SQL Data Discovery and Classification
The new version of SQL Server Management Studio (v17.5) brings with it a new feature: SQL Data Discovery and Classification. You might recall that in SSMS 17.4, the Vulnerability Assessment feature was added. So, that’s two new features in the last two releases. This is the beauty of de-coupling SSMS from the SQL Server install media. We get more features, faster. But I digress.
The SQL Data Discovery and Classification feature will seem familiar to anyone working with Dynamic Data Masking in Azure. Both features use T-SQL to parse the names of columns to identify and classify the data. (This feature is also available in the Data Migration Assistant, where you can get a list of columns that would benefit from either Dynamic Data Masking or Always Encrypted.)
The SQL Data Discovery and Classification feature will help users discover, classify, and label columns that contain sensitive data. The feature also allows for the generation of reports for auditing purposes. With GDPR less than three months away, this could be the one feature that helps your company remain compliant.
Running SQL Data Discovery and Classification
Using the Data Discovery and Classification tool is easy. Just select a database and right-click. Go to Tasks > Classify Data…. Here is an example using a test GalacticWorks database:
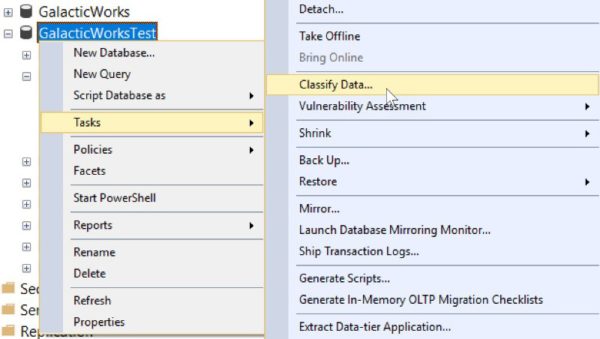
My GalacticWorksTest database has only one table, a copy of the AdventureWorks2012.Sales.CreditCard table. You can see the results of the scan here:
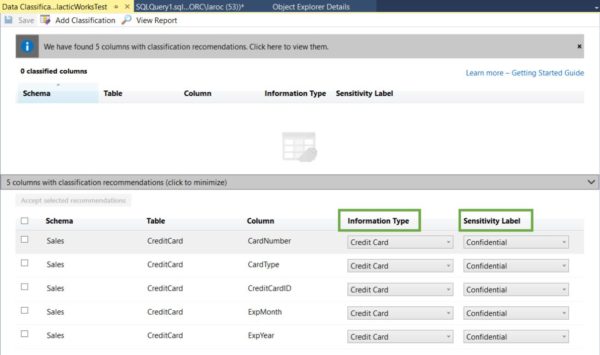
I’ve highlighted the Information Type and Sensitivity Label column headers. I want to make certain you understand these columns represent dropdown windows, allowing you to alter both as needed.
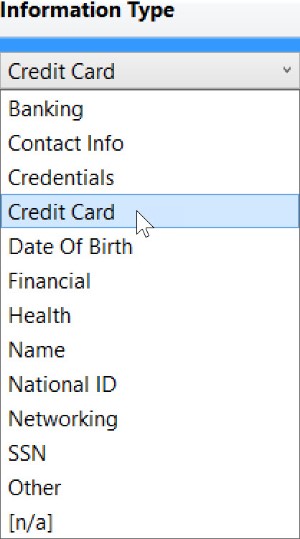
The options for Information Type are as follows: Banking, Contact Info, Credentials, Credit Card, Date Of Birth, Financial, Health, Name, National ID, Networking, SSN, Other, and [n/a]. Here’s what the drop-down looks like:
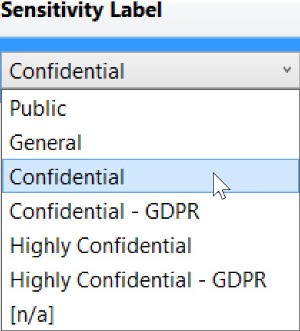
The options for Sensitivity Label are as follows: Public, General, Confidential, Confidential – GDPR, Highly Confidential, Highly Confidential – GDPR, and [n/a]. Here’s what the drop-down looks like:
SQL Data Discovery and Classification With Non-English Names
Since the feature is parsing column names, we will create a new table and use non-English names. We will also use abbreviations for column names for those of you old experienced enough to remember when abbreviations were in vogue.
OK, let’s create a new table:
CREATE TABLE [Sales].[Tarjeta](
[TarjetaCreditoID] [int] IDENTITY(1,1) NOT NULL,
[TarjetaTipo] [nvarchar](50) NOT NULL,
[TarjetaNumero] [nvarchar](25) NOT NULL,
[TARNUM] [nvarchar](25) NOT NULL,
[ExpMonth] [tinyint] NOT NULL,
[ExpYear] [smallint] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Tarjeta_TarjetaCreditoID] PRIMARY KEY CLUSTERED
([TarjetaCreditoID] ASC
)ON [PRIMARY])
ON [PRIMARY]
GO
I’ve created a table almost identical to the Sales.CreditCard table, except that I am using Spanish names for credit (credito), card tarjeta), number (numero), and type (tipo). I’ve also added a column TARNUM, an abbreviation for the TarjetaNumero column. That’s the column that would have actual credit card numbers.
