jvm学习笔记一(垃圾回收算法)
一:垃圾回收机制的原因
java中,当没有对象引用指向原先分配给某个对象的内存时候,该内存就成为了垃圾。JVM的一个系统级线程会自动释放该内存块。垃圾回收意味着程序不再需要的对象是"无用信息",这些信息将被丢弃。当一个对象不再被引用的时候,内存回收它占领的空间,以便空间被后来的新对象使用。事实上,除了释放没用的对象,垃圾回收也可以清除内存记录碎片。由于创建对象和垃圾回收器释放丢弃对象所占的内存空间,内存会出现碎片。碎片是分配给对象的内存块之间的空闲内存洞。碎片整理将所占用的堆内存移到堆的一端,JVM将整理出的内存分配给新的对象。
垃圾回收的优点:垃圾回收能自动释放内存空间,减轻编程的负担。首先,它能使编程效率提高。在没有垃圾回收机制的时候,可能要花许多时间来解决一个难懂的存储器问题。在用Java语言编程的时候,靠垃圾回收机制可大大缩短时间。其次是它保护程序的完整性, 垃圾回收是Java语言安全性策略的一个重要部份。
垃圾回收的缺点:垃圾回收的开销影响程序性能。Java虚拟机必须追踪运行程序中有用的对象,而且最终释放没用的对象。这一个过程需要花费处理器的时间。其次垃圾回收算法的不完备性,早先采用的某些垃圾回收算法就不能保证100%收集到所有的废弃内存。当然随着垃圾回收算法的不断改进以及软硬件运行效率的不断提升,这些问题都可以迎刃而解。
二:垃圾收集的算法分析
1.引用计数器算法:
引用计数法是唯一没有使用根集的垃圾回收的方法,该算法使用引用计数器来区分存活对象和不再使用的对象。
引用计数器算法是给每个对象设置一个计数器,当有地方引用这个对象的时候,计数器+1,当引用失效的时候,计数器-1,当计数器为0的时候,JVM就认为对象不再被使用,是“垃圾”了。
引用计数器实现简单,效率高;但是不能解决循环引用问问题(A对象引用B对象,B对象又引用A对象,但是A,B对象已不被任何其他对象引用),同时每次计数器的增加和减少都带来了很多额外的开销,所以在JDK1.1之后,这个算法已经不再使用了。
2.根搜索方法:
大多数垃圾回收算法使用了根集(root set)这个概念;所谓根集就是正在执行的Java程序可以访问的引用变量的集合(包括局部变量、参数、类变量),程序可以使用引用变量访问对象的属性和调用对象的方法。垃圾回收首先需要确定从根开始哪些是可达的和哪些是不可达的,从根集可达的对象都是活动对象,它们不能作为垃圾被回收,这也包括从根集间接可达的对象。而根集通过任意路径不可达的对象符合垃圾收集的条件,应该被回收。下面介绍几个常用的算法。
2.1 标记—清除算法(Mark-Sweep)
原理:标记—清除算法包括两个阶段:“标记”和“清除”。在标记阶段,确定所有要回收的对象,并做标记。清除阶段紧随标记阶段,将标记阶段确定不可用的对象清除。
缺点:标记—清除算法是基础的收集算法,标记和清除阶段的效率不高,而且清除后回产生大量的不连续空间,这样当程序需要分配大内存对象时,可能无法找到足够的连续空间。
垃圾回收前:

垃圾回收后:

绿色:存活对象 红色:可回收对象 白色:未使用空间
2.2复制算法(Copying)
原理:复制算法是把内存分成大小相等的两块,每次使用其中一块,当垃圾回收的时候,把存活的对象复制到另一块上,然后把这块内存整个清理掉。
缺点:复制算法实现简单,运行效率高,但是由于每次只能使用其中的一半,造成内存的利用率不高。现在的JVM用复制方法收集新生代,由于新生代中大部分对象(98%)都是朝生夕死的,所以两块内存的比例不是1:1(大概是8:1)。
垃圾回收前:
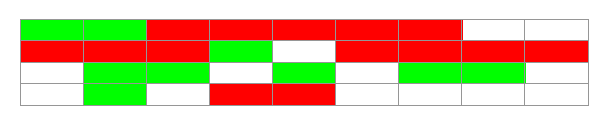
垃圾回收后:

绿色:存活对象 红色:可回收对象 白色:未使用空间
2.3 标记—整理算法(Mark-Compact)
原理:标记—整理算法和标记—清除算法一样,但是标记—整理算法不是把存活对象复制到另一块内存,而是把存活对象往内存的一端移动,然后直接回收边界以外的内存。
