaScript中的多态数组 var arr = ["one", 2 ...
- pandas设置值-【老鱼学pandas】
本节主要讲述如何根据上篇博客中选择出相应的数据之后,对其中的数据进行修改. 对某个值进行修改 例如,我们想对数据集中第2行第2列的数据进行修改: import pandas as pd import ...
- 2017-2018 ACM-ICPC Pacific Northwest Regional Contest (Div. 1)
A. Odd Palindrome 所有回文子串长度都是奇数等价于不存在长度为$2$的偶回文子串,即相邻两个字符都不同. #include<cstdio> #include<cstr ...
- org.hibernate.exception.SQLGrammarException: could not extract ResultSet &&&&&Incorrect syntax near '@P0'.
这个故障的原因比较多: 1.如数据库中的字段和类中的字段类型不一致: 2.数据库dialect不够具体 myeclispe自动生成的是 org.hibernate.dialect.SQLServer ...
- 201771010126 王燕《面向对象程序设计(java)》第八周学习总结
实验六 接口的定义与使用 实验时间 2018-10-18 1.实验目的与要求 (1) 掌握接口定义方法 JAVA中通过interface关键字定义接口: 接口中只能定义public static fi ...
- 在Linux下开发多语言软件(gettext解决方案)
最近的项目出现了一个bug.项目是基于一个已有的成熟开源软件之上做修改的,新写了加解密库,用于为该成熟开源软件增添加解密功能.功能增加完成后效果都很好,可是就是中文出不来了,也就是说没办法自适应多语言 ...
- CXF安装和配置时出现Exception in thread "main" java.lang.UnsupportedClassVersionError:异常?
异常信息: C:\Users\>wsdl2java -h Exception in thread "main" java.lang.UnsupportedClassVersi ...
- document.querySelectorAll() 兼容 IE6
不多说,直接上代码 // 使用 css 选择器获取元素对象 兼容性封装 Test Already. function getElementsByCss(cssStr){ if(document.que ...
- cmd 命令 net start mongodb 启动不了,提示 net 不是内部命令或者外部命令
1.要管理员的身份进入 cmd 2.右击我的电脑-->属性-->高级系统设置 3.选择高级-->环境变量 4.找到系统变量-->Path-->编辑 5.把 C:\wind ...
- css3图形绘制
以下几个例子主要是运用了css3中border.bordr-radius.transform.伪元素等属性来完成的,我们先了解下它们的基本原理. border:简单的来说border语法主要包含(bo ...