We will re-run the classification again (make sure you close the first results; otherwise, you won’t get a refresh with the new table included). Also note that I don’t need data in the table for this feature to evaluate the columns. I haven’t loaded any rows into Sales.Tarjeta, and here’s the result (I’ve scrolled down to show the three new rows):
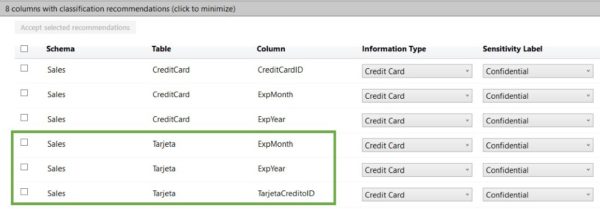
The Data Discovery and Classification tool identified three columns: ExpMonth, ExpYear, and CreditoID. However, it missed TarjetaNumero and TARNUM, which would have the actual credit card numbers. The TarjetaCreditID column has no card number, just an IDENTITY(1,1) value used for a primary key.
One last item of interest. When a column is classified, the details are stored as extended properties. Here’s an example:
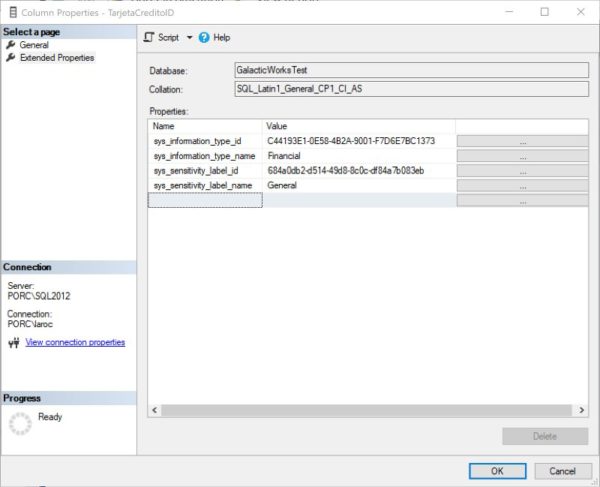
You can see that the Data Discovery and Classification feature does not flag the columns I created for this test. Because the feature focuses on keywords, it’s expected behavior that columns will be skipped. There are two reasons why. The first is the fact that the use of keywords has some cultural bias. For example, SSN is flagged as a keyword for the American Social Security Number. But in the Netherlands, it’s possible to have SOFINR as a column name abbreviation for Social Fiscal Number, and SOFINR is currently not flagged.
The second reason is that the feature only supports English, and offers partial support for a handful of non-English languages (Spanish, Portuguese, French, German, and Italian). (As I’m writing this at the SQL Konferenz in Germany, I found that Personalausweis, the name for the German Identification card, is flagged.) However, the MSDN I provided earlier makes no mention of supported languages or collations. I’m hoping that the MSDN pages get updates to reflect the languages and collations that are supported, to avoid any confusion for users.
Data Discovery and Classification Reports
Once you have reviewed and classified your data, you will want to run a report. Using AdventureWorks2008 as an example, I will accept all 39 recommendations and click Save > View Report. Here’s the result:
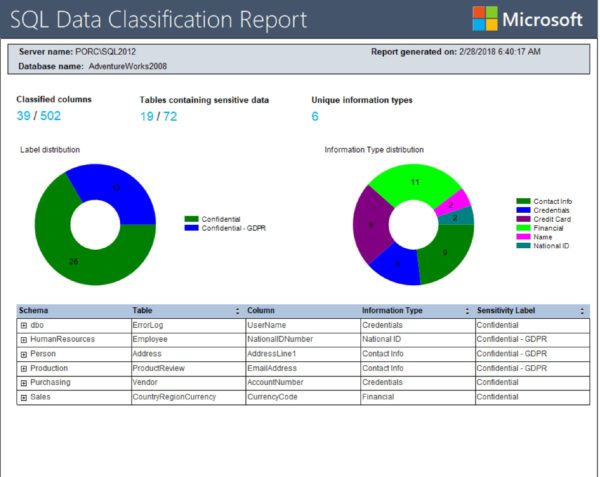
The report shows that the AdventureWorks2008 database has 39 distinct columns in 19 distinct tables that have been classified. This is the information you can now hand over to your audit team.
This report is at the database level. That means you will need to roll your own solution to get the details from many databases at the same time. It should be possible to use some Powershell voodoo to extract the data. Or, better yet, fire up PowerBI and use that to build your own dashboard.
Summary
The SQL Data Discovery and Classification feature is a great first step by Microsoft to help users understand where sensitive data may exist in their enterprise. This is also a good time to remind you why having a data dictionary is important. Even with all the right tools in place, all the right people, using all the right knowledge, you will still miss a column of sensitive data at times.