标记—整理算法提高了内存的利用率,并且它适合在收集对象存活时间较长的老年代。
垃圾回收前:
垃圾回收后:
绿色:存活对象 红色:可回收对象 白色:未使用空间
上面这四种是最基本的垃圾回收算法,在这四种算法思想之上发展出来其余算法,个人认为更多的是一种内存管理策略,甚至可以看成就是基本算法的组合应用,就像加减乘除与方程式的关系一样,因此将其分开描述。
3.渐进式算法
这类算法一般由基本算法组成,其核心思想是将内存分区域进行管理,在不同的区域和不同的时间采用不同的内存管理策略,从而避免因全系统的垃圾回收导致程序长时间暂停。这类算法一般有以下几种:
3.1.火车算法
这种算法把成熟的内存空间划为固定长度的内存块,算法每次在一个块中单独执行,每一个块属于一个集合。此算法的具体执行步骤较复杂,且没有具体的应用场景,在此不浪费笔墨,有兴趣的同学可以自己研究之。
3.2.分代收集算法
这种算法在sun/oracle公司的Hotspot虚拟机中得到应用,是java程序员需要重点关注的一种算法。
这种算法是通过对对象的生命周期进行分析后得出的,它将堆内存分成了三个部分:年青代,年老代,持久代(相当于方法区)。处于不同生命周期的对象被存储于不同的区域,并使用不同的算法进行回收。这种算法的具体执行细节将会在后续的学习笔记中详细介绍。
关于分代收集 详见 http://www.importnew.com/19255.html
另外需要特别注意的是利用多线程实现的堆垃圾回收技术,这方面资料来源于网络,摘抄如下:
4.多线程实现的堆垃圾回收技术
4.1.串行收集
串行收集使用单线程处理所有垃圾回收工作,因为无需多线程交互,实现容易,而且效率比较高。但是,其局限性也比较明显,即无法使用多处理器的优势,所以此收集适合单处理器机器。当然,此收集器也可以用在小数据量(100M左右)情况下的多处理器机器上。
适用情况:数据量比较小(100M左右);单处理器下并且对响应时间无要求的应用。
缺点:只能用于小型应用。
4.2.并行收集
并行收集使用多线程处理垃圾回收工作,因而速度快,效率高。而且理论上CPU数目越多,越能体现出并行收集器的优势。
适用情况:“对吞吐量有高要求”,多CPU、对应用响应时间无要求的中、大型应用。举例:后台处理、科学计算。
缺点:应用响应时间可能较长 。
4.3.并发收集
相对于串行收集和并行收集而言,前面两个在进行垃圾回收工作时,需要暂停整个运行环境,而只有垃圾回收程序在运行,因此,系统在垃圾回收时会有明显的暂停,而且暂停时间会因为堆越大而越长。
适用情况:“对响应时间有高要求”,多CPU、对应用响应时间有较高要求的中、大型应用。举例:Web服务器/应用服务器、电信交换、集成开发环境。
参考:
http://blog.csdn.net/zsuguangh/article/details/6429592
http://blog.csdn.net/ol_beta/article/details/6791229
https://my.oschina.net/GameKing/blog/198347
jvm学习笔记一(垃圾回收算法)的更多相关文章
- JVM学习(三):垃圾回收算法
局部性原理和分代回收思想 大学学习操作系统或者计算机组成原理的时候都提到一个重要概念,叫局部性原理. 局部性原理是指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小 ...
- JVM学习总结二——垃圾回收算法
昨天总结了JVM内存分区相关的知识,这次我们将来了解下JVM的另一个核心知识点——垃圾回收算法.这一部分其实并不太难,如果对操作系统的内存处理算法有所了解,那么这部分算法其实只看名字就能明白,两者在原 ...
- (转)《深入理解java虚拟机》学习笔记3——垃圾回收算法
Java虚拟机的内存区域中,程序计数器.虚拟机栈和本地方法栈三个区域是线程私有的,随线程生而生,随线程灭而灭:栈中的栈帧随着方法的进入和退出而进行入栈和出栈操作,每个栈帧中分配多少内存基本上是在类结构 ...