That’s because life is dirty, and so’s your data. Identifying and classifying data is not an easy task. You won’t get a perfect result with a simple right-click of a mouse. It takes diligence on the part of the data professional to curate the necessary metadata for data classification. Not every data professional has the time or patience for such efforts.
But the Data Discovery and Classification tool is a great first step forward. I can’t wait to watch this feature as it grows.
SQL Data Discovery and Classification的更多相关文章
- ref:Manual SQL injection discovery tips
ref:https://gerbenjavado.com/manual-sql-injection-discovery-tips/ Manual SQL injection discovery tip ...
- 使用Red Gate Sql Data Compare 数据库同步工具进行SQL Server的两个数据库的数据比较、同步
Sql Data Compare 是比较两个数据库的数据是否相同.生成同步sql的工具. 这一款工具由Red Gate公司出品,我们熟悉的.NET Reflector就是这个公司推出的,它的SQLTo ...
- C and SQL data types for ODBC and CLI
C and SQL data types for ODBC and CLI This topic lists the C and SQL data types for ODBC and CLI a ...
- Azure SQL Data Warehouse
Azure SQL Data Warehouse & AWS Redshift Amazon Redshift Amazon Redshift 是一种快速.完全托管的 PB 级数据仓库,可方便 ...
- Mysql ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA
ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declar ...
- this function has none of deterministic, no sql,or reads sql data in its declaration and binary logging is enabled
原址:http://blog.chinaunix.net/uid-20639775-id-3031821.html This function has none of DETERMINISTI ...
- Red Gate系列之四 SQL Data Compare 10.2.0.885 Edition 数据比较同步工具 完全破解+使用教程
原文:Red Gate系列之四 SQL Data Compare 10.2.0.885 Edition 数据比较同步工具 完全破解+使用教程 Red Gate系列之四 SQL Data Compare ...
- SQL data reader reading data performance test
/*Author: Jiangong SUN*/ As I've manipulated a lot of data using SQL data reader in recent project. ...
- This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its de 错误解决办法
这是我们开启了bin-log, 我们就必须指定我们的函数是否是1 DETERMINISTIC 不确定的2 NO SQL 没有SQl语句,当然也不会修改数据3 READS SQL DATA 只是读取数据 ...
随机推荐
- ECMASCript 2019可能会有哪些特性?
最近这些年,ECMASCript标准发展节奏非常稳定,每年都会发布新的特性.那么,ECMASCript 2019可能会有哪些特性呢? ECMASCript语法提案的批准流程 JavaScript的标准 ...
- Web前端 页面功能——点击按钮返回顶部的实现方法
1. 最简单的静态返回顶部,点击直接跳转页面顶部,常见于固定放置在页面底部返回顶部功能 方法一:用命名锚点击返回到顶部预设的id为top的元素 html代码 <a href="#top ...
- max-width和width的区别
width为宽度 max-width为最大宽度 如果设置了width,那宽度就定死了,不能动态的改变,显得僵硬 而设置了max-width,实际宽度可以在0~max-width之间,当元素内部宽度不足 ...
- SpreadJS使用进阶指南 - 使用 NPM 管理你的项目
前言 SpreadJS作为一款性能出众的纯前端电子表格控件,自2015年发布以来,已经被广泛应用于各领域“在线Excel”数据管理项目中.NPM,作为管理Node.js库最有力的手段,解决了很多Nod ...
- 亿级流量场景下,大型缓存架构设计实现【1】---redis篇
*****************开篇介绍**************** -------------------------------------------------------------- ...
- GitHub和75亿美金
如果你是看到了75亿进来的,还在纳闷前面那个github的是个什么,你可以走人了?如果你进来是想看到微软两个字的,请继续. 微软以75亿美金的股票收购Github这件事情,从周六一早我爬山到香山琉璃塔 ...
- web-garden 和 web-farm 有什么不同 ?
相同:都是网络托管系统. 不同: web-garden:是在单个服务器包含许多处理器的设置: web-farm:是使用多个服务器的较大设置.
- 使用mybatis操作AS400数据库
先简单说一下怎么使用[jt400.jar]连接AS400上的DB2数据库. ※ jt400.jar资源,如果有安装AS400客户端的话,参考IBM官网 ※ http://www-01.ibm.com/ ...
- Interrupt中断线程注意点
首先我们要明确,线程中断并不会使线程立即退出,而是发送一个通知,告知目标线程你该退出了,但是后面如何处理,则完全有目标线程自行决定. 这就是和stop()不一样的地方,stop执行后线程会立即终止,这 ...
- 20175229许钰玮 2018-2019-2《Java程序设计》结对编程项目-四则运算 第一周 阶段性总结
20175229许钰玮 2018-2019-2<Java程序设计>结对编程项目-四则运算 第一周 阶段性总结 需求分析 自动生成四则运算题目(加.减.乘.除). 既可以用前缀算法(波兰算法 ...