- JVM虚拟机学习一:垃圾回收算法总结
1.java虚拟机中涉及到的数据类型 Java虚拟机中,数据类型可以分为两类:基本类型和引用类型. 基本类型的变量保存原始值,即:他代表的值就是数值本身:而引用类型的变量保存引用值.“引用值”代表了某 ...
- JVM内存模型,垃圾回收算法
JVM内存模型总体架构图 程序计数器多线程时,当线程数超过CPU数量或CPU内核数量,线程之间就要根据时间片轮询抢夺CPU时间资源.因此每个线程有要有一个独立的程序计数器,记录下一条要运行的指令.线程 ...
- JVM学习笔记二:垃圾收集算法
垃圾回收要解决的问题: 哪些内存需要回收? 线程私有区域不需要回收,如PC.Stack.Native Stack:Java 堆和方法区需要 什么时候回收? 以后的文章解答 如何回收? 首先进行对象存活 ...
- 轻松学JVM(四)——垃圾回收算法
我们都知道java语言与C语言最大的区别就是内存自动回收,那么JVM是怎么控制内存回收的,这篇文章将介绍JVM垃圾回收的几种算法,从而了解内存回收的基本原理. stop the world 在介绍垃圾 ...
- 深入理解JVM(四)——垃圾回收算法
我们都知道java语言与C语言最大的区别就是内存自动回收,那么JVM是怎么控制内存回收的,这篇文章将介绍JVM垃圾回收的几种算法,从而了解内存回收的基本原理. stop the world 在介绍垃圾 ...
- JVM内存模型及垃圾回收算法
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- JVM学习记录2--垃圾回收算法
首先要明确,垃圾回收管理jvm的堆内存,方法区是堆内存的一部分,所以也是. 而本地方法栈,虚拟机栈,程序计数器随着线程开始而产生,线程的结束而消亡,是不需要垃圾回收的. 1. 判断对象是否可以被回收 ...
随机推荐
- SQL Sever AlwaysOn的数据同步原理
1. SQL Server AlwaysOn数据同步基本工作 AlwaysOn 副本同步需要完成三件事: 1.把主副本上发生的数据变化记录下来. 2.把这些记录传输到各个辅助副本. 3.把数据变化在辅 ...
- activeMQ类别和流程
Point-to-Point (点对点)消息模式开发流程 : 1.生产者(producer)开发流程: 1.1 创建Connection: 根据url,user和password创建一个 ...
- [20190415]关于shared latch(共享栓锁).txt
[20190415]关于shared latch(共享栓锁).txt http://andreynikolaev.wordpress.com/2010/11/17/shared-latch-behav ...
- Oracle 查询权限视图
在Oracle中有很多用于查权限的视图,但很多人在需要查权限时会很困惑,不知道该用哪个视图去查,这里我列出几个常见的用于查权限的视图及其用法: 1DBA_ROLE_PRIVS 该视图主要有以下2个作用 ...
- Linux分页机制之分页机制的实现详解--Linux内存管理(八)
1 linux的分页机制 1.1 四级分页机制 前面我们提到Linux内核仅使用了较少的分段机制,但是却对分页机制的依赖性很强,其使用一种适合32位和64位结构的通用分页模型,该模型使用四级分页机制, ...
- c/c++ 头文件的血案
头文件的血案 不小心在一个头文件里,加了函数的定义,结果导致编译时,提示这个函数被重复定义:( Quote.h #ifndef __QUOTE_H__ #define __QUOTE_H__ #inc ...
- SQLServer之修改UNIQUE约束
使用SSMS数据库管理工具修改UNIQUE约束 1.连接数据库,选择数据表->右键点击->选择设计(或者展开键,选择要修改的键,右键点击,选择修改,后面步骤相同). 2.选择要修改的数据列 ...
- 【Python 23】52周存钱挑战3.0(循环计数for与range)
1.案例描述 按照52周存钱法,存钱人必须在一年52周内,每周递存10元.例如,第一周存10元,第二周存20元,第三周存30元,直到第52周存520元. 记录52周后能存多少钱?即10+20+30+. ...
- 一探究竟:Namenode、SecondaryNamenode、NamenodeHA关系
NameNode与Secondary NameNode 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,其实并不是在这样.文章Sec ...
- e297: write error in swap file
磁盘空间不足: [root@ipservice fountain]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/dock ...